

Writing and making changes to a robots.txt file can make even the most hardened SEOs a little bit nervous. Just one erroneous character could have a major impact on performance, or even wipe out your entire site.
And it doesn’t have to be your mistake, either: if you have lots of people working on the same site, then it’s not unusual for an edit to be made without notice, or for an old version to be uploaded in error.
Search Console is great when something’s already gone wrong, but if you’re going to protect your site properly then you need a more robust system in place. Here’s our guide to writing, editing and managing a robot.txt file that won’t drive you crazy.
Before the changes: test, test and test again
1. Decide which URLs to disallow
The first thing to do is decide which URLs you want to disallow in your robots.txt file. Download a full list of your URLs with a crawler like Lumar (formerly Deepcrawl), then look for low-value pages that you don’t want search engines to crawl.
Don’t forget to:
- Create additional rules and add them to your existing robots.txt.
- Check for any conflicting rules.
- Try to simplify to the fewest number of rule possible, but be as specific as possible.
There’s tons of information on writing robots.txt files on Google Search Console and Bing Webmaster Tools.
2. Check that robots.txt is correctly disallowing
Use the Search Console > Robots tool to check a list of URLs against a modified robots.txt. But remember: this tool handles Allow rules slightly differently to the real Googlebot. There are a few edge cases where the behaviour of Googlebot is ‘Undefined’.
3. Test a crawl with your new robots.txt file before it goes live
Use the Lumar Robots.txt overwrite function in Advanced Settings to replace the live file with a custom one.
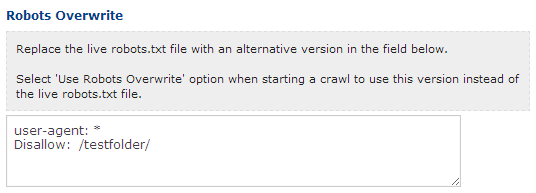
You can then choose to use this robots.txt file instead of the live one the next time you start a crawl.
The Added and Removed Disallowed URLs reports will now show exactly which URLs were affected by the changed robots.txt making evaluation very simple.
4. Test on a staging site (optional)
If you want to crawl a staging environment which has a disallow all robots.txt file to prevent indexing, you can overwrite with an Allow all robots.txt file. For example:
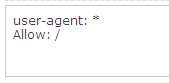
5. Test for ‘hidden’ allowed pages (advanced users)
The default settings of Lumar and other crawlers don’t allow for disallowed pages to be crawled, so there might be other new allowed pages hidden behind the disallowed ones that you might never discover.
To crawl the first level of disallowed pages and discover other pages beneath, use Lumar’s advanced option in Advanced Settings > Crawl Restrictions.

Even this won’t give you a complete picture of every disallowed URL. The only way to do this is to first crawl the site with an Allow All robots.txt file using the robots.txt overwrite (as described above) to find every URL without any restrictions, then crawl again using the live robots.txt file.
You can then see all the URLs that are no longer included in the crawl.
After the changes
1. Keep track of robots.txt changes
Set yourself up with alerts from a tool like Robotto and you’ll get an email whenever your robots.txt file has changed. This way, you can make sure you are aware every time the file is changed, and start to understand the impact of the changes.
2. Check for disallowed URLs
Go to the Google Search Console Google Index > Index Status report (in advanced mode) and check whether your robots.txt changes have had any significant impact on the number of disallowed or allowed URLs on your site.
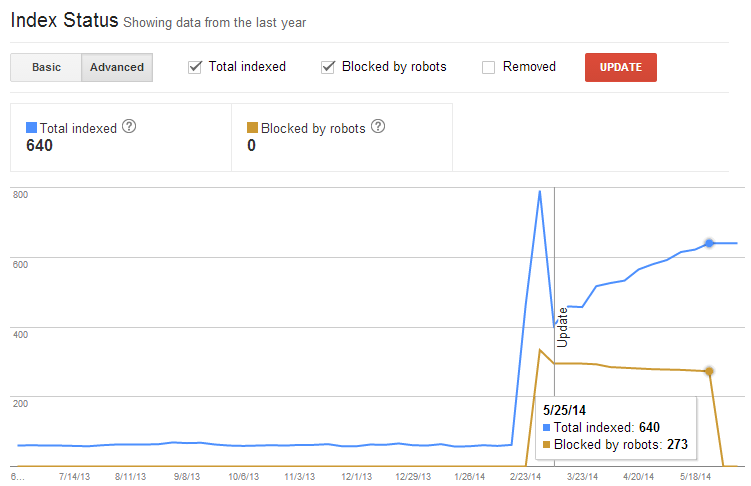
However, this won’t give you specific information on the URLs that were disallowed. For this, use the Lumar Disallowed URLs report. Disallowed URLs aren’t crawled so they don’t count towards your crawl costs, even when the report runs into the millions of URLs.
3. Test for caching issues
A robots.txt server caching issue could mean Google is seeing a different robots.txt version to the visible one. Use the Google Search Console Crawl > Robots.txt Tester to see which version Google is currently using, test specific URLs against it and even test any further changes you want to make.
If there’s a problem, the specific line that led to the issue will be highlighted:
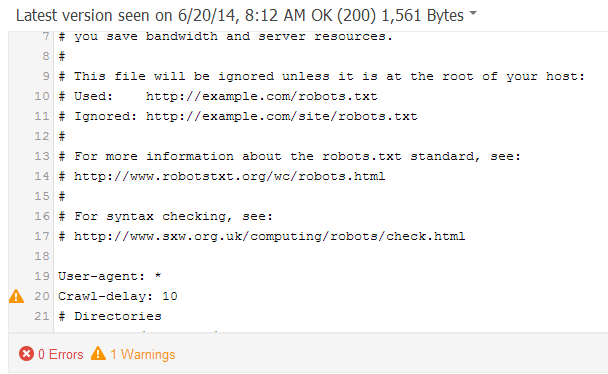
Click on the See live robots.txt file link on the right-hand side to compare this cached/edited version with your live one.
4. Check the size of your robots.txt
If a robots.txt file is larger than 500KB then Google might not process it in full. However, it’s very unlikely that anything you do intentionally would make your file larger than this. Check whether your file exceeds this limit – if so, there’s a bigger problem elsewhere.
5. Check user agent-specific robots.txt files
Sometimes, the robots.txt file delivery is customised for Google, Bing or non-search engine users, which can make it very difficult to test and there is a big risk of something going wrong.
Run your robots.txt file through the Fetch as Google tool to see exactly what Google is seeing.
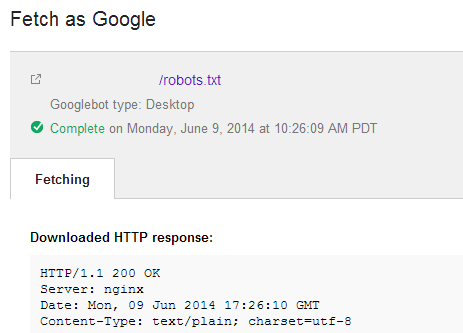
You should also run the same file through the Fetch as Bingbot tool in Bing Webmaster Tools.
Finally, the Fetch as Lumar (Deepcrawl) tool can be used to test a variety of different user agents to see if the robots.txt changes.
If you don’t yet have a Lumar account, you can request a live demo here on a site you’re working on, or log in now to get started.



