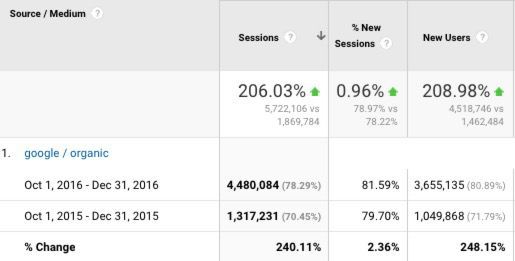
When you run, manage or own a business web site, it’s important to know whether that site is performing at peak capacity in terms of usability and functionality. Since organic search is a core referral resource for visitors who ideally are well matched to the site’s offerings, it’s critical to understand that search engines are a unique type of site visitor (user). While these are not human visitors, search algorithms are designed to attempt to emulate human experience through formulaic processes. And we need a way to make use of that understanding.
Proper Tools for Maximizing Visibility and Indexation
If you don’t have the proper tools for testing a site from that perspective, you’re potentially going to miss critical weaknesses, or fail to recognize missed opportunities in maximizing site visibility and indexation. This is why I use Deepcrawl (now Lumar) in my forensic site audits.
No single tool is enough to get the complete understanding necessary at the strategic, forensic level. Many tools exist where each has its own value for different aspects of the audit process, and each has its own limitations. This is the nature of reality – no single tool can be all things all the time to all its users. However in my experience, performing sixty to eighty audits a year for the past several years, I’ve come to find Deepcrawl one of the best tools in my arsenal.
Invaluable Insight Discovery
Note – it would be impractical for me to cover every single thing I love about Deepcrawl, and all that it can do, in a single article. There are just so many things I love about it, especially since they came out with the big version 2 upgrade. So, instead, I’m going to cover some of my favorite features.
The first reason I love Deepcrawl, is insight discovery, where the knowledge gained is invaluable to helping identify weaknesses at the technical level. When an industry tool is well crafted, and you know how to read the data provided, the insights you can gain begin to form the road map to a stronger presence organically.
