

Auditing a site for technical SEO issues is one of the skills setting SEO-pros apart from all the noobs and pseudo-experts[JU1] . While there is a plethora of handy tools that allow you to find the usual discrepancies in the “length of page title” and “www redirection” for the average site, finding out what’s wrong with an enterprise site running into the millions of pages isn’t your friendly SEO ninja’s cup of tea.
The reason for this is the complexity inherent to any site as it grows and changes over time. Some sites evolve so much with pages added, removed and modified all over the place that even their developers and webmasters find it hard to recognize them a few months down the line. Don’t believe me? Let me give you a simple example. Ask any webmaster how they think link equity flows through their site. Their answer will be something like this:
In reality, it’s closer to this:
To understand how link equity flows through a site, we must begin by understanding how a bot crawls it. And that’s what technical SEO is all about. Googlebot doesn’t always enter your site from the homepage and exit from the lowest level product page. It might come in through your most popular pages and crawl the same pages over and over again.
Which is why looking at crawl equity and flow – how bots move through your site and process content – is paramount.
To know the “flow” of your site inside out, you need to
- Understand each part of your site and check how it’s indexed.
- Analyze your crawl budget.
- Audit your sitemaps.
- Correct your crawl errors.
- Analyze how Google crawls your JavaScript.
Let’s look at each of these steps in detail. SPOILER ALERT: We won’t beat around the bush here about what each term means. Since this is a post aimed at intermediate to advanced SEOs, we’ll get straight to the point.
1. Checking Indexation
Step #1 – List out all the types/templates of pages that make up your site. These might include:
- Those links, such as “Privacy Policy” and “Terms & Conditions,” which have been lying in your footer for ever
- That HTML sitemap you created in 2001
- Those subdomains for your client logins or demo versions, and even separate microsites that you created for a one-time campaign
Step #2 – Determine which are the most important pages for your business. These would be your product pages, category pages, landing pages, as well as entertaining staff bios.
Step #3 – Check how many pages have been indexed in Google Search Console.
And then run a site:query to figure out how many pages of each type or template have been indexed by Google. Start with the pages that you prioritized in step #2. For example:
Do you see a difference between the actual number of pages you have and the number Google has indexed? Chances are, you do. Dig into this discrepancy. Are there dynamic URLs being generated? Is Google detecting pagination properly?
2. Analyzing Crawl Budget
The number of pages that Googlebot allocates to your site per day is the crawl budget that you receive. Search Console gives you a sweet breakdown of your crawl budget, in terms of pages, size as well as time:
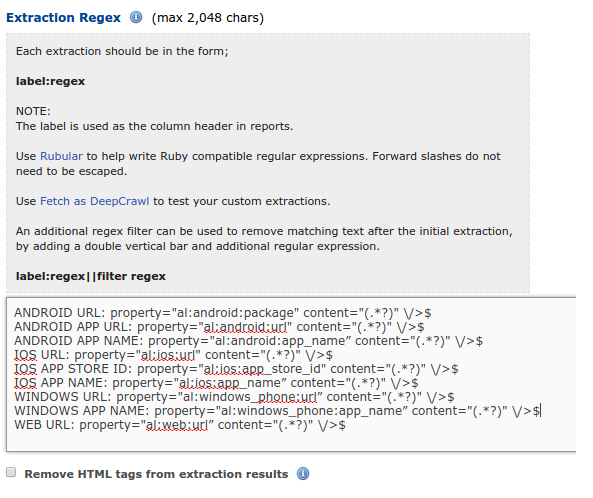
DeepCrawl goes beyond and gives you details on:
- crawled and un-crawled URLs
- non-200 status codes
- non-indexable pages
- invalid tags
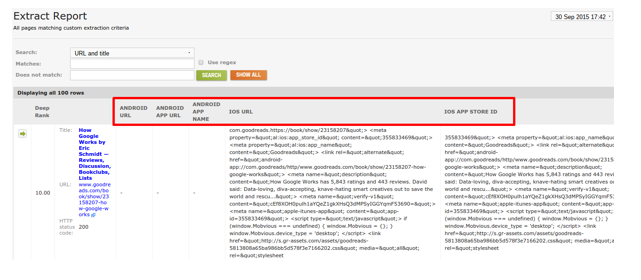
The questions you need to ask yourself are:
- Are your money pages easy for the bot to get to and crawl?
- Do you know exactly what happens when bots land on these money pages? like…where do they go next?
- How many levels deep can a bot crawl?
- What can you do to improve the accessibility and crawlability of these pages?
If you’re further interested in how Googlebot crawls sites, take a look at Dawn Anderson’s Brighton SEO presentation of April 2016: SEO Crawl Rank and Crawl Tank.
3. Auditing the Sitemap
A sitemap signifies to Google the pages you intend it to crawl.
You have probably never bothered with a second look at the contents of your sitemap. Most sites have an auto-generated sitemap – from the Yoast plugin on small to medium sites to scheduled scripts on enterprise sites. Ain’t nobody got time to comb through tons of URLs, check what HTTP codes they return, and their priorities etc!
As usual, an easy snapshot on the status of your sitemaps is shown by Google Search Console.

