

Noindex, Nofollow & Disallow: What are these directives & how do I use them on my website?
* Note: This post has been updated on January 23, 2023.
The three words above might sound like SEO gobbledegook, but they are definitely words worth knowing, since understanding how to use them means you can order Googlebot around. Which is fun.
So let’s start with the basics: there are three ways to signal which parts of your site search engines should crawl and index:
- Noindex: tells search engines not to include your page(s) in search results. A page must be crawlable for bots to see this signal.
- Disallow: tells search engines not to crawl your page(s). This does not guarantee that the page won’t be indexed.
- Nofollow: tells search engines not to follow the links on your page.
So let’s start with the basics: there are three ways to signal which parts of your site search engines should crawl and index:
- Noindex: tells search engines not to include your page(s) in search results. A page must be crawlable for bots to see this signal.
- Disallow: tells search engines not to crawl your page(s). This does not guarantee that the page won’t be indexed.
- Nofollow: tells search engines not to follow the links on your page.
What is a noindex meta tag?
A ‘noindex’ tag tells search engines not to include the page in search results.
The most common method of noindex-ing a page is to add a tag in the head section of the HTML, or in the response headers. To allow search engines to see this information, the page must not already be blocked (disallowed) in a robots.txt file. If the page is blocked via your robots.txt file, Google will never see the noindex tag and the page might still appear in search results.
To tell search engines not to index your page, simply add the following to the <head> section:
<meta name=”robots” content=”noindex”>
Alternatively, the noindex tag can be used in an X-Robots-Tag in the HTTP header:
X-Robots-Tag: noindex
For more information see the Google Developers’ guidelines for blocking search indexing with noindex.
What is a disallow directive?
Disallowing a page means you’re telling search engines not to crawl it, which must be done in the robots.txt file of your site. It’s useful if you have lots of pages or files that have no organic search value, as it means search engines won’t waste time crawling these pages.
For very large sites, this can be useful in maximizing crawl budget.

To add a disallow directive, simply combine it with the relative URL path and add it to your robots.txt file:
Disallow: /your-page-url
Entire directories of your site can be disallowed, too. End the rule with a / for this to take effect:
Disallow: /directory/
A user agent must be specified somewhere above this line. Use an asterisk in this field to match all crawlers (except Adsbot, which would need to be named explicitly). For example:
User-agent: *
The disallow directive simply prevents bots from crawling the content on these URLs. It is still possible for a disallowed page to appear in the index, for example, if search engines are able to find it via incoming external links, or if it was crawlable prior to the addition of the relevant disallow rule. Because the page(s) become uncrawlable with the introduction of a disallow rule, these pages usually display a ‘no information is available for this page’ message when they appear in SERPs.
Can I combine noindex and disallow?
Disallow directives shouldn’t be combined with noindex tags. This is because preventing search engines from crawling the page also prevents them from seeing the noindex tag. The page won’t be crawled, but there’s still a chance it’ll be indexed if it’s found via other sources.
If you truly do not want a page to appear in SERPs, a noindex tag is the way to go.
What is a nofollow tag?
A nofollow tag on a link tells search engines not to pass link equity from that source page to the destination site. They are also designed to prevent search engines from following the link and discovering more content through it.
Common uses for nofollows include links in comments and forum posts, or any other content that you don’t control. They can also be found on many paid links, embeds such as widgets or infographics, links in guest posts, or anything off-topic that you still want to link people to, but don’t necessarily want search engines to follow and crawl.
Historically, SEOs have also selectively nofollowed links, to funnel internal PageRank to more important pages.
Nofollow tags can be added in one of two places:
- The <head> of the page (to nofollow all links on that page): <meta name=”robots” content=”nofollow” />
- The link code (to nofollow an individual link): <a href=”example.html” rel=”nofollow”>example page</a>
A nofollow won’t prevent the linked page from being crawled completely; it just prevents it from being crawled through that specific link. Our own tests, and others, have shown that Google will not crawl a URL that it finds via a nofollowed link.
Google states that if another site links to the same page without using a nofollow tag or the page appears in a sitemap, the page might still appear in search results. Similarly, if it’s a URL that search engines already know about, adding a nofollow link won’t remove it from the index.
In September 2019, Google announced an update to their nofollow directive and introduced two new link attributes, these are:
- rel=“sponsored” – The sponsored attribute should be used to identify links that are for advertisement purposes, where sponsorship and compensation agreements are in place.
- rel=“ugc” – As the attribute for User Generated Content, this value is recommended for links within user-generated content sites, for example, forum posts and blog comments.
In addition, all links marked with nofollow, sponsored, or UGC are now treated as hints regarding which links to consider in search and when crawling, as opposed to just a signal, as was used previously for nofollow. You can find out more about this update in our post which also covers the impact of these along with expert insights.
