

Pagination is one of the least understood topics in technical SEO, and further research is needed to better understand how to manage and optimize pagination to make it search friendly.
To get a better understanding of the common pitfalls in making pagination search friendly, we did a small crawl experiment and audited different web designs on 150 sites from the Alexa top 500 sites on the web.
For a deeper dive into how to manage pagination post rel=next and prev, read our pagination SEO best practice guide and the watch video of Adam’s Brighton SEO talk on the topic.
The top 500 sites on the web
Our team analysed 150 websites and used 50 sites from each of the following categories within the Alex top 500:
- Shopping
- News publishers
- Forums
These categories were chosen because in the original Google pagination documents, they highlight that these are the most common site types to have these designs. For each website, we chose a category or forum discussion at random. The only criteria was that the category on each site must have some form of pagination.
Crawling the Alexa top 500 websites
Once we identified the 150 websites and the categories we wanted to investigate, we then used Lumar to crawl each of the websites. For each one, we focused our crawling on specific categories with pagination, and only included pagination URLs. This allowed us to quickly identify the state of the pagination design.
When crawling each website, the following settings were used in the advanced settings in Lumar:
- User-agent: Googlebot Smartphone
- IP: United States
- JavaScript rendering: Disabled
When crawling websites, we quickly realised that sites in the Alexa top 500 used separate mobile URLs. We had to alter the advance settings to account for this and used the Mobile site setting in Lumar. This helped us identify mobile alternate URLs and to see if mobile sites were properly configured (we’ll mention what we found in another post around mobile and pagination).
Once that the websites were crawled, we analysed the data in Lumar and compared the state of each website’s pagination to the search friendly criteria.
Search friendly pagination benchmark
Our team created a benchmark for search friendly pagination using technical criteria based on Google’s official Infinite scroll search friendly recommendations and Introduction to Indexing documents. We had used the indicate pagination documentation, but this was removed during our testing.
The criteria for pagination to be categorized as search friendly was as follows:
- Paginated components have unique URLs (e.g. /category-page?page=2).
- Paginated components are discoverable through crawlable links on paginated pages.
- Paginated pages within the series are indexable.
- Indexable paginated pages do not contain duplicate content (based on Lumar).
When creating this criteria, we feared it was too basic and planned to make it more advanced, however, testing revealed many websites did not pass a lot of the fundamentals. The positives of testing!
Also, the original the search friendly criteria included rel=“next” and rel=“prev”, however, Google has announced that it no longer uses it as an indexing signal. This was later confirmed by Google Webmaster Trends Analyst John Mueller on Twitter.
We don’t use link-rel-next/prev at all.
— John (@JohnMu) March 21, 2019
For further information on what this means for SEO, read our technical SEO guide to pagination.
In terms of our benchmark criteria however, it did not really impact our data. We simply removed the rel=next and prev point from our pagination search-friendly criteria; everything else was kept the same.
The results of testing pagination
When analysing the data, we were surprised by some of the results and the state of certain pagination design types. We have summarised the results below, and have also broken down issues so that technical SEOs or site owners can get actionable insights from the results.
Overall results
Our overall results found that 65% of pagination were not search-friendly, based on our criteria.
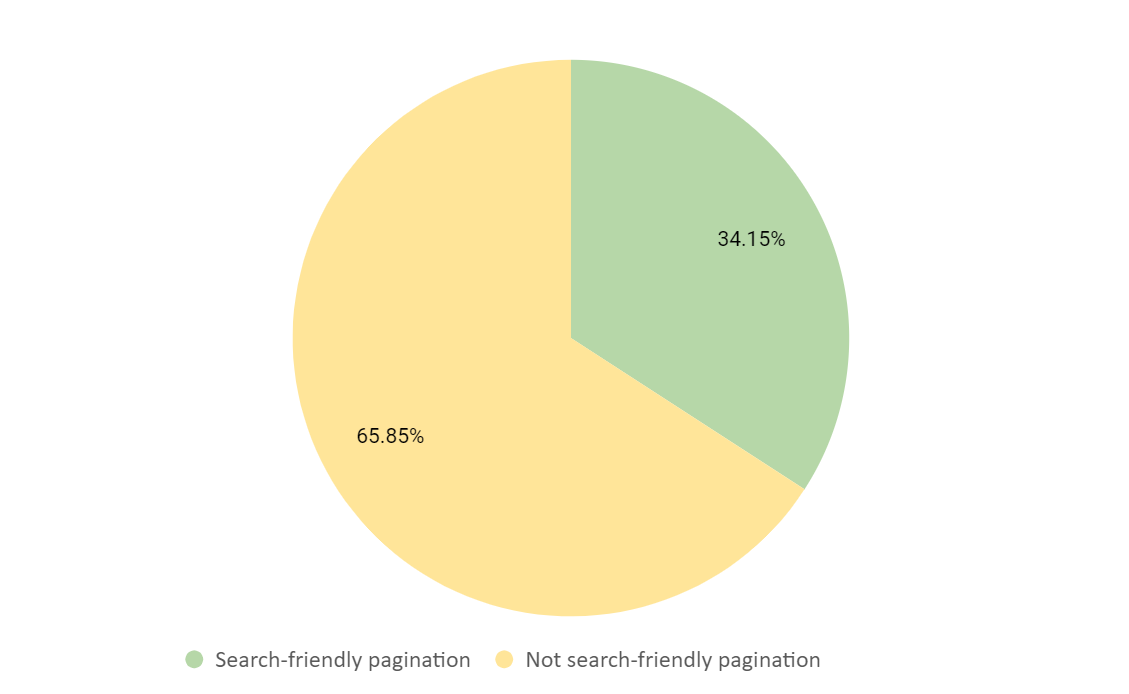
The number of websites that did not pass the search friendly criteria was a surprise, as the technical criteria was based on rudimentary SEO practices.
As well as checking if each website’s pagination was search friendly, each type of web design was also recorded. From our analysis, we found that there were three main types of web design:
- Pagination
- Infinite Scroll
- Load more + lazy load
Each of these we felt fall under pagination because they all divide content across multiple pages. As we recorded each type of design, we noted that certain ones were more popular across all three categories.
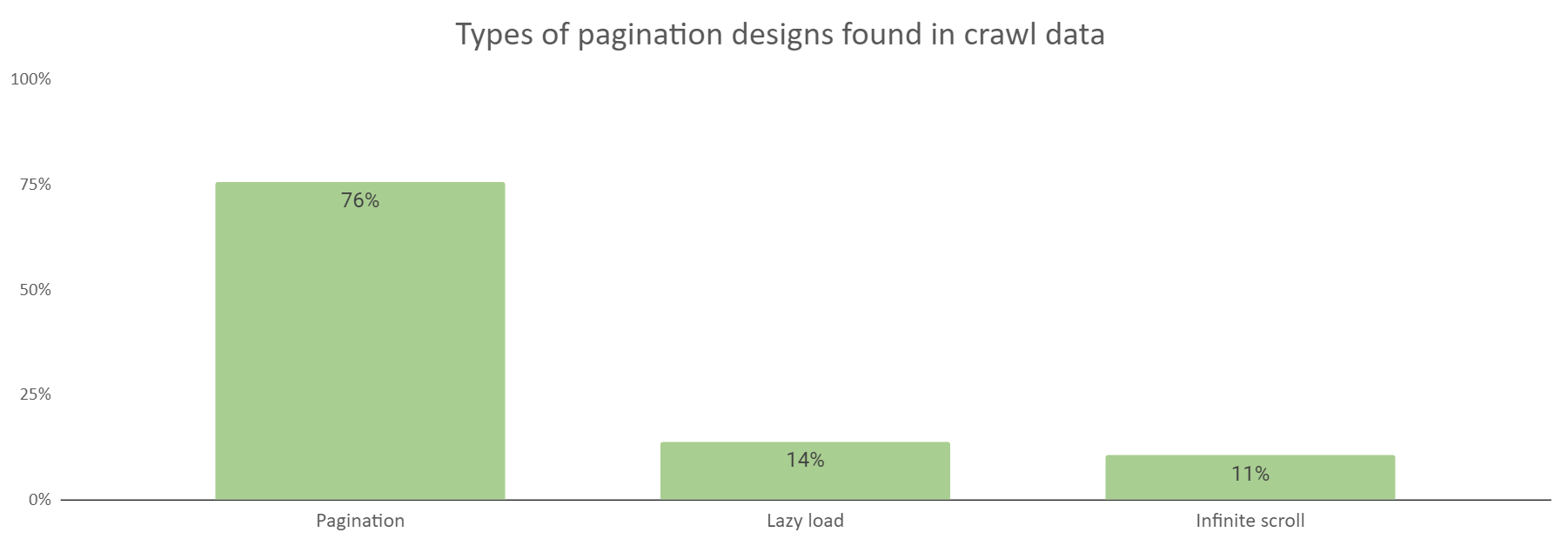
As you can see from the above graph, the results of this analysis found that pagination was the most popular type of technique to divide lists of articles or products across multiple pages. Load more + lazy load and infinite scroll (single page web designs) were also used to display content across multiple pages.
When segmenting search-friendliness by web design types, we found that pagination was the most search friendly of the three types.
