Single Page Apps (SPAs) that use JavaScript frameworks have become increasingly popular over time, due to their flexibility and native experience. However, perhaps more than any out-of-the-box CMS, there is the risk of crawl issues significantly impacting how they are understood by search engines and, by extension, their organic reach.
In this article, we run through some of the most common crawl issues we see on SPAs and how to fix them.
1. Not every page has its own URL
For search engines to understand and rank a page, it must have its own URL. When using SPAs this is not a given by default and pages are often generated using fragments, rather than crawlable URLs, for example:
For example:
Non-crawlable fragment: example.com/#interesting-information
Crawlable URL: example.com/interesting-information
You need to ensure the site is set up correctly to have each page on a crawlable URL to get these pages indexed.
Why does this matter?
Search engines disregard fragments and don’t crawl them as individual URLs. Therefore, there will be a huge amount of information search engines are not discovering and are unable to index.
If search engines cannot index your information – you’re not going to be able to rank for the terms you want to rank for and you’re not going to get much organic visibility.
How to fix it
You need to ensure your SPA is set up to generate individual URLs for each page using the History API, using a specific URL and not relying upon fragments to load in different information.
2. The site is fully client-side rendered
The beauty of SPAs is also their downfall when it comes to crawling.
SPAs are very often client-side rendered (CSR) by default. This means that the site is fully rendered in the browser, rather than on the server. For CSR sites, there is very little information about the site in the initial source code, as it relies on rendering JavaScript to load in all information about the page.
For users, this tends to be fine as they can see and access the information when it reaches the browser.
However, search engines index a site in various stages, which makes matters more complex for them to crawl, render, and index.
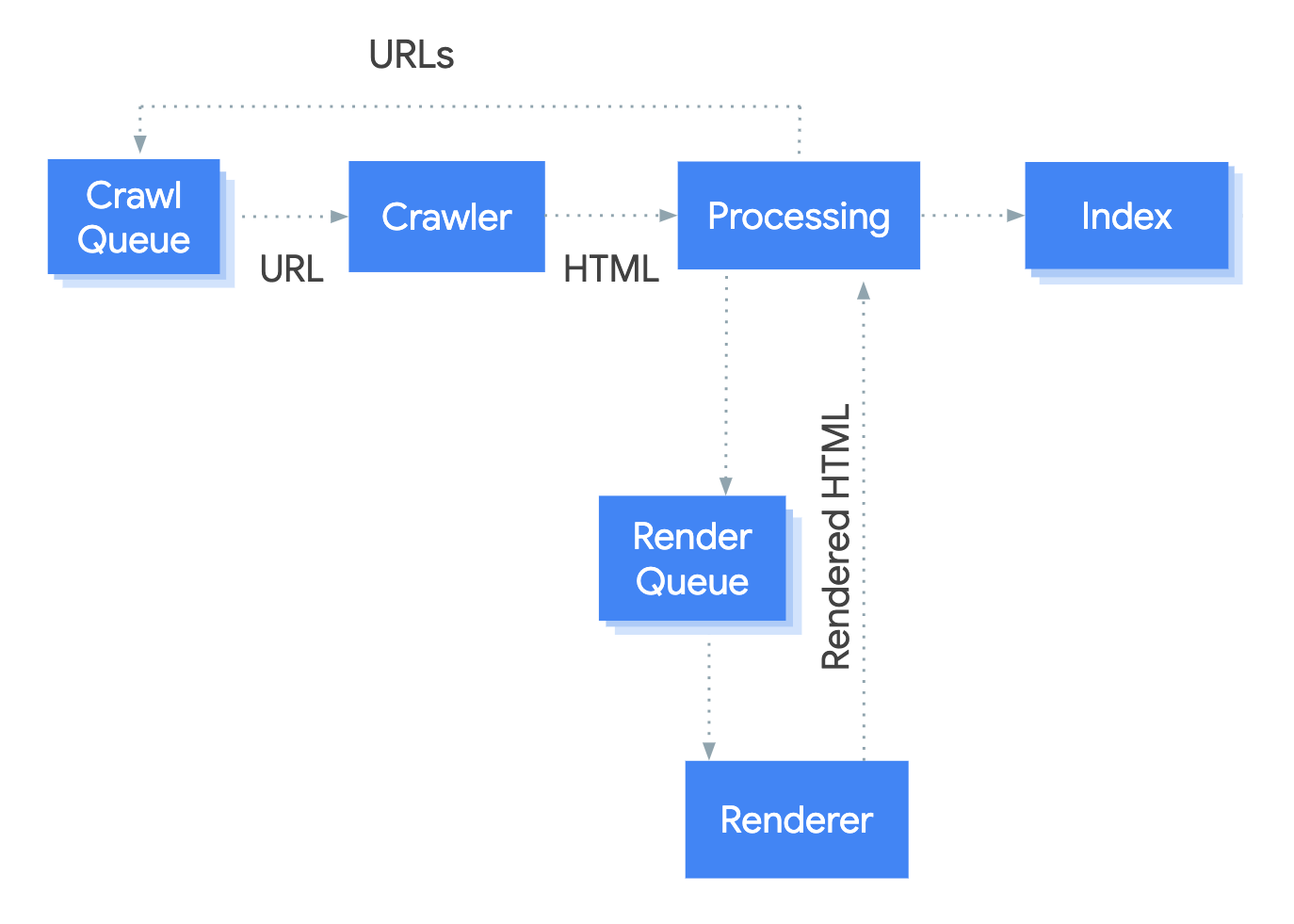 Since CSR websites require almost all of their information to be rendered, this gives search engines very little information about the site when they crawl the site in the first stage of indexing. Very few, or even no new URLs are found in the initial crawl.