What is noindex, nofollow?
As mentioned above, adding a nofollow tag to a page won’t prevent it from being crawled. To prevent a URL from being indexed, you’ll also need a noindex tag. This will allow Google to crawl the page, but it will not appear in the index. To stop Google from crawling the page completely, you should disallow it via robots.txt.
Other directives to know: canonical tags, pagination, and hreflang
There are other ways to tell Google and other search engines how to treat URLs — these are also worth knowing! Check out the resources below to learn more.
- Canonical tags tell search engines which page from a group of similar pages should be indexed. Canonicalized (ie. secondary pages that direct search engines toward a primary version) are not included in the index. If you have separate mobile and desktop sites, you are supposed to canonicalize your mobile URLs to your desktop ones.
- Pagination groups multiple pages together so that search engines know they are part of a set. Search engines should prioritize page one of each set when ranking pages, but all pages within the set will stay in the index.
- Hreflang tells search engines which international versions of the same content are for which region, so that they can prioritize the correct version for each audience. All of these versions will stay in the index.
How much time should you spend on optimizing crawl budget?
You might hear a lot of talk on SEO forums about how important crawl efficiency and crawl budget are for SEO. While it’s common practice to disallow and noindex pages that have no benefit to search engines or users (for example, back-end code that is only used for the running of the site, or some types of thin or duplicate content), deciding whether to hide lots of individual pages is probably not the best use of time and effort. Unless there is a specific reason to hide a page from search engines, it’s usually best to leave the decision up to them.
Testing your directives with Lumar
Find all non-indexable pages using Lumar
The non-indexable pages report includes details of all pages with a non-indexable status. You can see the total number of these, as well as a breakdown of the rules that are causing them to be classed as non-indexable:
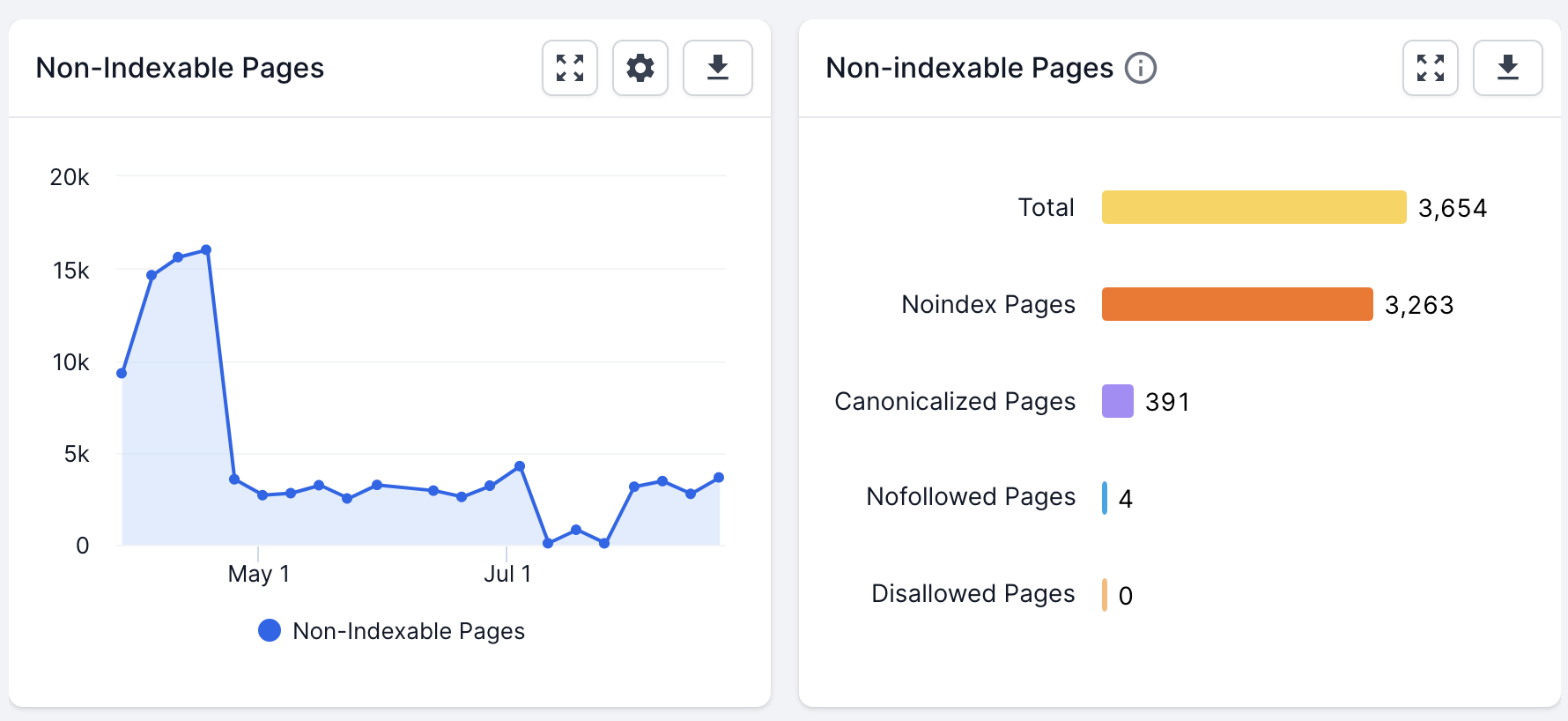
From here, dive into the individual reports to check that the right rules are applied to the right URLs.
Indexation > Noindex Pages
This report will show you all pages that contain a noindex tag in the meta information, HTTP header or robots.txt file.
Indexation > Disallowed Pages
This report contains all URLs that can’t be crawled because of a disallow rule in the robots.txt file.
Test a new robots.txt file using Lumar
Use Lumar’s robots.txt overwrite function in Advanced Settings to replace the live file with a custom one.
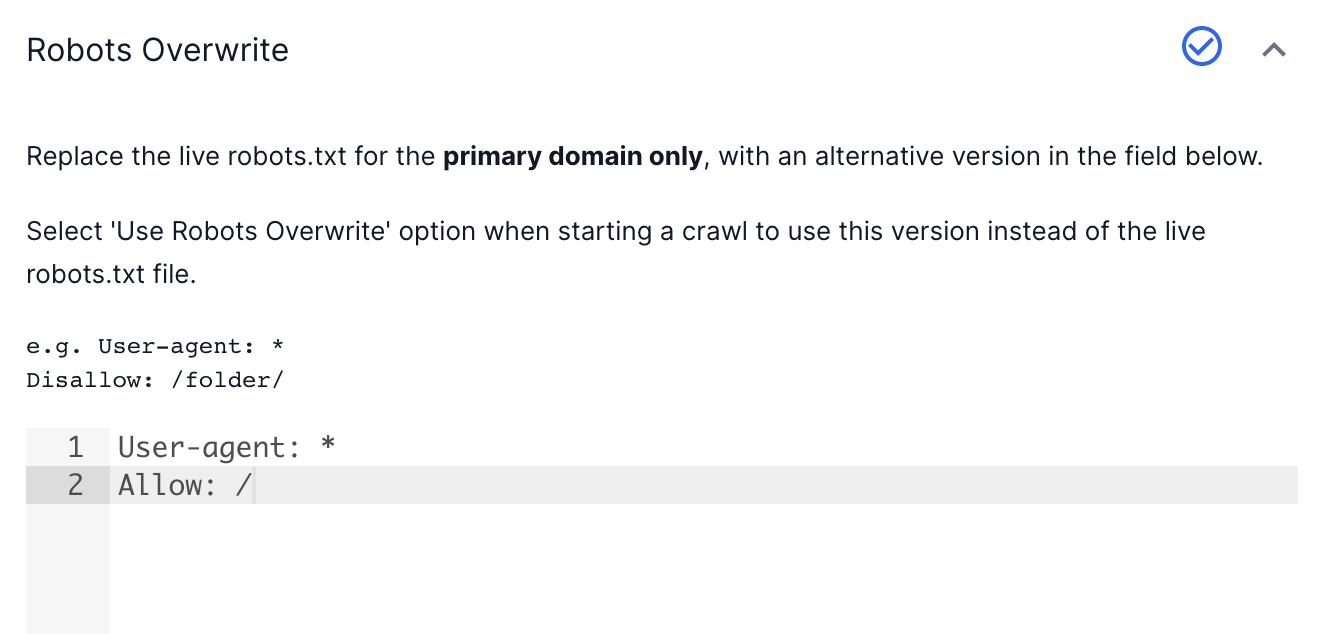
The next time you start a crawl, your existing robots.txt file will be overwritten by the new rules. This allows you to check that the right URLs are being disallowed before you roll the changes out to the live site.
For more information, read our guide to managing robots.txt changes with Lumar.
Additional technical SEO learning resources
We hope that you’ve found this post useful in learning more about noindex, nofollow, and disallow to control the crawling and indexing of your site.
You can read more about these topics in our Technical SEO Library, or if you want to learn how to conduct a technical SEO audit, have a read of our guide. We’ve also got a great selection of regularly updated eBooks on technical SEO topics to help you stay up-to-date with Google’s latest updates and best practices for SEO.
* Note: This post has been updated on January 23, 2023.