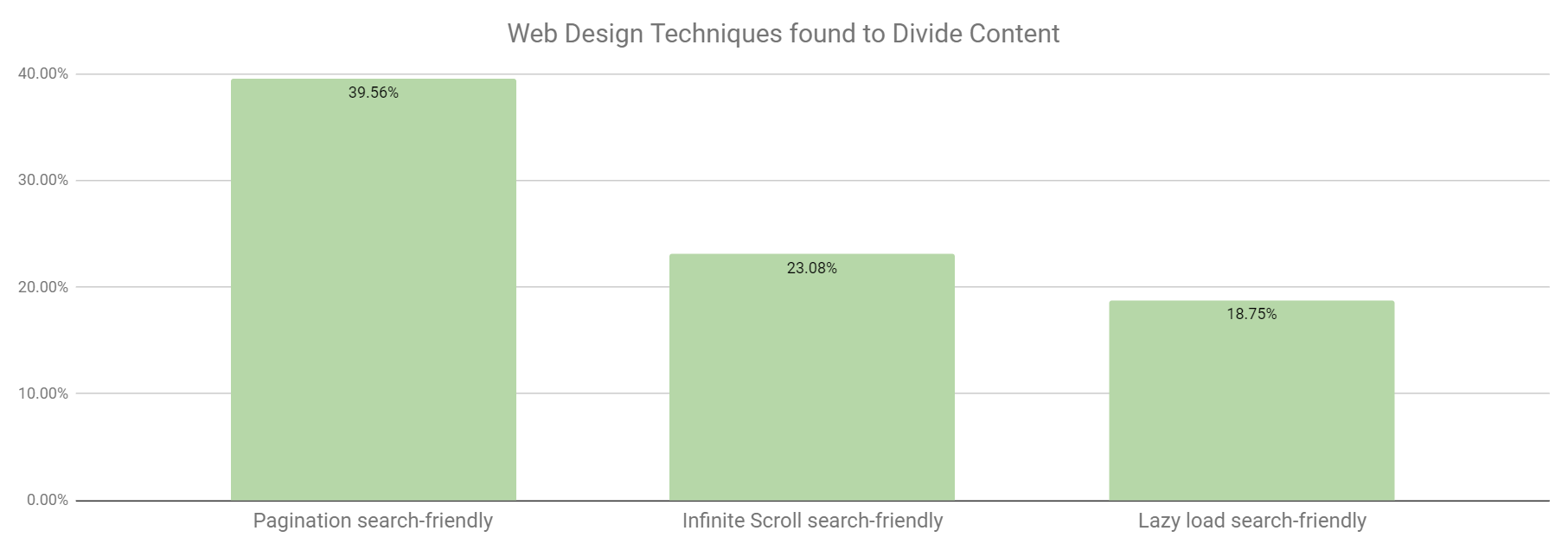
However, as you can see from the graph below, both the single page web designs were the least search friendly based on the criteria.
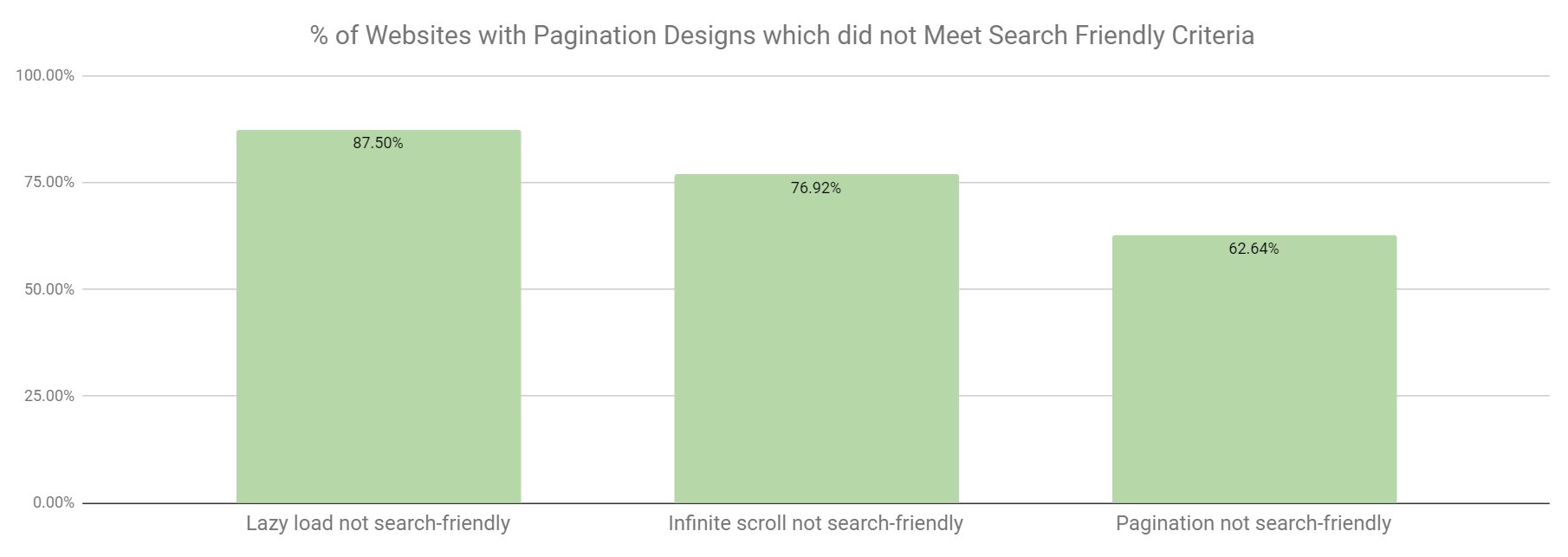
Based on these results, it is important to drill into the crawl data for different types of web design to understand why certain types are not search friendly. This not only helps our team better understand common SEO errors* with pagination and infinite scroll, but it also helps anyone with these types of designs to understand how to avoid common SEO pitfalls.
*Note: These will not be all the SEO issues, but these are the most common issues we found in our data.
Pagination
Pagination is the process of dividing lists of articles or products across multiple page components. It is a common and widely used technique to divide lists of articles or products into a digestible format.
We will now go through each of the search friendly criteria and highlight common SEO issues that caused many websites to fall below our standards.
Paginated components with unique URLs
Google requires URLs to be assigned to pages for content to be crawled and indexed. Without a URL, content or links associated with each paginated component cannot be discovered, crawled or indexed.
When analysing the websites with pagination, we found that only 5% did not match unique URLs to paginated components.
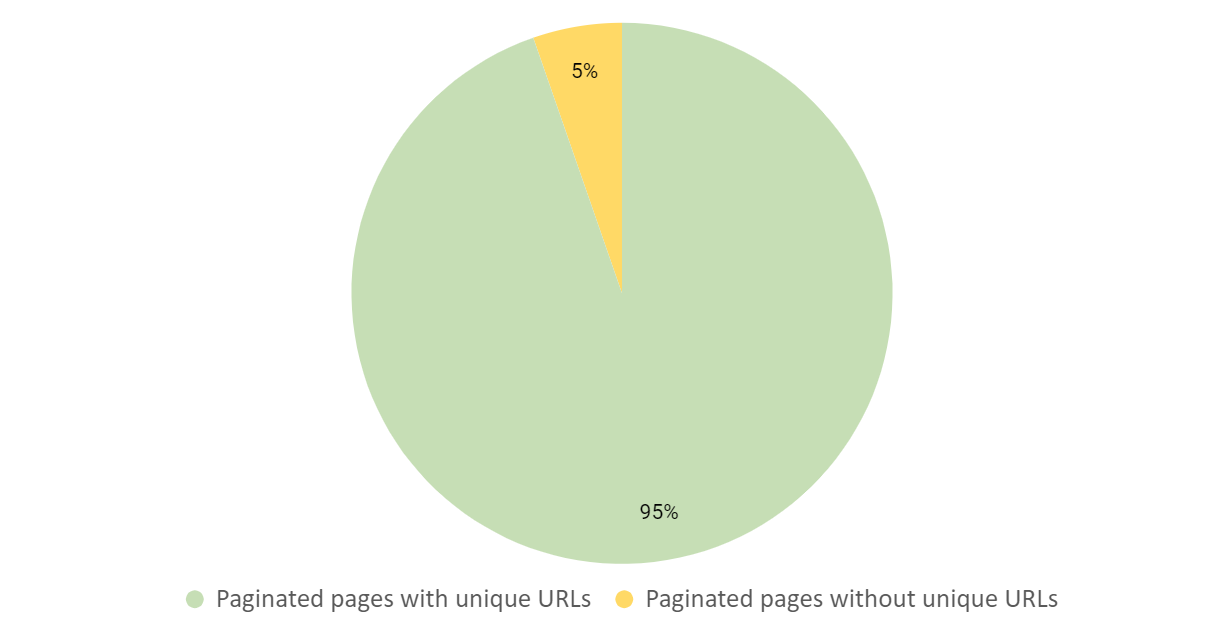
For the handful of websites which did not pass this criterion, a common issue was that the paginated page content was mapped to fragment identifiers (#).
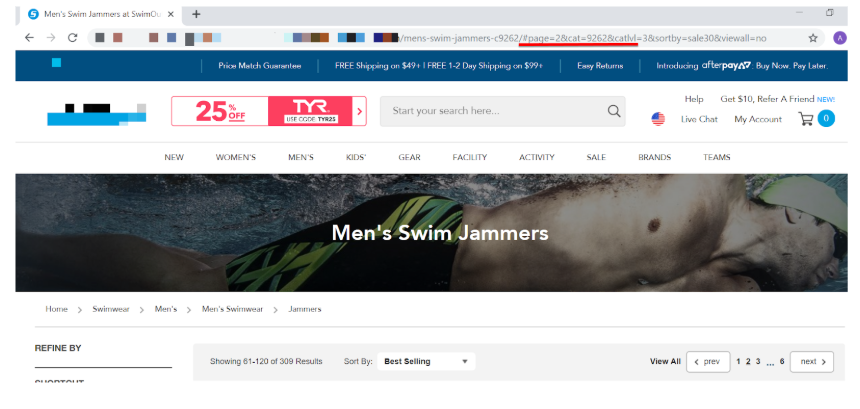
Google has stated that any content that comes after a fragment identifier (#) cannot be crawled or indexed. When mapping paginated components to URLs, make sure that they use absolute URLs and not fragment identifiers to load paginated content.
- Absolute URL – https://www.example.com/product-category/page=2
- Fragment identifier (#) – https://www.example.com/product-category#page=2
Actions:
- Make sure that paginated components have unique URLs (static or dynamic URLs).