Since CSR websites require almost all of their information to be rendered, this gives search engines very little information about the site when they crawl the site in the first stage of indexing. Very few, or even no new URLs are found in the initial crawl.
It’s not until the second wave of indexing when the site is rendered, that search engines begin to get a greater understanding of the website and identify additional URLs. Compare this to server-side rendering (SSR), in which the full HTML of each page is returned, including internal links, and additional requests sent to the server to return the relevant information on each URL very quickly.
Why does this matter?
Firstly, not every search engine crawler can render JavaScript so immediately this limits the reach of your site. As there is very little information sent across in the initial HTML, some search engines will not be able to accurately read your website.
Those search engines that can render JavaScript require a lot more resources to render JavaScript than to simply crawl the HTML of a page. Therefore, relying on the rendering stage of indexing is hugely limiting. You’re asking for search engines to do a lot of work to render the information about the entire site.
Since rendering is very resource-intensive, this means that pages are added to a render queue. This results in fewer pages being discovered, and at a much slower rate. All in all, this can impact both how much a search engine indexes on your site, and how much it understands about the site which can have knock-on impacts on ranking.
How to fix it
There’s a couple of different options to ensure your SPA is set up so search engines have a much easier time of crawling and understanding your website:
- Server-side rendering (SSR) – a request is sent to the server every time a new URL is crawled. The server returns the relevant HTML to be crawled and then rendered by search engines. Some JS frameworks have options that are SSR by default such as Angular Universal.
- Dynamic rendering – your server differentiates between requests from users and search engine crawlers based on their user agent. For users, it returns the CSR version of the site which is rendered in the browser. For defined search engine crawlers, it serves the pre-rendered HTML and JS to remove the huge reliance on the rendering stage of indexing to understand the site.
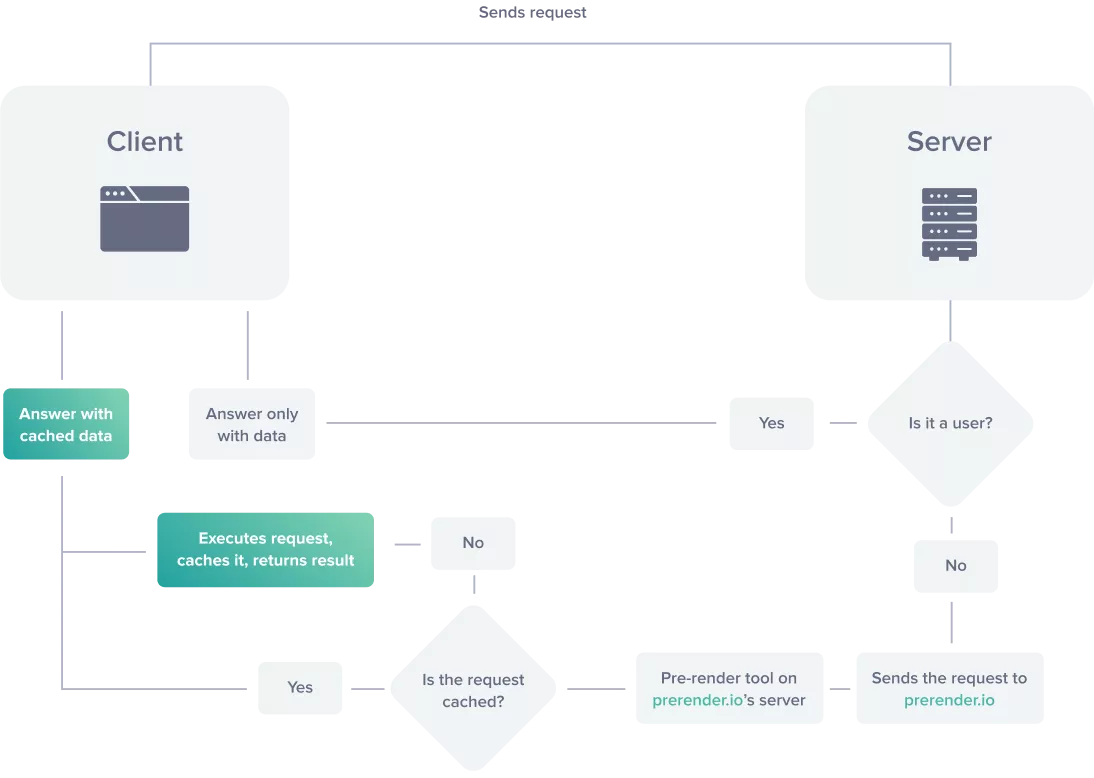
3. Dynamic rendering setup stopping certain user-agents
If your SPA has opted for a dynamic rendering solution to serve the pre-rendered HTML & JS to search engine crawlers and the client-side rendered site to users, this still may not fully ensure you’re set up for organic search.
