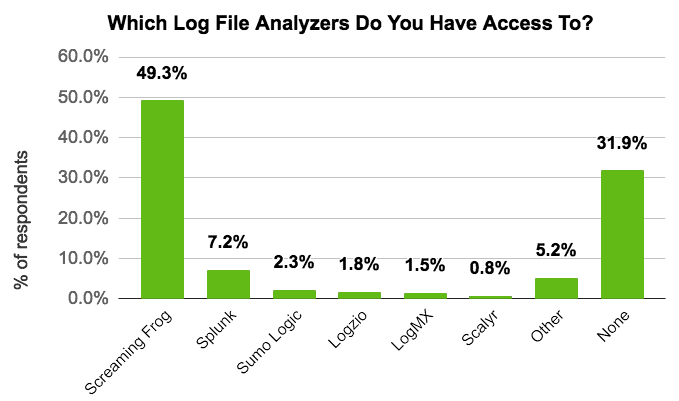
Server log files provide invaluable information about how search engine bots crawl websites, but are often overlooked and underused. A range of log file analyser are available to suit every budget and a recent survey of our user base showed that 68% of 666 respondents already have access to log file data.
As part of our mission to build the world’s most comprehensive website crawler, we have launched our flexible log file integration to help search marketers get the most out of their log file data.
With Lumar, you can now upload summary data from log file analyser tools and integrate it as a crawl source at no extra cost.
Adding Log File Data to Your Crawl
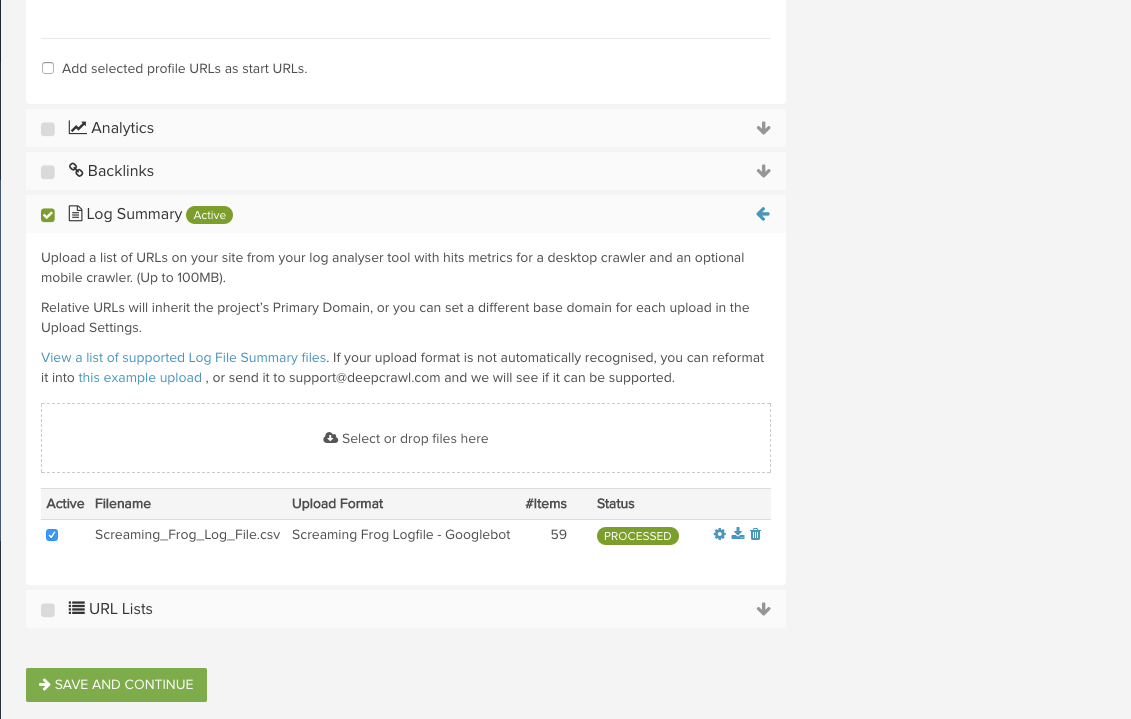
Integrating log file data with Lumar (formerly called DeepCrawl) is a straightforward and painless process. Check out our Supported Uploads Guide to find out how you can upload summary data from some popular log file analyser tools such as Screaming Frog and Splunk.
To begin with, you will need to access your existing log file analyser tool and export summary data for a selected date range. In our Lumar webinar on log file analysis, Eric Enge of Stone Temple recommended working with a month’s worth of server log file data as standard and a week’s worth if the website has a high volume of traffic and bot requests.
Once you’ve exported your summary data, head on over to Lumar and set up a new crawl making sure to add your data in the second stage of the setup. In the event that we don’t support the format outputted by your log file tool, shoot us over a message and we’ll rectify this as quickly as we can.
We strongly recommend adding additional sources like Google Search Console and Analytics data in the crawl set up, which will enable you to get the most out of Lumar. Once you’re happy with your setup, set off the crawl, then sit back and wait for the magic to happen.
How to Put Your Log File Data to Use with Lumar’s Integration
“Sounds great, but how can I use it?” I hear you ask? Well let’s take a deep dive into the nuts and bolts of our game changing update.
After your crawl finalises you’ll have a number of new log file related reports, metrics and graphs at your disposal. Let’s take a look through some of the uses for our latest integration.
Identify Which Pages Are and Aren’t Receiving Requests From Search Engine Bots
Adding log files as a crawl source will let you see which of your pages are and aren’t receiving requests from search engine bots.
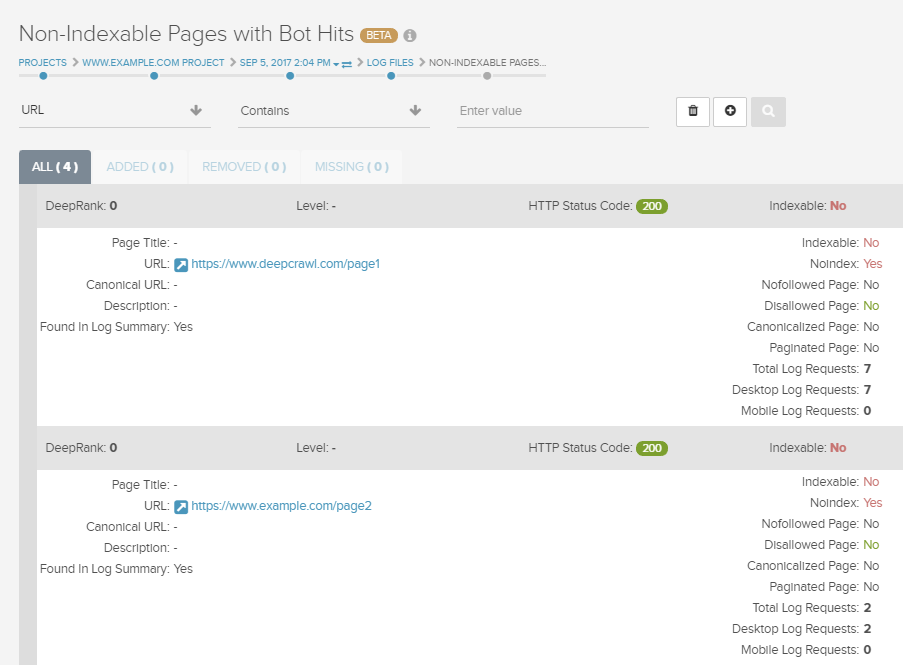
Two reports providing insight into a search engine’s visibility of your site are the Indexable Pages With No Bot Hits and the Non-Indexable Pages With Bot Hits reports. The former can be used to find pages that are identified as indexable to search engines but that aren’t receiving requests from search engine bots. Conversely, the latter report displays pages that shouldn’t be indexed but are receiving requests from search engine bots.
Pages in these reports should be investigated and any issues rectified to ensure that search engines are seeing the pages on your site that you want them to have visibility of and that your crawl budget is being used efficiently.
Understand How Often Pages on Your Site Are Receiving Search Engine Bot Requests
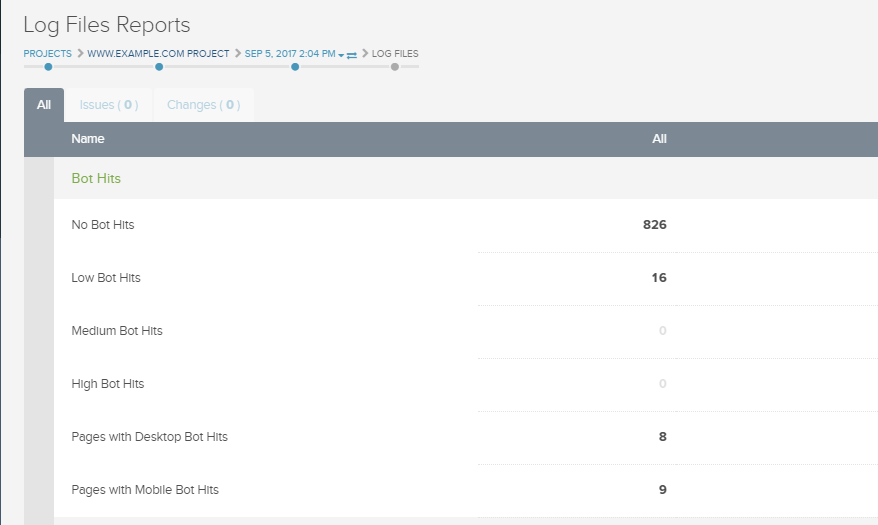
Our latest update delivers insights about how frequently search engine bots are hitting pages on your site with four new reports: High, Medium, Low and No Bot Hits.
You can use these reports to check that your most important and frequently changing pages are being crawled by bots on a regular basis. If this is not the case then you may want to review your site architecture to ensure the pages you want indexed are easy for search engines to find and you may also want to review your use of meta robots tags.
Additionally, our new Crawl Frequency Graph gives an excellent visual overview of the proportion of pages in the four different crawl frequency categories.
Understand the Crawl Frequency of Your Sitemaps
A final crawl frequency related insight you can gain from our latest update, is to check how often your sitemaps are being crawled. This will tell you how often a search engine is checking your site for fresh content and also gives you an indication of the quality of your site according to search engines.
For sitemaps with a low crawl frequency, you will want to check that they don’t contain any non-indexable pages and you may want to consider breaking them down into smaller sitemaps with a separate one which only includes new pages.
Find Out How Different User Agents Crawl Mobile & Desktop Versions of Your Site
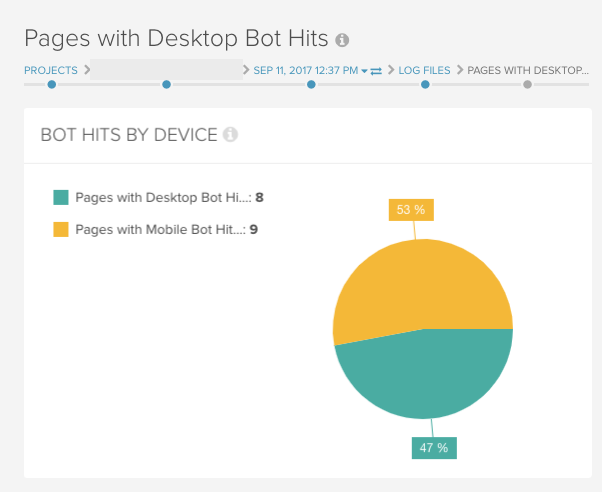
With our log file integration it’s possible to split out mobile and desktop bot requests to your site.