- Use a browser to inspect if the paginated URL has a fragment identifier (#).
Dynamic vs Static URLs
When analysing the 150 websites, our team noticed that many sites use different types of URLs for pagination:
- Static URL – https://www.example.com/product-category/page2/
- Dynamic (parameter) URL – https://www.example.com/product-category?page=2
Research found that there is no advantage of using one over the other for ranking or crawling purposes, However, Googlebot does seem to guess and crawl URL patterns based on dynamic URLs based on desktop research (something to test in the future). So, if technical SEOs wanted Googlebot to discover pagination patterns through guessing, then it would be better to use dynamic URLs (parameters).
However, research found that using dynamic URLs can also cause crawling traps. When guessing the paginated URL patterns on a sample set of websites, we found that there were live duplicate dynamic pages which were not part of the current paginated series.

Here is an example of the unique URLs allocated to paginated components in the pagination above:
/clothing/dresses/ – first page in the series
/clothing/dresses/?page=2 – page 2
/clothing/dresses/?page=3 – page 3
/clothing/dresses/?page=4 – page 4
If you manually add parameters based on the URL pattern, then the CMS continues to load live empty pages:
/clothing/dresses/ ?page=5 – page 5
/clothing/dresses/ ?page=6 – page 6
/clothing/dresses/?page=7 – page 7
If Googlebot decided to crawl this URL pattern, then it may crawl and infinite number of paginated pages, which would waste crawl budget.
If you are using dynamic URLs, make sure that your website is not configured to produce a 200 HTTP status code for any dynamic paginated pages which are not part of the current series. If these pages are kept live, then Google might crawl and index duplicate or empty paginated pages.
Actions:
- If you want Google to understand pagination URL patterns on the website, then use dynamic URLs, so it can pick up parameter URL patterns.
- If you do use dynamic URLs, make sure that your website is configured (set to 4xx) so that any unwanted paginated URLs are not wasting crawl budget.
Crawlable links
For Google to efficiently crawl paginated pages it needs to find anchor links with href attributes. It is critical in getting these pages crawled and indexed, especially with the recent announcement that the search engine no longer supports rel=“next” and rel=“prev” as an indexing signal.
With crawlable internal links being so important, it came as a surprise when we analysed the Alexa top sites on the web and found that 56% of sites with pagination did not properly use anchor links.
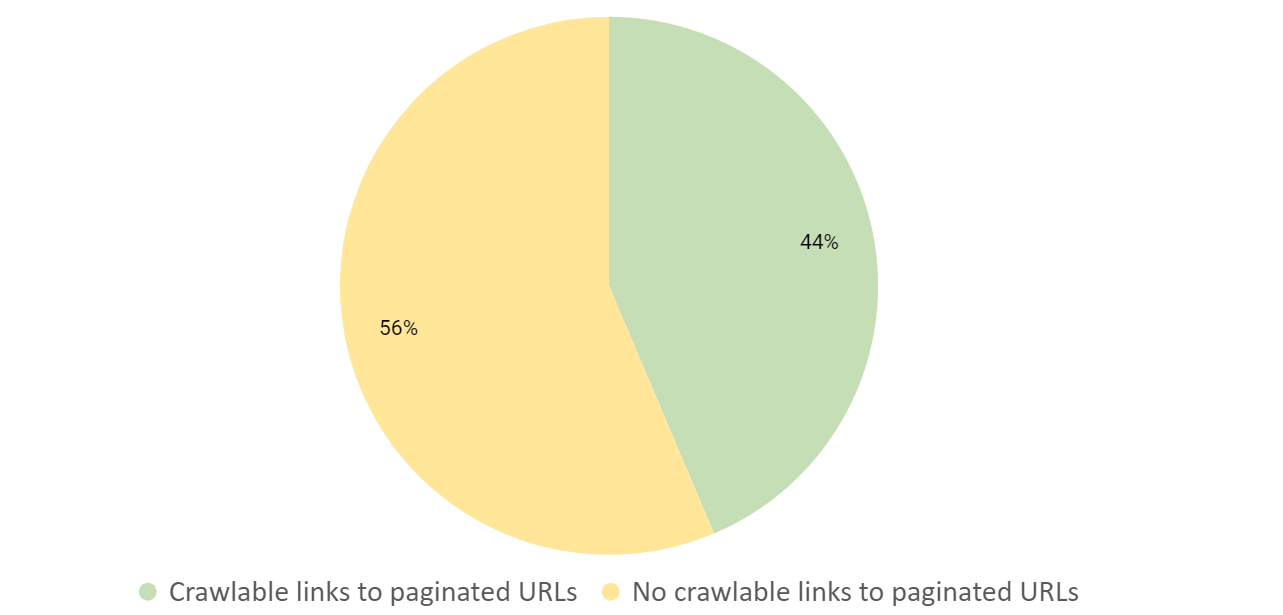
This result was concerning, especially as Google and other search engines rely heavily on internal linking within their crawling and indexing quality checks. To understand why a lot of websites did not meet this criteria, and other common issues, we dug into the pagination crawl data.
Missing anchor links
One of the most common issues we found was that links within the design do not use <a href=””> links in the source code or document object model (DOM) to link to paginated pages.
When checking the pagination links on the website, we found that they did not include anchor links. Instead, the website had been built so that content on paginated components were loaded via JavaScript.
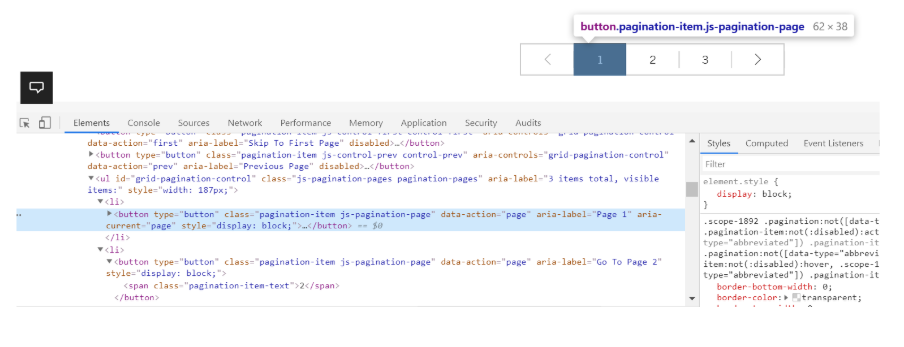
When crawling the first page of pagination, which used JavaScript in Lumar, none of the pages which were linked to on the website were found.
This is because even with JavaScript rendering enabled, both Lumar and Google require anchor links with href attributes to discover and crawl pages.
Actions:
- When linking to paginated pages, make sure they are using anchor links with a h attribute within the link element in the source code.
- Test if paginated pages include anchor links and href attribute using third-party crawlers like Lumar (which is designed to follow anchor links with an href attribute).
- A quick way of identifying if Google can discover links without JavaScript, is to right click on any page and view the page source (Ctrl + U) and try to find (Ctrl + F) the paginated URLs in the raw HTML.
href attributes using scripts not URLs
As well as finding missing anchor links, our team also discovered many websites had used event scripts (javascript:) instead of absolute or relative URLs in the href attribute.
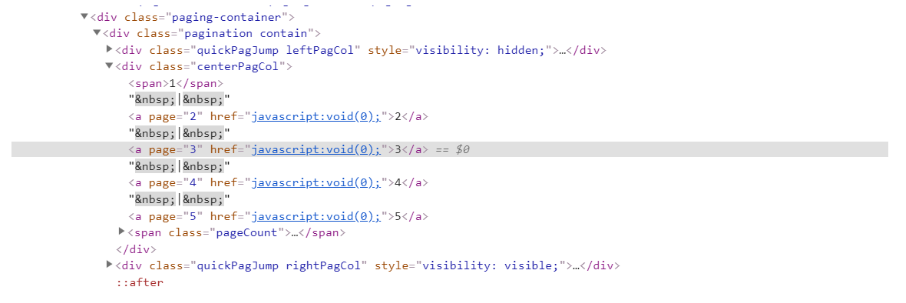

This usually happens when developers want to have a link on the page, or make it look like an anchor link, but do not want to provide a URL. Instead, they use an event script which is triggered when the link is clicked, and paginated content is loaded to users.
The reason this is a crawlable link issue is that search engines require absolute or relative URLs in href attribute to crawl pages. Without the <a href> link search engines like Google will not crawl or discover internal links to paginated pages.
Again, just like the missing anchor links issue, it seems that a lot of websites with this problem are using JavaScript to load content to users.
Actions:
- Review paginated links using Inspect Element tab in Google Chrome to identify how developers have linked to paginated pages.
- Use anchor links that use relative or absolute URLs in the href attribute to make sure that search engines can discover links to paginated pages.
Paginated URLs blocked using /robots.txt
Finally, another common crawlability issue we discovered was that paginated URLs were blocked in the robots.txt file.
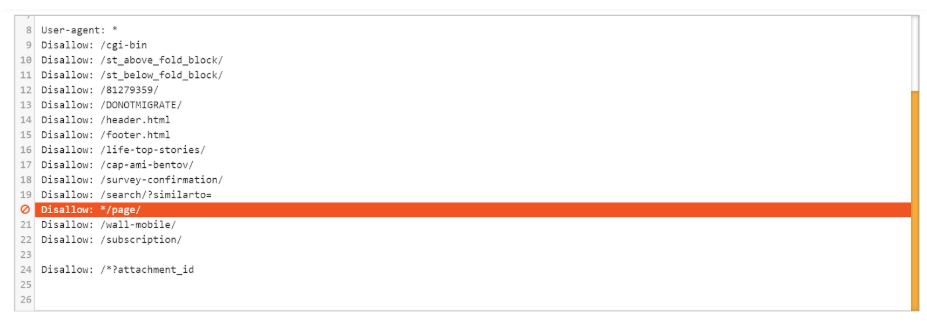
If a URL is blocked in the /robots.txt file, then search engines cannot crawl the page and discover content or outbound links from that page. Many websites might want to block unimportant paginated pages, but if paginated pages are the only access points for traffic or revenue driving pages, then they are an important page of the website architecture.
Businesses and website owners should make sure that important paginated URLs are not accidently blocked while also trying to block other dynamic or static URLs on the website.
Actions:
- Use the Google Search Console robots.txt Tester to test if paginated URLs can be crawled by Googlebot.
- Always test if paginated URLs have been accidently blocked when disallowing a new parameter URL using the /robots.txt file.
Indexable paginated pages
Paginated pages are important access points for search engines to discover and crawl deeper level pages. The reason that paginated pages should be indexed is due to how Google’s indexing system works, and what it (potentially) does when pages are excluded from the index.
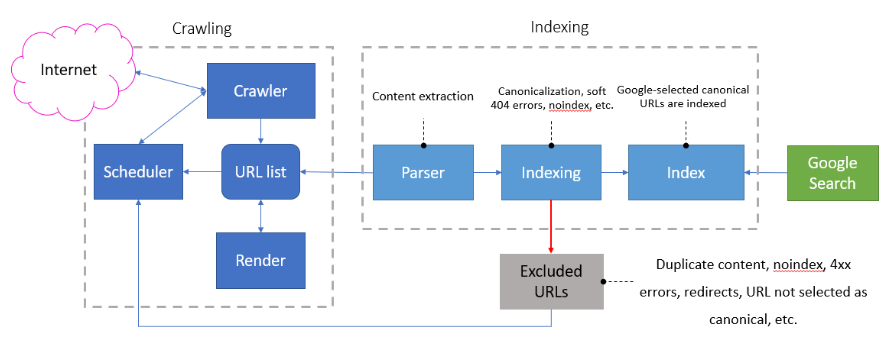
The diagram above is taken from a combination of slides from the Google I/O 2018 conference, as well as some good old-fashioned conversations with John at SMX Munich.
All URLs on the web which are crawled by Google go through the same selection process before a page is indexed (see diagram above). This selection process is called canonicalization, which is part of the indexing process, and it happens even if a site owner does not specify a canonical page. Any page that passes this selection process is called a Google-selected canonical URL. These canonical pages are used for:
- The main source to evaluate page content.
- The main source to evaluate page quality.
- The main page to display in search results.
For pages that are excluded from the index, it has been suggested by John Mueller, a Webmaster Trends Analyst at Google, that excluded pages from the index are not used by Google and that it does not follow links on those pages.
“If we see the noindex there for longer than we think this this page really doesn’t want to be used in search so we will remove it completely. And then we won’t follow the links anyway. So, in noindex and follow is essentially kind of the same as a noindex, nofollow.” – John Mueller, Webmaster Trends Analyst at Google, Google Webmaster Hangout 15 Dec 2017
John also mentioned in discussions on Twitter after this announcement that Google will eventually drop all signals from an excluded page in its index.
“Nothing has changed there in a while (at least afaik); if we end up dropping a page from the index, we end up dropping everything from it. Noindex pages are sometimes soft-404s, which are like 404s.” – John Mueller, Webmaster Trends Analyst at Google, Twitter 28 December 2017
These comments do suggest that if paginated pages are excluded from Google’s index (regardless of the method) for a long period of time, then any paginated pages excluded would cause Google to eventually drop all outbound signals on those pages (internal links and content on the pages).
So, as already mentioned one of the most important functions of pagination on a website is to create access points for search engine crawlers to discover deeper level pages (products, articles, etc.).
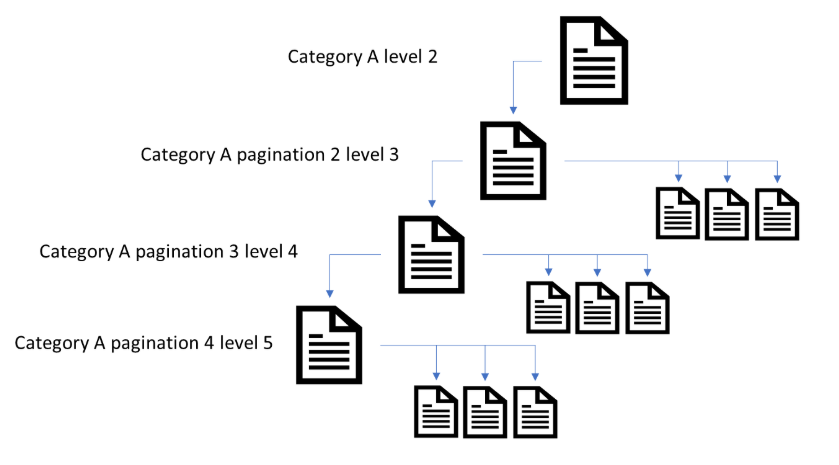
A quick test on Alexa websites, excluding paginated URLs from a web crawl, found that for certain websites, 30-50% of pages were reliant on pagination to be found by web crawlers through internal linking. An example of one these websites is below.
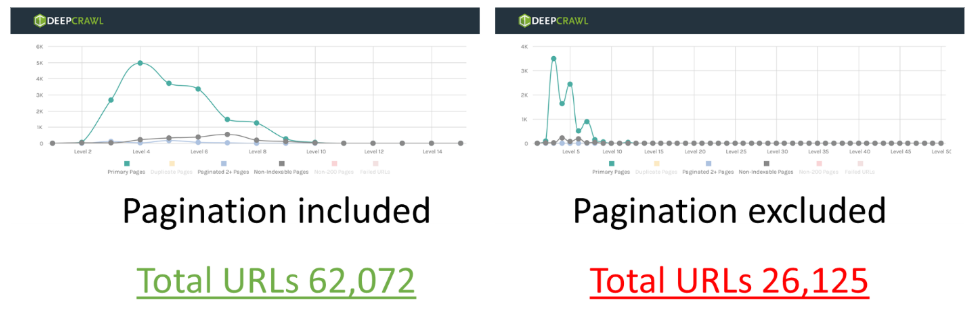
If businesses or site owners are excluding paginated URLs from Google’s index (using rel=canonical or noindex), then this could mean that Google will remove outbound signals (internal links) to deeper-level pages which are reliant on internal links from pagination.
In addition, if Google evaluates content based on the canonical pages indexed, then important signals like the link graph could also be based on Google-selected canonical URLs. If this theory is correct, then the deeper-level pages linked to from excluded paginated pages could effectively be orphaned and lose their ability to rank in search results.
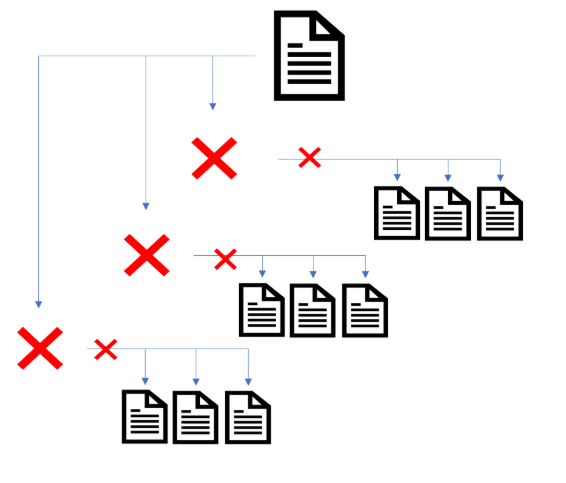
To make sure internal links on paginated pages are followed, then it is important to ensure that they are indexed in Google.
When checking websites with pagination, we found that nearly 20% of paginated pages had been made non-indexable.
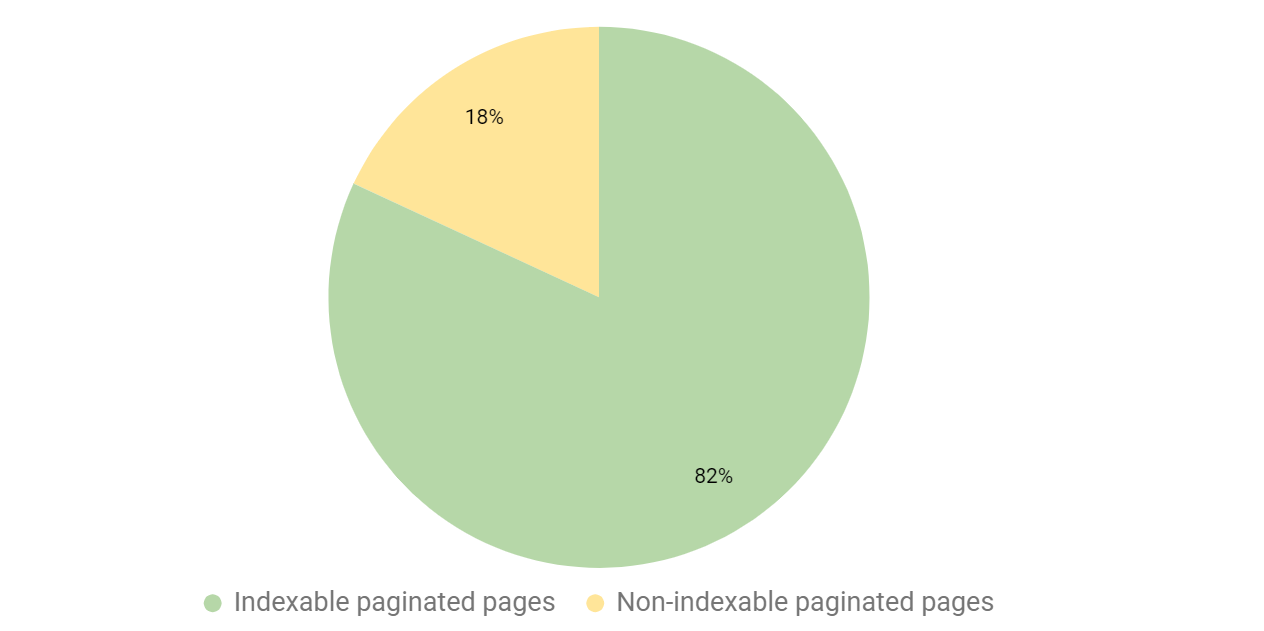
Again, we dug into the data to understand how site owners were causing their paginated pages to be non-indexable.
Canonicalized pages
The common pattern of why paginated pages were non-indexable is that websites used rel=canonical tag on paginated pages pointing back to the first page in the series.
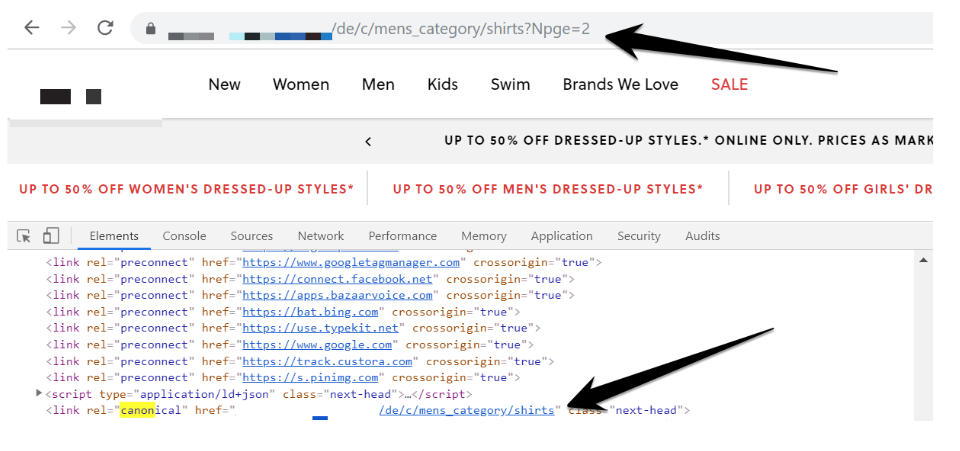
As already mentioned, this will cause Google to exclude 2+ paginated pages from its index, and will mean that Google will not follow or count internal links to deeper level pages.
Actions:
- Use third-party crawlers to detect noindex or canonicalized paginated pages on the website.
- Inspect the paginated page URL index status in Google’s index using the URL Inspection tool.
- Monitor the indexability of paginated pages using the Index Coverage Status report.
Duplicate content
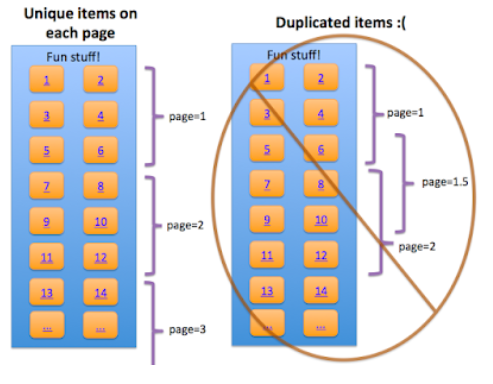
The final factor is that paginated pages, that a site owner wants indexed, should contain unique content. The purpose of pagination is to be a list of articles or products which users can navigate. For paginated page content to be unique, it needs to contain unique list items and not overlap any list items.
When testing pagination, we found that 3% of paginated pages contained duplicate content (duplicate content detected by Lumar).
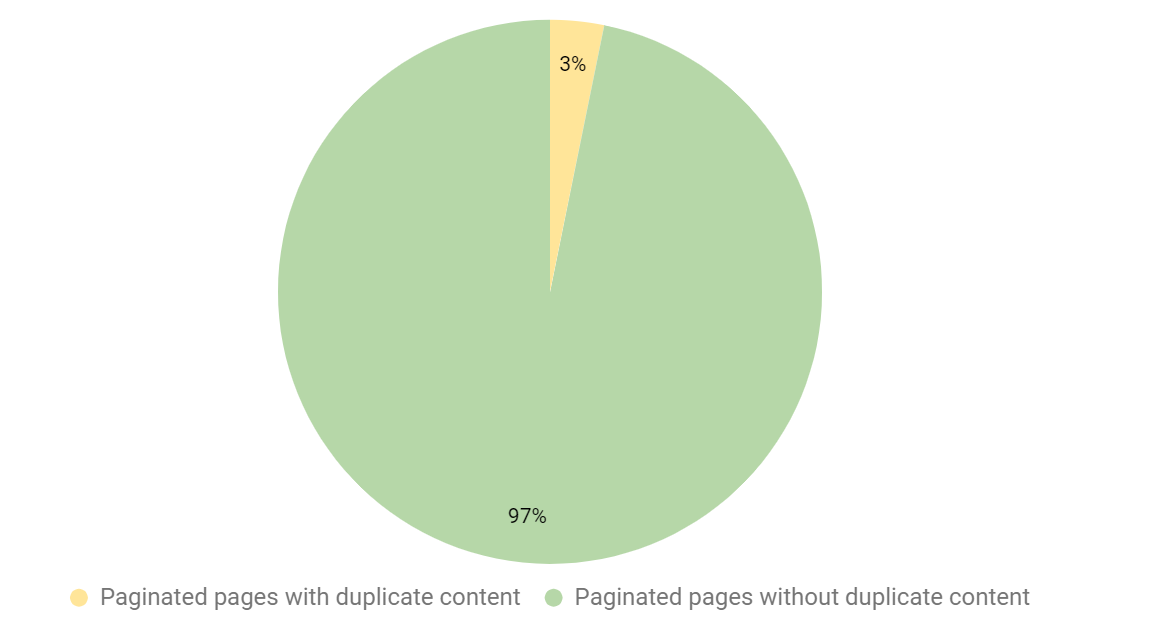
When digging into the data, duplicate content was one criterion that a lot of websites passed. This is great, as paginated pages will not be accidently excluded in Google’s index because the content is duplicated.
For those paginated pages that did have duplicate content, it appears that the content management system (CMS) created duplicates of the primary paginated URL.
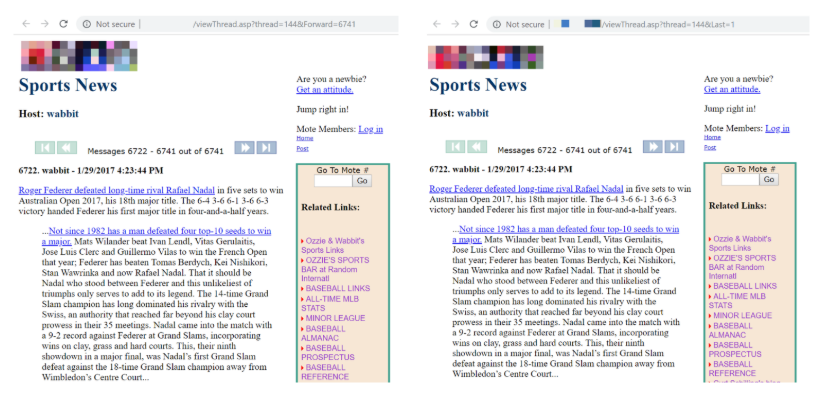
The issue appeared to be that the website owner had not managed the parameters on their website and a canonical URL has not been specified with the rel=canonical tag element. This is an example of where current SEO best practice of managing facets and filters on pagination still needs to be applied. Otherwise, Googlebot could waste crawl budget on duplicate content and could even choose to index duplicate content over the preferred URL.
Actions:
- Use third-party tools like Lumar to discover duplicate paginated pages on a website.
- Use duplicate or facet navigation SEO best practices to indicate the preferred paginated pages which should be used by Google as the canonical URL.
Load more + ‘lazy load’
Lazy load + ‘load more’ is a web design technique that divides lists of articles or products across multiple components, but defers loading of paginated components until they are loaded by users using a click event.
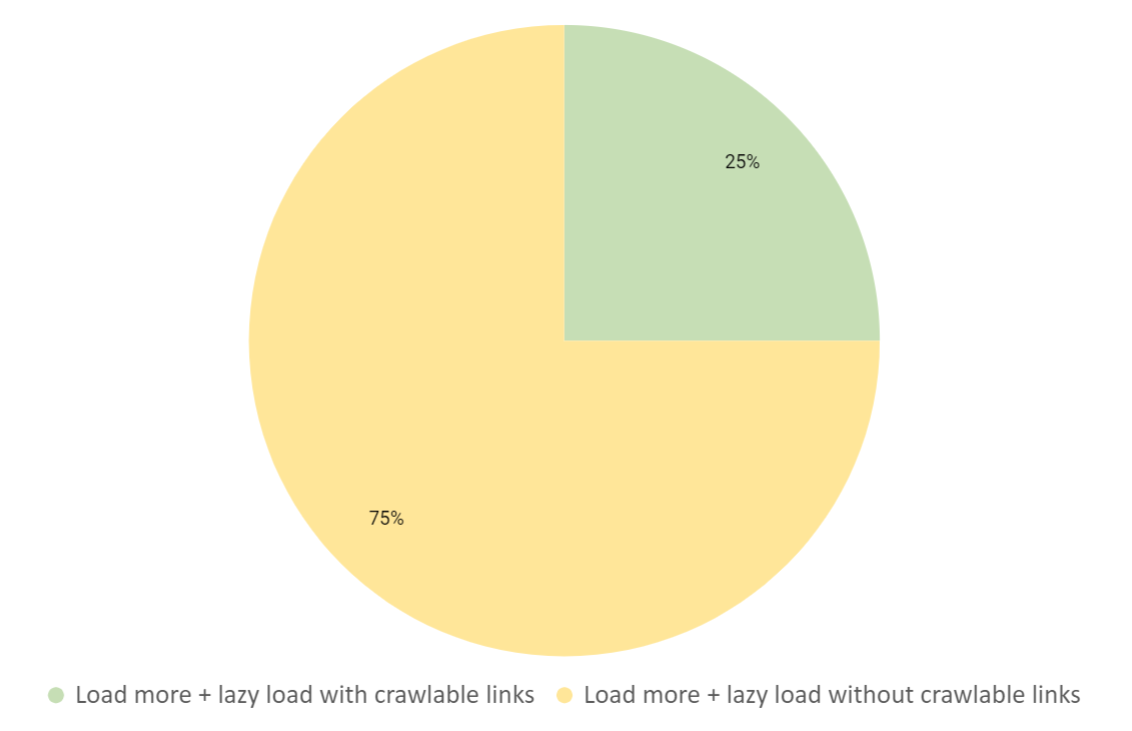
This web design technique to divide content across multiple pages was the second most popular in our crawl data. When comparing each website to the criteria, we found that 85% of the websites using load more + lazy load were not meeting the basic benchmarks.
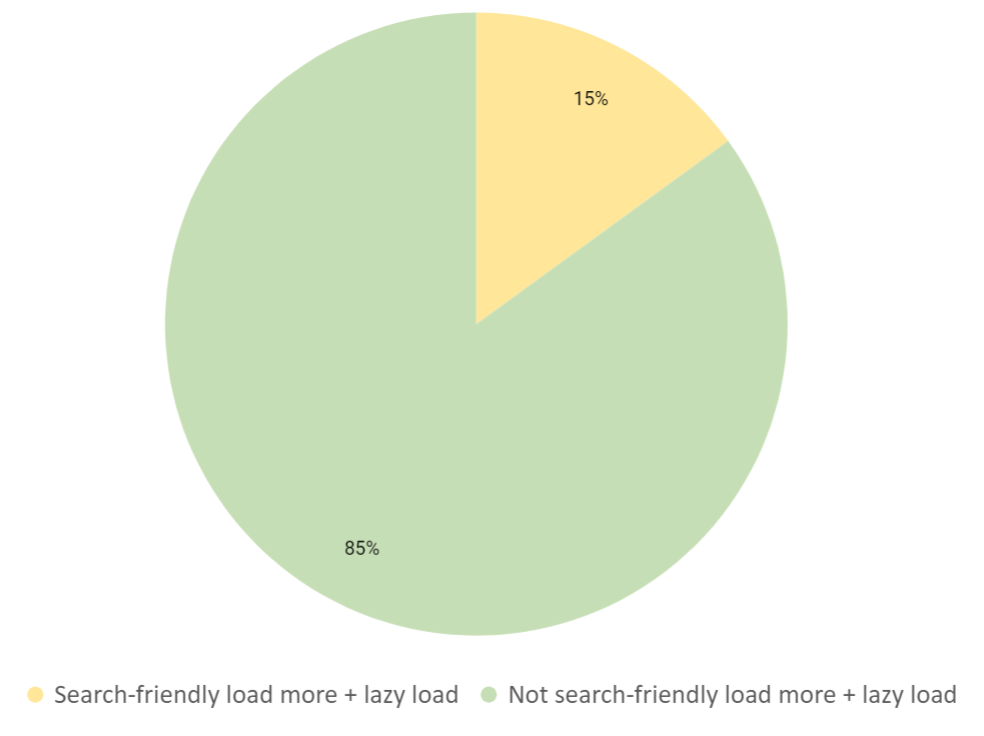
This was an alarming figure when analysing the crawl data. As we went through each criteria, it was clear that a lot of websites with the load more design are missing the basic elements to make paginated pages discoverable.
Paginated components with unique URLs
One of the fundamental issues with lazy load design was that the components which were loaded via an event click did not have a unique URL assigned to them. As already mentioned, search engines like Google require that pages have a URL so they can include it in their index.
Unfortunately, there is no official Google documentation on how to make load more + lazy load search friendly. However, we can use the recommendations in the infinite scroll documentation as both require an event script to load multiple components.
Based on this documentation, each component loaded using a script event should be mapped to a unique URL, so that search engines can crawl and index the content on the components.
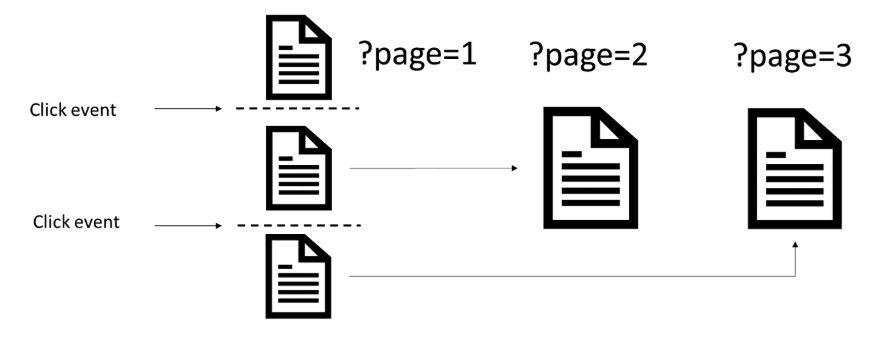
Unfortunately, not a lot of websites implemented this best practice, however, there were a handful of websites that mapped URLs paginated components.
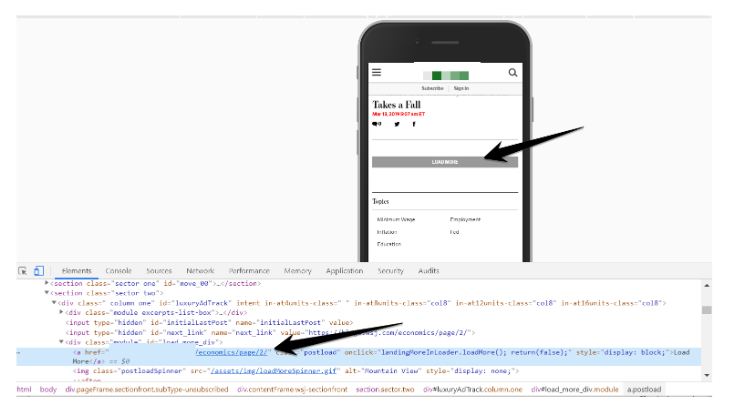
Although some websites mapped URLs to paginated pages, they did not use the pushState method in the history API to change the URL in the browser, as they loaded a new component in the series. This is a recommendation in the infinite scroll documentation (although it is not critical for crawling or indexing).
Websites that use the load more + lazy load design should make sure paginated components are mapped to unique URLs in the content management system (CMS) or web app.
Actions:
- When developing a load more + lazy load web design for pagination, make sure the components within that series are mapped to unique URLs (static or dynamic).
- Use the pushState History API to update the URL in the browser when a user loads a new component with a click event.
Crawlable links
As we have already mentioned for Google to discover and crawl links to pages, there must be crawlable links on paginated components. Internal linking is also important for search engines to discover deeper level pages on the website.
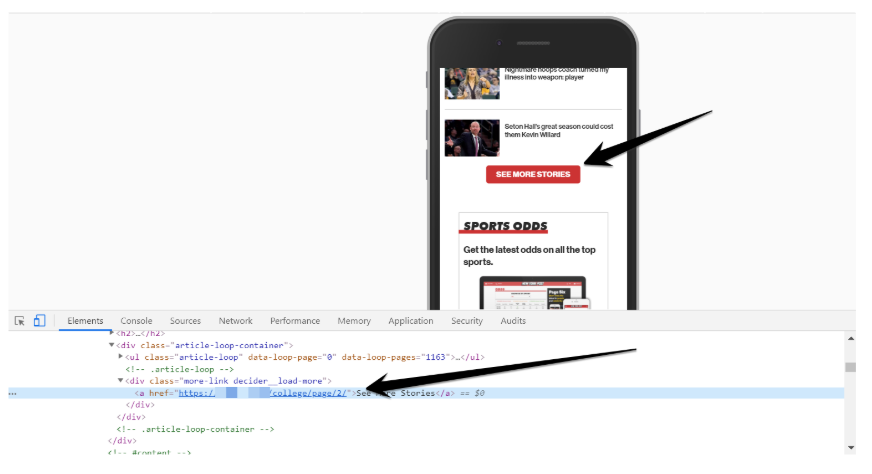
So, it is disappointing to see that so many of these web design types do not have crawlable links to other paginated pages in the series.
However, we can learn from those who have implemented crawlable links in the design, as they have included an anchor link and href tag in the load more <div> element.
This means that when we crawl the load more + lazy load design, our crawler discovers all the paginated pages in the series, as well as the internal links on the paginated components.
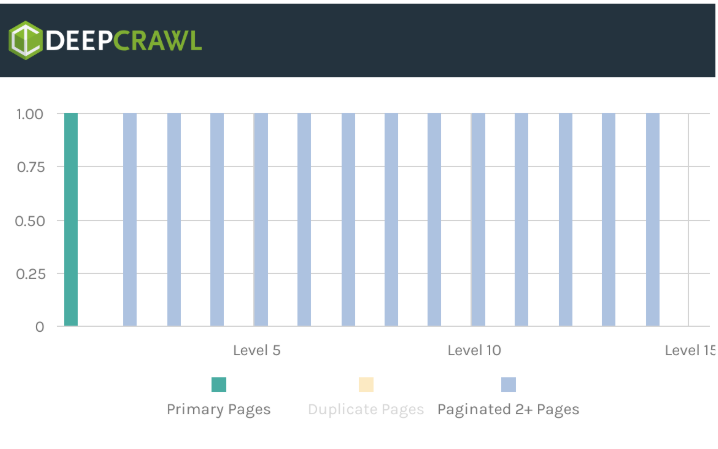
Actions:
- Add anchor links with href attributes to load “load more” elements, to allow search engines to discover and crawl paginated pages.
- Make sure the anchor link uses relative or absolute URLs in the href attribute (not using event scripts), so that search engine crawlers can discover paginated pages.
Indexable paginated pages
It was difficult to highlight issues with non-indexable pages, as many web designs of this type did not even have unique URLs mapped to paginated pages.