Regardless of the size of your site, it makes sense to have a sitemap index file and break down your sitemaps by the types of pages that you have. This will make it easier for you to see if important pages of each type are indexed.
4. Correcting Crawl Errors
Crawl errors are the bane of most sites looking to increase their search engine presence. While customer-facing website errors create a poor user experience, these pesky errors can also slowly eat up your site’s visibility in the SERPs; by eroding your domain visibility over time.
Start with the Google Search Console and weed out your server connectivity errors, and soft and hard 404s for desktop as well as mobile devices.
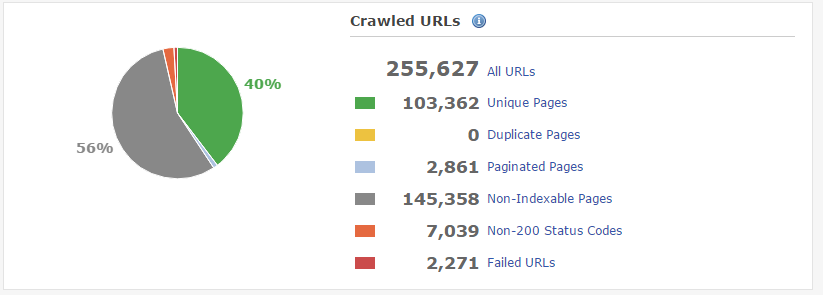
Clicking on each error will give you further details on each error. Most of the time, these are helpful. Sometimes, not so much. Queue the originating link itself not existing, in which case you can click “Mark as fixed”. If they reappear, then use DeepCrawl to crawl a selection of “linked from” URLs to understand the issue at hand.
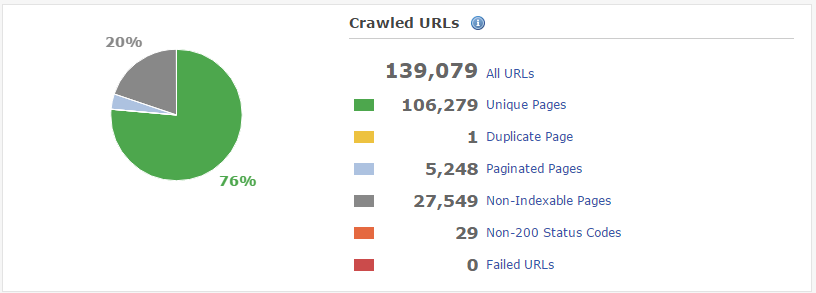
Finally, do check out if Googlebot fetches your pages correctly and renders them in the same way as you’d expect users to see them:
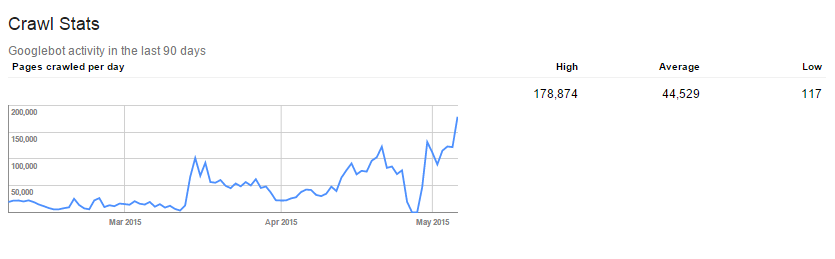
As we saw in the section on analyzing crawl budget, DeepCrawl can also help you pinpoint various types of crawl errors that even the Search Console can’t catch. Use both of these in conjunction to weed out your crawl errors and make a smooth pathway for Googlebot.
5. Analyzing JavaScript
Over the past couple of years, Google has improved its capacity to crawl and render JavaScript by leaps and bounds. They have specifically instructed webmasters not to block Googlebot from crawling JavaScript by way of the robots.txt file. However, Google is currently at a stage where “a little knowledge can be dangerous.”
As a result, many new sites that make liberal use of JavaScript and frameworks like Angular JS and Ember JS are facing a lot of problems, especially “crawl creepers,” which append themselves to a URL (such as pop-ups) and start filling the Google index with duplicate content. Therefore, the best practices in optimizing your JavaScript for Googlebot (at the moment) are:
- Do not block JavaScript from being crawled.
- Use the full path when executing URLs.
- Use the “rel=nofollow” attribute on URLs that invite creepers.
- Monitor which scripts are being executed and which aren’t.
In Conclusion
Hopefully you’ve gone far beyond the usual H1 and ALT tag optimization that technical SEO is associated with. Understand that the way and the extent to which Googlebot crawls your site forms the basis of your on-page SEO. All your on-site improvements should be woven around this central fact. Now you know how to:
- divide your site into page types and understand how much of each part is indexed
- analyze your crawl budget and try to raise it up!
- audit your sitemaps and identify inconsistencies
- analyze various types of crawl errors and correct them
- monitor how bots crawl JavaScript and make changes to the code accordingly
We’ll leave you with this quote (with apologies to Thomas Jefferson) from Jacqueline Urick, Web & SEO Manager at Sears:
“Eternal crawling is the price of visibility.”