Splitting log file data in this way will help validate your mobile configuration by telling you if the correct user agent is crawling a specific version of your website.
If you have a Separate Mobile site you can use this information to help validate your configuration by checking if your URLs on your mobile site are receiving bot requests from a desktop user agent and vice versa.
Is Your Crawl Budget Being Used Inefficiently?
Lastly, you can use our log file integration to find out where your crawl budget is being used inefficiently. With the addition of log file data, Lumar can now identify URLs receiving attention from bots that shouldn’t be receiving requests such as: redirect chains, 3xx/4xx pages and non-indexable pages.
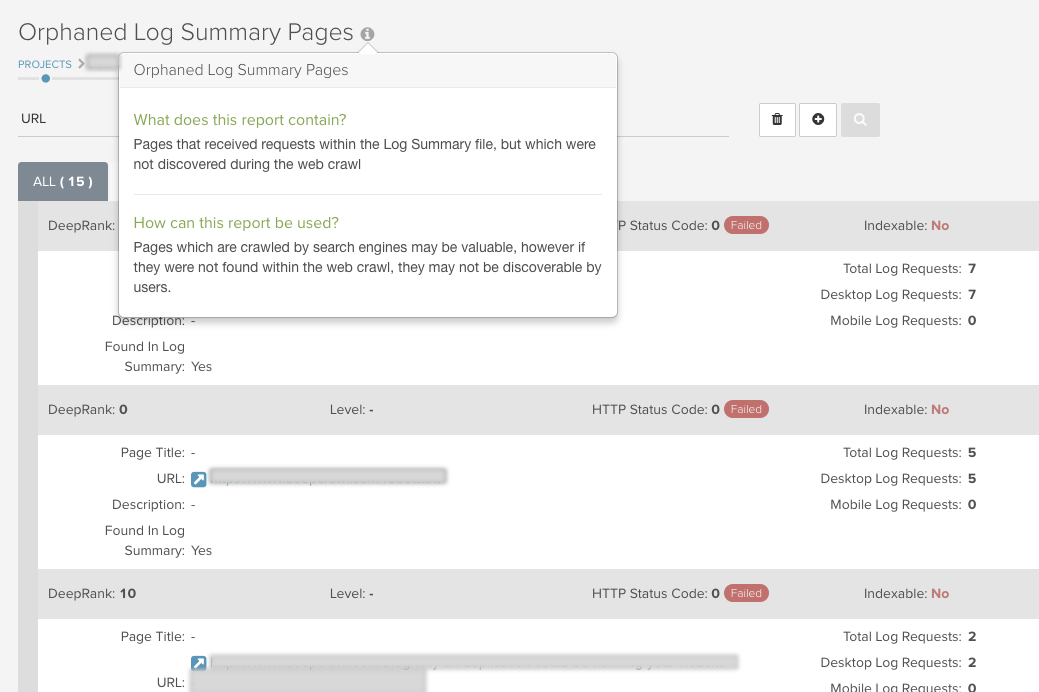
Our Orphaned Log Summary Pages report can also identify orphaned pages (those not linked to in the web crawl) that are receiving bot requests. You may want to reconsider these pages and decide whether you want them indexed and, if so, whether you need to add internal links to these pages.
Enrich Your Crawling Experience With Log File Data
Lumar’s Log File Integration has a plethora of uses, so what are you waiting for? If you’re new to Lumar, reach out and get started today. If you’re no stranger to our crawler, then simply add your log file summary data to your next crawl.
No log file data? No problem! Simply shoot us over a message and our team of knowledgeable consultants will be on hand to advise or answer any questions you may have.
Good luck and we hope you enjoy our latest update.
Get the Most Out of Our Integration with Our Training Webinar