Just like pagination, unique paginated components on the load more web design should still be allowed to be indexed. Any paginated pages which are excluded from the index will mean Google won’t use content or follow internal links on the component pages.
Please ensure that search engines can crawl and index the paginated pages for load more + lazy load.
Actions:
- Use third party crawlers to detect noindex or canonicalized paginated pages on the website.
- Inspect paginated page URL index status in Google’s index using the URL Inspection tool.
- Monitor the indexability of paginated pages using the Index Coverage Status report.
Duplicate paginated pages
Just like the indexable issues, it is difficult to highlight duplicate content mistakes, as there is no crawl data due to web designs not using paginated URLs.
That said, just like paginated pages, the components in the load more series must still be unique. Any similar or duplicate content will cause Google to choose only a single canonical URL, instead of indexing them separately.
Actions:
- Use third party tools like Lumar to discover duplicate paginated pages on a website.
- Use duplicate or facet navigation SEO best practices to indicate the preferred paginated pages which should be used by Google as the canonical URL.
Infinite scroll
Infinite scroll is a single-page design which divides content across multiple components and allows users to continuously scroll through the content — without having to click on paginated links. It became popular after social media websites, like Twitter and Facebook, used infinite scroll so users can read through continuously updated information.
Of the sites with infinite scroll web designs, we found a large number did not meet the basic criteria to be classed as search friendly.
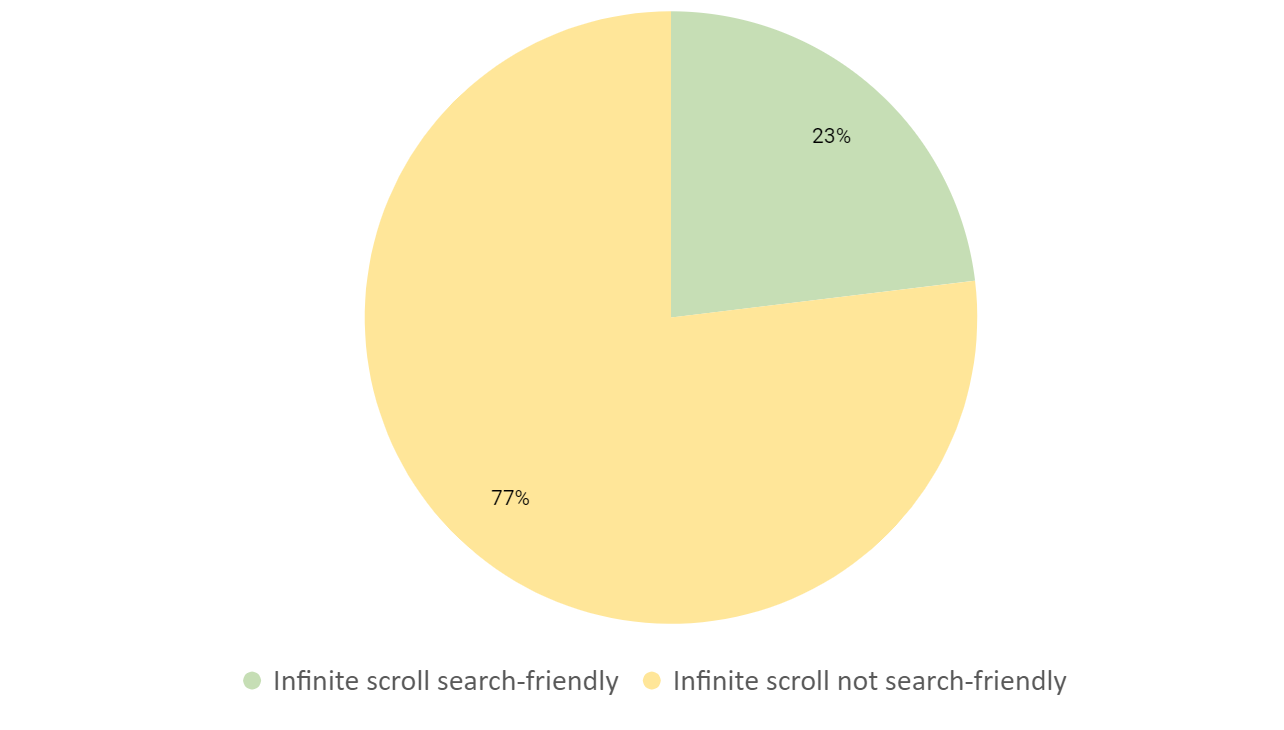
Again, just like the load more + lazy load single-page design, a lot of basic optimization techniques were missed when we dug into the data.
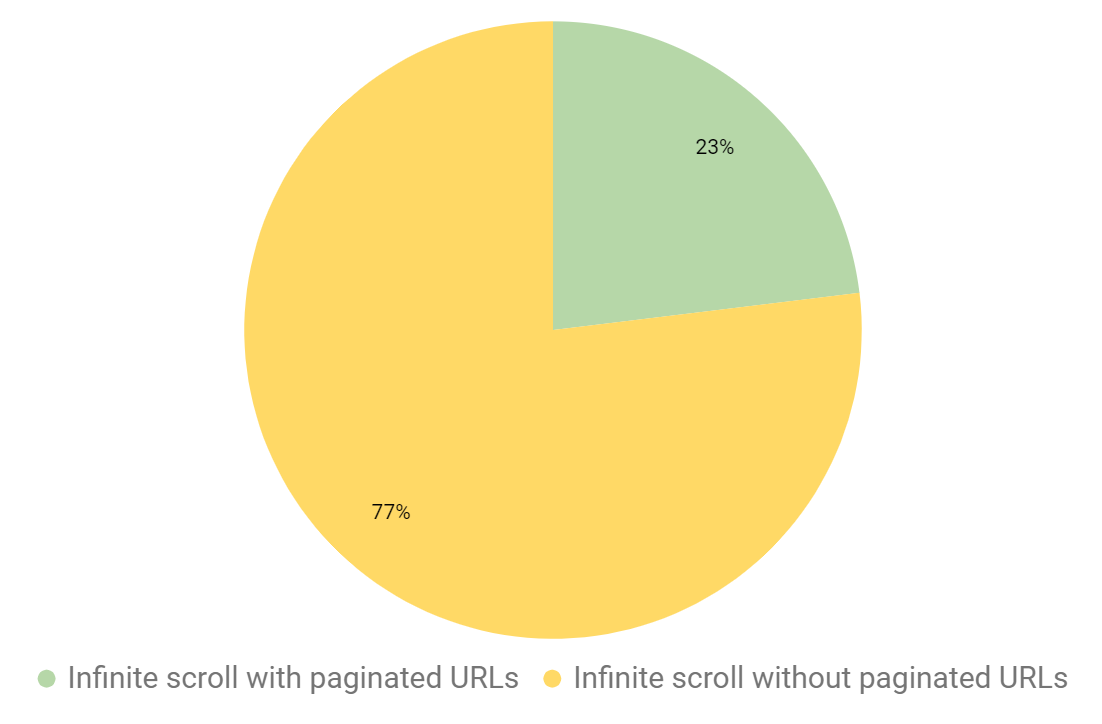
Paginated components with unique URLs
A critical part of getting content crawled and indexed in Google is that a page is assigned a URL. Google needs URLs to crawl, index, and rank content. To make sure content is indexed on infinite scroll designs it is best practice to assign a URL to each paginated component
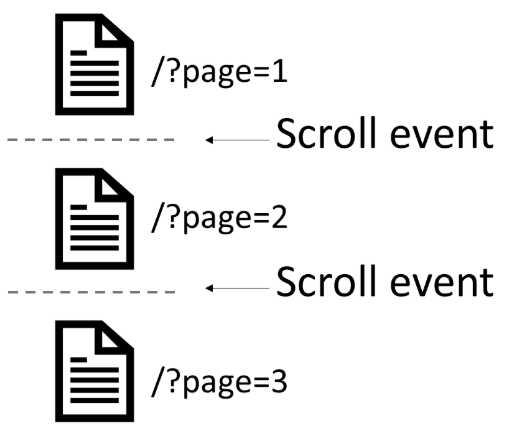
Infinite scroll to a search engine is just like a paginated page, except that the user scrolls through each paginated page. This concept should be simple to implement, however, it’s disappointing to see that a lot of infinite scroll designs we tested had no URLs assigned to the paginated components (checking manually and using crawl data).
Many infinite scroll designs which did not have unique URLs (and no crawlable links) shows a single URL in Lumar.
When testing the websites which do have unique URLs, these appear in the browser as a user scrolls.
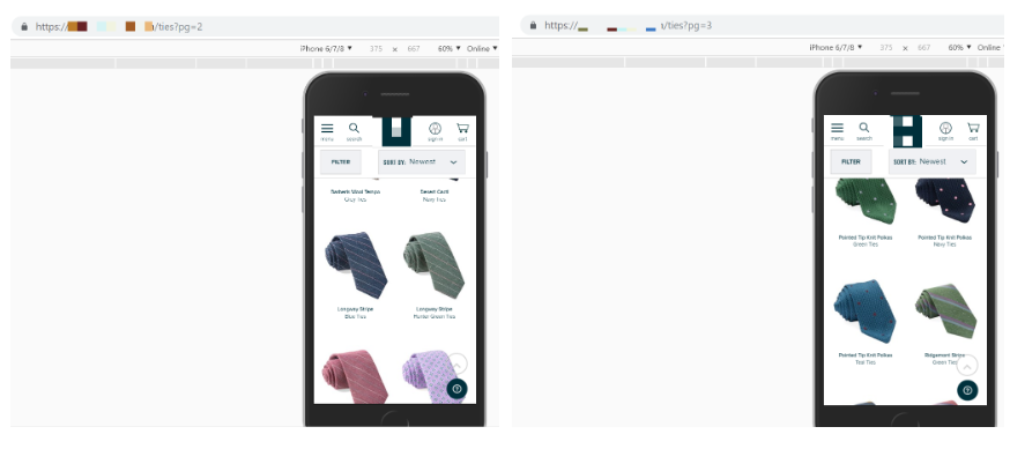
Many who have mapped paginated URLs to infinite scroll use the pushState method in the history API to update the URL in the browser so that the user knows where they are. Again, this is not essentual for crawling or indexing, but a nice touch to help users understand where they are on the website.