When you first set up a project in Deepcrawl, you need to enter the name of the domain you want to crawl. Personally, I enter the root domain name only, without adding in the http or https prefix, and without the www, even if I already know the live URL structure includes that. I do this, because Deepcrawl immediately checks all four of the most typical scenarios:
https://domain.com
https://www.domain.com
https://domain.com
https://www.domain.com
In near instant time, you then get back a visual chart that shows you whether only one of those results in a “200” status code (as it should), whether only “302” temporary redirects are set up, or what’s going on across these four.
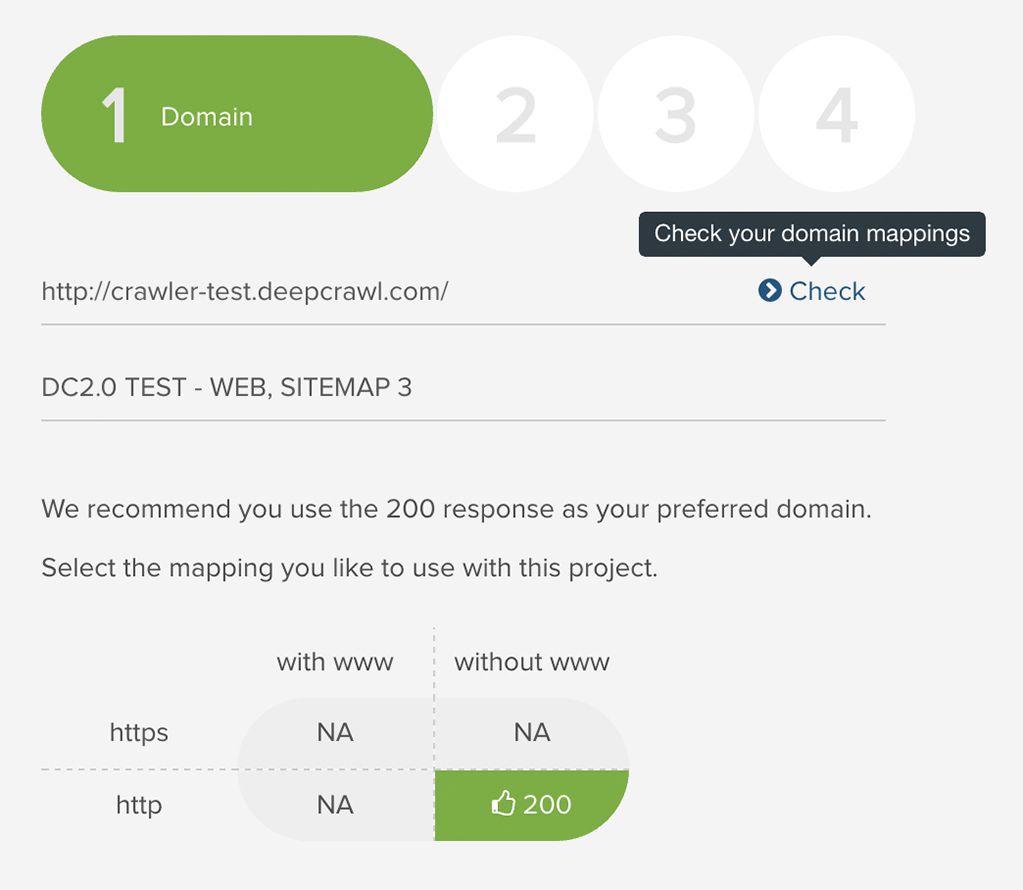
So even before the real crawl effort begins across the entire site, you already know when an important indexation factor has a conflict that needs attention.
The Main Dashboard
Once you initiate the crawl, and have chosen all the many options as for how you want the system to crawl the site you’re auditing, it’s going to do its thing. Depending on the size of the site, this can take some time. Especially if you’ve chosen to throttle the speed of the crawl (a helpful feature when you’re somebody like me who can crawl hundreds of thousands of URLs for a single audit).
When it’s done, and you go to the main dashboard, right away you’re presented with data that’s invaluable in beginning to see where potential serious issues exist.
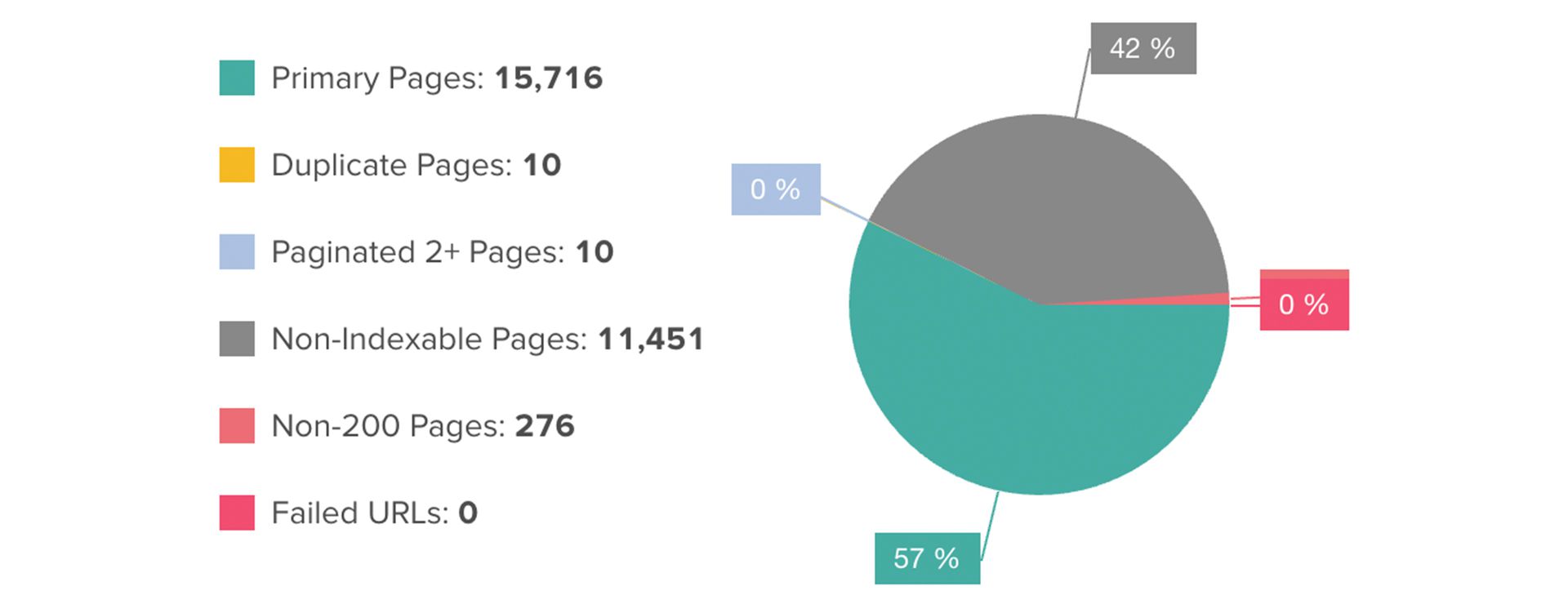
This is a handy snapshot of some of the most important issues that exist technically for the site you’re auditing.
Obviously, with a forensic audit, I want to look at all the issues. When I do, and once I’ve considered everything, I may determine ‘this particular issue is not as high a priority as these other issues’, yet at least I now know about it at that point, and I can always flag it for a future work phase or sprint.
Metrics That Matter to Me