It’s important to check that the settings of your dynamic rendering allow every crawler you want to be able to access the site. If they’re not – you may be stopping search engines from understanding your site.
Why does this matter?
If certain search engine crawlers are not being served the pre-rendered HTML – they are essentially getting the CSR version of the site, which we know is very limited. This again relies heavily on rendering which poses the same issues as a CSR site for that search engine.
This means that you may be limiting traffic to one or many search engines if your server is not properly configured to understand which user agents to serve the pre-rendered HTML to.
How to fix it
It’s crucial to look at your log files to understand if there are some user agents not properly configured to receive the pre-rendered HTML in a dynamic rendering solution.
Depending on what platform you’re using to pre-render your site, this often comes as part of their package. If there is a particular user agent that should be crawling your site that isn’t generating many requests this could suggest you are not properly set up to be serving them the pre-rendered HTML.
At this point – you need to review the configuration to fix this.
4. JavaScript required to crawl certain sections
Even if most of your SPA is server-side rendered, or a dynamic rendering solution is set up, there may be particular sections of the site that still are reliant on search engines rendering JavaScript to understand. This may be due to third-party JavaScript generating new URLs, or certain areas not being configured to be rendered by the server.
This is not as problematic as having the whole site client-side rendered, however, can still pose some problems as it relies on the more resource-intensive.
Why does this matter?
We want to make it as easy as possible for search engines to crawl and understand our websites. If certain areas cannot be accessed (such as by search engines that can’t render JavaScript), or are less easily accessible due to the resource-intensive process of rendering being required this can make it harder for search engines to find and index our site, and potentially make them less likely to rank.
For example, it may take a search engine longer to identify pages deep in a site, if those links are only identified using JavaScript, due to the large render-queue and resources required to render the source, find, crawl, and understand them.
Similarly, if this content changes, it may take search engines longer to identify these updates for the same reasons – meaning any great changes you make on your site to help improve your visibility may not be found and taken into consideration for a long time.
How to fix it
You can identify potential problem areas on your site by comparing the HTML of a page to the rendered DOM to see if any links not present in the initial HTML are being generated by JavaScript. Comparing a regular crawl with a JavaScript rendered crawl can also help to understand if this is an issue on your site.
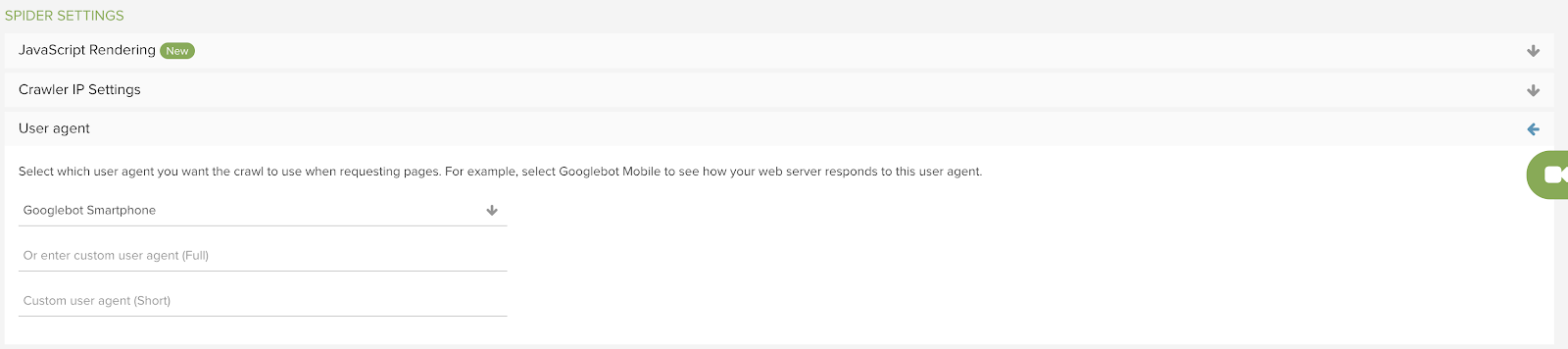
How to identify crawling issues
If you crawl your site without using JavaScript rendering and the crawl only returns a single URL or very few URLs, there’s a high likelihood that the site is relying on CSR (it’s important to rule out other possibilities that may be limiting the crawl, such as security setting, nofollow on internal links, robots.txt blocks, authentication & password-protected websites, etc.).
If you then re-crawl the site with JavaScript rendering enabled and your site starts returning many more URLs – this confirms that your site is very likely to be relying on client-side rendering.
If you’re crawling a site using dynamic rendering, it’s important to use a user agent that has been defined as returning the full site HTML, rather than the CSR version. This may be a common user agent, or it may be a custom user agent. Either way, these should be selected in the crawl settings, such as those in Lumar shown below: