

The Skinny
On the 6th of September 2017, we were humbled to host a webinar with Search Superstar – and CEO of Stone Temple – Eric Enge and our Chief Growth Officer Jon Myers!
If you missed it, or want to revisit (and digest!) all the knowledge bombs they dropped, we’ve broken it down into yummy Search nuggets below. You can also check out the recording we took for you, complete with all the action packed slides.
But firstly, a BIG thanks to Eric for collaborating with us, and sharing incredible Logfiles insights with our community, we all appreciate it!
Enjoyable Log File webinar with @stonetemple & @JonDMyers, it flew by way too fast! So much useful info,looking forward to the recap blog 😀
— Michelle (@Shelliweb) September 6, 2017
A brief history of logfiles
Jon: Back in the days, running your Logfiles were the ‘be all end all’, prior to things like crawlers! But we’ve seen a drop-off in the usage of Logfiles, I think it’s something we need to treat and use in the right way going forward…
Eric: Logfiles are truly loved, by me! But definitely agree the usage has dropped off in recent years. Tagging pages to tell when people are visiting them.
The JS based approach
Eric: A Javascript based way of tagging pages (so you can tell when people visit them like Google Analytics tags) results in some oddities that don’t go so well.
JS based solutions aren’t really good and can’t track search engine crawlers, as search crawlers know not to to execute the analytics JS because it slows them down.
This means…you can’t see how often Google crawls page X, Y or Z.
JS analytics are also really bad at telling time on site accurately, as JS-based tracking has no way of knowing how long you’ve been on that page or closed the browser or simply left.

BUT…you can use log files to get better data on this!
The Log File Based Approach
Eric: everytime your server gets pinged a logfile keeps a log, and tracks that data
But..
Eric: On the interweb there’s lots of caching (ISPs cached locally or in browsers etc) which means pages get reloaded without actually pinging your web server and those are accesses to your pages that logfiles can’t track.
Moral of the story is, there are strengths and weaknesses to both a JS or a Logfiles approach.
How do we throw shade at crawlers?
Eric: If people are crawling your site, and you want to stop them, block them!
- TIP: this isn’t something you can do with JS frameworks but you can with Logfiles 🙂
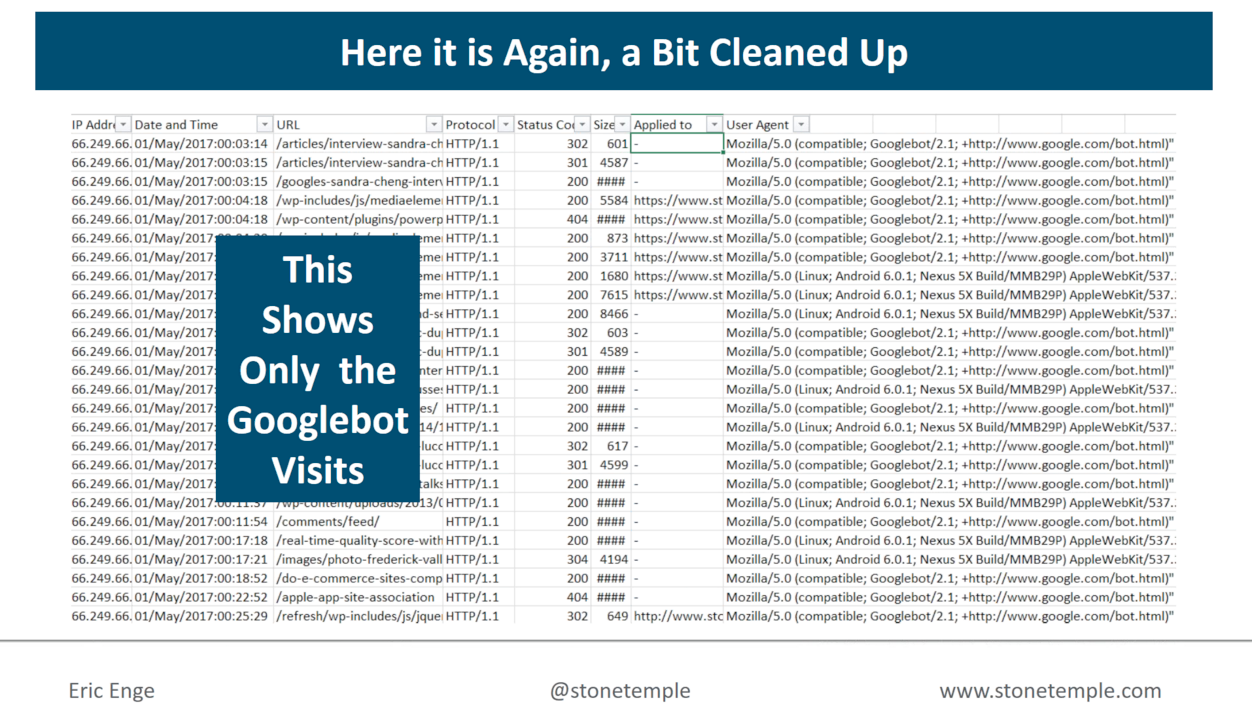
What about shady people who visit my site, and aren’t who they say they are?
Eric: This brings up an interesting question, what possible reason do people have to do that?
The chances are pretty good that it’s somebody crawling my site and trying to make sure that I don’t block them. So they’re people that are crawling my site, saying they’re Googlebot, and…they’re not!
How do you handle this at Stone Temple?
Eric: We like to block out badbots!
- TIP: that’s something you can do with Logfiles 🙂
It’s also useful to check out your top crawled pages (like your homepage).