I love that Deepcrawl allows me to customize the metrics I care about. If I think any one issue type’s default threshold is too high or too low, I can go in and change that one-time, or if I’m running multiple audits, I can use settings I configured in a previous crawl. This is invaluable, given how every site has its own unique needs, challenges, and limitations. Maybe the site I’m auditing happens to be a large scale enterprise site on lightning fast servers, and I don’t mind the total size, in kilobytes, for any one page, being bigger than the default threshold.
Perhaps I’ve found, in my own audit work, that a particular site doesn’t need to have as much content per page as most sites, or conversely, due to the competitiveness of a given industry, I know that on average, this site needs to have more content per page. Deepcrawl lets me set the thresholds that fits my needs.
Individual Issue Reports
Another thing I appreciate with Deepcrawl is the details provided when drilling down into one of the listed issues. In this example, it’s the “Max Links” report.
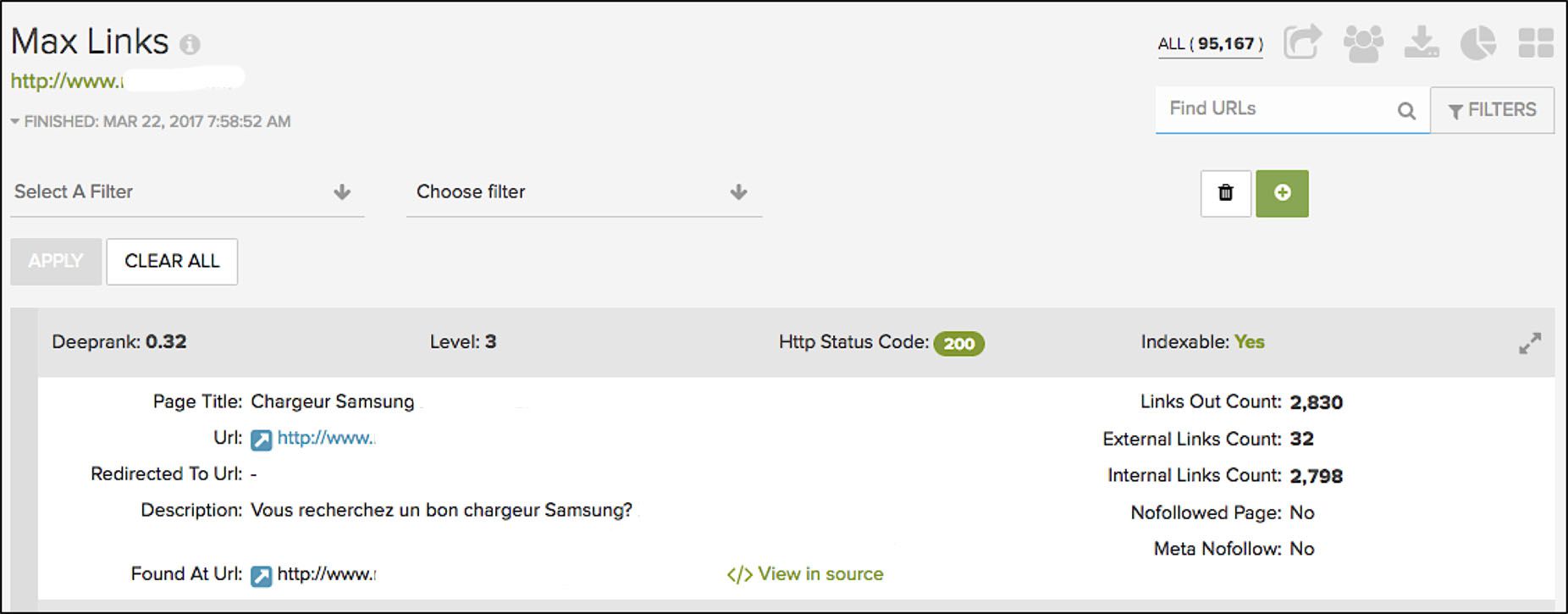
Whoa – look at that – this one page, has over two thousand links within its code. That’s crazy!
Finding Unknown Issues
Another awesome aspect of Deepcrawl is how the system identifies conflicts or weaknesses you might not even have considered a potential problem before. Take, for example, conflicts between individual page URL, the canonical tag for that URL, and the OpenGraph URL assigned to that page.

While I don’t reveal the actual URLs in my screen-shots (client NDA requirements), this screen-shot is from the OG/Canonical Conflict report. The Canonical URL for this particular page is set to be the same as this page itself. Yet the URL referenced in the OpenGraph URL field is different.
Going Beyond the Ordinary
Why does that matter? If I want this page indexed, and if the canonical tag reinforces that signal, why would I want a different URL to be the one social networks identify as being worthy for their needs?
Sure, there may be situations where a different OpenGraph URL is intentional. Yet more often than not, it’s an invalid signal.