Actions:
- In your content management system (CMS) or web app, make sure infinite scroll content components are mapped to unique URLs (dynamic or static).
- If you can use the history API, update URLs in the browser to help users find which page products or articles can be found.
Crawlable links
Internal linking is an important way for Google to discover and crawl paginated pages on a website. However, adding crawlable links to a single-page design which uses infinite scroll is tricky.
It is a unique problem compared to pagination and load more + lazy load because both designs allow users to click to move on. An infinite scroll design on the other hand allows users to scroll through the divided content without having to click to move on.
This means it is difficult to add internal links as part of the design as the user does not need to click on any elements to continue to see more content. John Mueller did create an example site to showcase infinite scroll best practice, but very few websites have mimicked the internal link component.
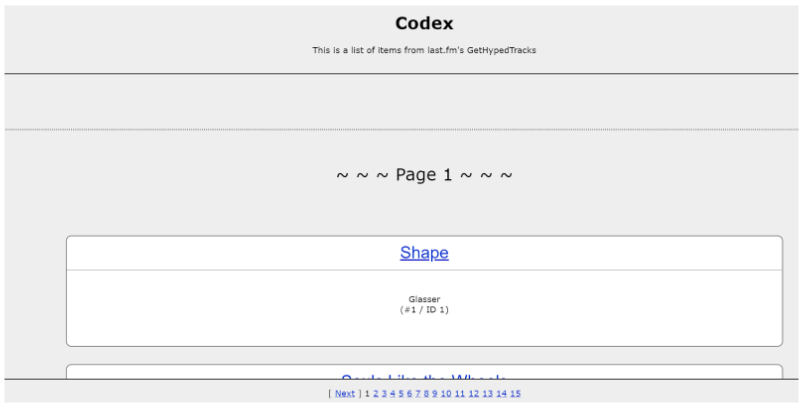
Figure 23 – John Mueller example infinite scroll website
When testing this website on mobile devices, the internal linking component almost shrinks to a point where a user cannot see the links.
Figure 24 – John Mueller infinite scroll site on mobile
As a mobile user, this is not a great experience and it’s almost impossible to navigate to paginated components. To get a better understanding if this has been done in a better way in the wild, we tested infinite scroll on websites which pass the search friendly criteria.
Our quick analysis found that for those infinite scroll designs with crawlable links, they had anchor links with href attributes linking to paginated components in the page source code.

What is interesting is that all the infinite scroll designs use hidden crawlable links (not visible on the page). When checking if paginated components are indexed across the site, they appear in Google Search.
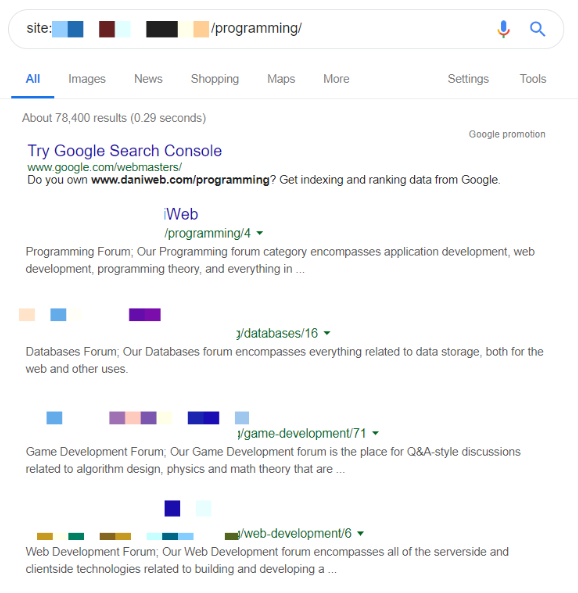
There is no way to verify 100% if these paginated pages are canonical URLs without Google Search Console, but the fact that they have appeared in a site operator indicates they have been discovered and crawled by Google.
Quick note: We should point out that site owners should be careful when adding hidden crawlable links to infinite scroll designs. Although it does appear to be working for some websites, hidden links could be viewed by their algorithm as deceptive and going against their Google’s webmaster policies. However, this is a bit of a grey area and users and bots are both seeing the same content (you’re just making it easier for bots to crawl your content).
A few quick searches in Google revealed no useful solutions to adding visible crawlable anchor links to infinite scroll designs. Google Developer and help documents also did not provide any answers. Unfortunately, this means that at the time of writing this blog post, there is no clear solution to adding crawlable links to infinite scroll designs on websites. As there is no clear solution, it is critical that technical SEOs work with developers, product managers and designers to identify the best method of adding anchor links to infinite scroll.
Actions:
- Add anchor links with href attributes to infinite scroll paginated page components, linking to other paginated pages (easier said than done).
- Work with developers, product managers, and designers to add crawlable links to infinite scroll web designs.
- We highly recommend creating a minimum viable test website with the new design and running crawl tests to see how accessible paginated pages are to search engines — before pushing live.
Reliance on rel=“next” and rel=“prev”
One of the common patterns with infinite scroll is that many website owners rely heavily on rel=“next” and rel=“prev” to link paginated pages. They do not use any anchor links to internally link paginated pages in this type of web design.
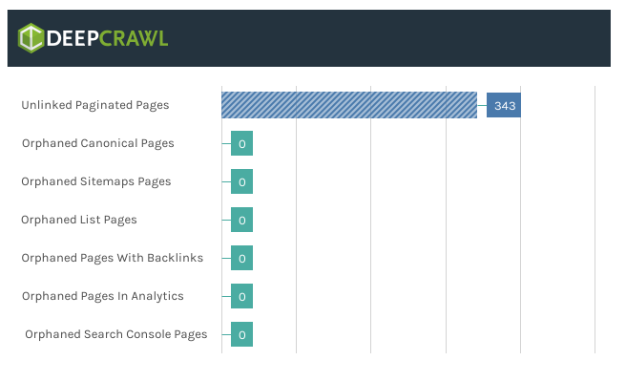
As discussed, Google announced that it no longer supports the rel=“next” and rel=“prev” link elements in their index. However, a quick test found that the search engine might not even use these link elements to discover paginated pages.
1/3 **TEST IN MUNICH**
Q: Does Google crawl URLs in rel=next and rel=repv?
H: I thought Gbot would treat similar to <a href> element.
R: 1 week and 3 days checking log files Googlebot still hasn’t crawled URLs found in rel=“next” and rel=“prev” <link> elements. pic.twitter.com/VVcjwTQEPB
— Adam Gent (@Adoubleagent) 1 April 2019
This means that site owners tried to use rel=“next” and rel=“prev” as a replacement to crawlable links, however, this means that Google will not crawl paginated pages (if they are not found in internal links or XML Sitemaps).
Actions:
- Do not rely on rel=“next” and rel=“prev” link elements for content discovery for Google; tests show, however, that it is crucial to include pages in anchor links.
Indexable paginated pages
As already mentioned, it is important that paginated pages are indexed and chosen as a canonical URL, so that it can follow links and use the content in its evaluations.
A small number of infinite scroll web designs did have paginated URLs and were discovered by our crawler, however, they were canonicalized back to the first page in the series.
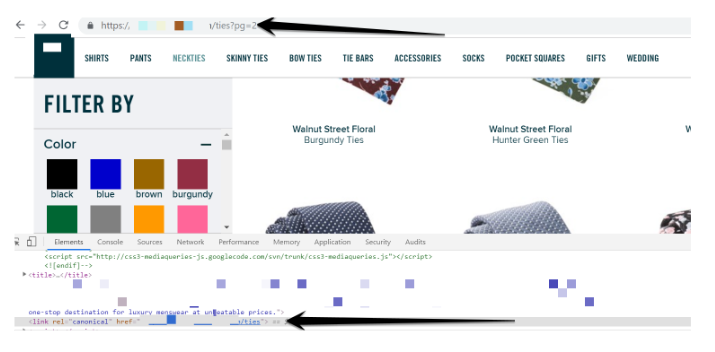
Using the rel=canonical link tag to point back to the first page is a strong signal to Google and other search engines not to index any paginated pages past page one. This will cause any internal links on two pages and above to not be followed by Google as the paginated pages are excluded from the index.
Any important paginated pages where the only access points for deeper level pages should not be excluded from Google’s index.
Actions:
- Use third party crawlers to detect noindexed or canonicalized paginated pages on infinite scroll web designs.
- To identify the index status of paginated pages in Google’s index, use the URL Inspection tool.
- Monitor the indexability of paginated pages using the Index Coverage Status report or a third party crawler.
Duplicate paginated pages
Our crawl data did not detect duplicate content for infinite scroll. However, just like the other web designs, all content on important paginated pages should contain unique content. If content is duplicate or similar, then Google might exclude the pages from its index as it chooses a canonical URL.
Actions:
- Use third party tools like Lumar to discover duplicate paginated pages on a website.
- Use duplicate or facet navigation SEO best practices to indicate the preferred paginated pages which should be used by Google as the canonical URL.
Summary
Hopefully our research and experiments into crawling pagination web designs in the wild have identified some common technical mistakes which should be avoided. This small crawling experiment was designed to help SEOs identify ways they can optimize pagination on their websites.
There is a lot more which needs to be considered when managing and optimising pagination which we haven’t mentioned here and hope to do more experiments in the next few months.
If you want to read more about advanced SEO techniques to optimize and manage pagination, read our Technical SEOs Guide to Pagination (post rel=“next” and rel=“prev”).
Get started with Lumar to help manage and optimise your website’s pagination design
Get started with a Lumar account today to identify technical issues with your websites’ pagination design.