What can we take away from the image above?
Eric: The /feed is ranking highly, BUT…one of the /feed’s is redundant.
- TIP: Spending time sorting through your Logfiles is good practice!
We can also see that the 2nd and 3rd most crawled pages on Stone Temple are AMP pages.
This! https://t.co/oUFuifMyTc
— Aleyda Solis (@aleyda) September 6, 2017
Which we’re sure is not only music to Aleyda’s ears, but also (shout out) to Distilled‘s Jono Alderson, who has recently graced stages like Search Elite, The Inbounder and imparted wisdom on site speed, and getting AMPed!
What else can we deduce from Stone Temple’s AMP pages?
Eric: This is a leading clue on just how emphasis Google puts on AMP! As 4 out of 5 of the most crawled pages are the AMP versions of the pages, this speaks towards the importance of AM.
Though it doesn’t give a ranking boost..they (Google) sure are putting a lot of weight on it based on their crawling patterns.
- TIP: Stone Temple is about to drop a study on this, keep your ears peeled!
But back to Logfiles…
Eric was able to see that 88% of pages were non-deep content/non-post pages, through Stone Temple’s on-site Logfiles analysis.
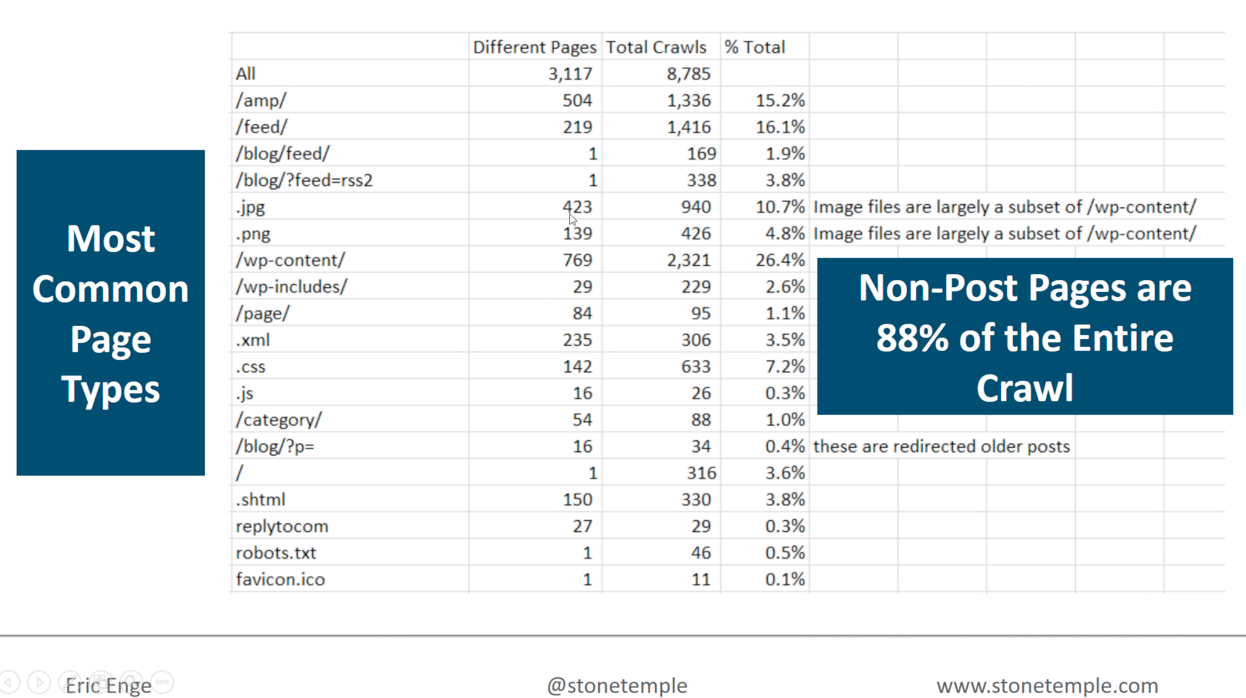
But why should I care?
Eric: If I understand where sites are being crawled, I can understand what Google prioritises, and then focus on what I can do to my site architecture to benefit from this. For example Google getting fresh content/crawling our feeds more frequently or our AMP versions of pages etc.
“If I understand where Google crawls my site, I understand their priorities & can focus my site architecture on that” @stonetemple #logfiles https://t.co/4RreEnE9VQ
— DeepCrawl (@DeepCrawl) September 6, 2017
Final Thoughts
Jon: Is Google taking the easy way out, in terms of the data they see out there on the web?
Eric: Yeah I mean, they kinda have to! I can’t confirm on how they settled primarily on crawling the feed pages, but I can see that they know our site content doesn’t change dramatically unlike our blog, so if they can get pinged as soon as there’s changes here (so they can crawl those pages), gee that makes their job easier!
Jon: Most people don’t realise how massive a task it is for them to attempt crawling the whole web (not that they do)
Google is actually crawling less than 1% of the actual web!
It’s a game of how you get or train Google to access your site. Is it a case of how bots can crawl sitemaps, or getting Google to crawl the right pages at the right time. But if you’re not a big publisher, what does that mean for you?
‘It’s a game of how you train Google to access your site! Excluding big publishers what does that mean for you?’ @JonDMyers on #logfiles https://t.co/0OZKwlijDI
— DeepCrawl (@DeepCrawl) September 6, 2017
Food for thought!

Once again a BIG thank you to Eric Enge for joining us, and to everyone who tuned in (cheers Taylor!)
.@JonDMyers and @stonetemple talking about analyzing log files for #SEO in this @DeepCrawl webinar! It is getting wild in here!
— Taylor (@TVYLORTOMITV) September 6, 2017
As well as everyone who is reading / sharing this recap 🙂
p.s. Did you know you can upload log file data from any analyser into DeepCrawl? Or that we integrated with Splunk?