Let’s go further though – into the realm of speculation. For the sake of “what if”. What if search algorithms are, or eventually become, sophisticated enough to make use of the OpenGraph URL and OpenGraph Title in helping bring clarity to the otherwise determined understanding their algorithms have for a given page?
In that scenario, would you want to inject a confusion point for those algorithms here? I wouldn’t. And I don’t assume they’re not already at least looking at that information, and maybe even weighing it to at least some minor degree.
Since I am all about consistency of signals across multiple data points, this is why I love that Deepcrawl already includes the OG/Canonical conflicts as one of its reports!
Audit Tasking with Precision
Another great feature I have found with Deepcrawl since they revamped the system and reporting layout, is how you can not only see the list of all the different issue types found on a single screen, but how, in the report view, you can focus in on one single issue group type.
This can be invaluable when you want to think about how each of the issues found specific to one aspect of SEO, are doing – as their own subset of considerations. And if you are responsible for addressing one set of issue types, or you assign someone to just work on those issue types, using this dashboard allows narrow group focus to take place effortlessly.
So Much More
As I mentioned at the beginning of this post, it would be impractical for me to think I could reasonably cover all the things I appreciate about, and have come to rely upon Deepcrawl for over the past couple years. I do want to say, however, that I could not be as successful as I have become, especially when we’re talking about enterprise SEO or even independent sites, when they involve tens to hundreds of thousands, or millions of pages. So if you have been sitting on the fence about whether this is a tool worth having, let me assure you – if you care about technical factors for SEO, and you really do want to maximize a site’s presence organically on scale, Deepcrawl is worth it.