

Update: As of 1st September 2019, Google will be retiring all code that handles unsupported and unpublished rules in robots.txt including the use of the noindex directive.
How Robots.txt Noindex used to work
Despite never being officially documented by Google, adding noindex directives within your robots.txt file had been a supported feature for over ten years, with Matt Cutts first mentioning it back in 2008. Lumar (formerly Deepcrawl) has also supported it since 2011.
Unlike disallowed pages, noindexed pages don’t end up in the index and therefore won’t show in search results. Combining both noindex and disallow in robots.txt helped to optimise crawl efficiency, with the noindex directive preventing the page from showing in search results, and the disallow stopping it from being crawled:
Disallow: /example-page-1/
Disallow: /example-page-2/
Noindex: /example-page-1/
Noindex: /example-page-2/
An update to unsupported rules
On July 1st 2019, Google announced that the Robots Exclusion Protocol (REP) was becoming an internet standard, after 25 years, as well as now being open source. They followed this on July 2nd with an official note on unsupported rules within robots files.
This announcement informed us that, effective September 1st 2019, the use of noindex within robots.txt will no longer be supported by Google.
Gary Illyes explained that after running analysis around the use of noindex in robots.txt files, Google found “the number of sites that were hurting themselves was very high.” He also highlighted that the update “is for the better of the ecosystem and those who used it correctly will find better ways to achieve the same thing.”
As promised a few weeks ago, i ran the analysis about noindex in robotstxt. The number of sites that were hurting themselves very high. I honestly believe that this is for the better for the Ecosystem & those who used it correctly will find better ways to achieve the same thing.
— Gary “鯨理” Illyes (@methode) July 2, 2019
Alternative options to the noindex directive
If you are currently relying upon the noindex directive within your robots.txt file, there are a number of alternative options, as listed within Google’s official blog post;
- Noindex robots meta tags: This is the most effective way to remove URLs from the index but still allow crawling. These tags are supported in both the HTTP response headers and HTML and are achieved by adding a meta robots noindex directive on the web page itself.
- 404 and 410 HTTP status codes: These status codes are used to inform search engines that a page no longer exists, which will lead to them being dropped from the index, once they have been crawled.
- Password protection: Preventing Google from accessing a page by hiding it behind a login will generally lead to it being removed from the index.
- Disallow in robots.txt: Blocking a page from being crawled will typically prevent pages from being indexed, as search engines are only able to index the pages they know about. While a page may be indexed due to links pointing to it from other pages, Google will aim to make the page less visible in search results.
- Search Console Remove URL tool: The URL removal tool within Google Search Console is a quick and easy way to temporarily remove a URL from Google’s search results.
Identify and monitor your noindex robots.txt pages
Ahead of the support for robots.txt noindex directives ending on September 1st 2019, the Noindex Pages Report in Lumar (via Indexation > Non-Indexable Pages > Noindex Pages) will allow you to check which of your pages are currently being noindexed and how. Within the list of noindexed pages you will be able to see where they have been noindexed: through the header, meta tag or robots.txt.
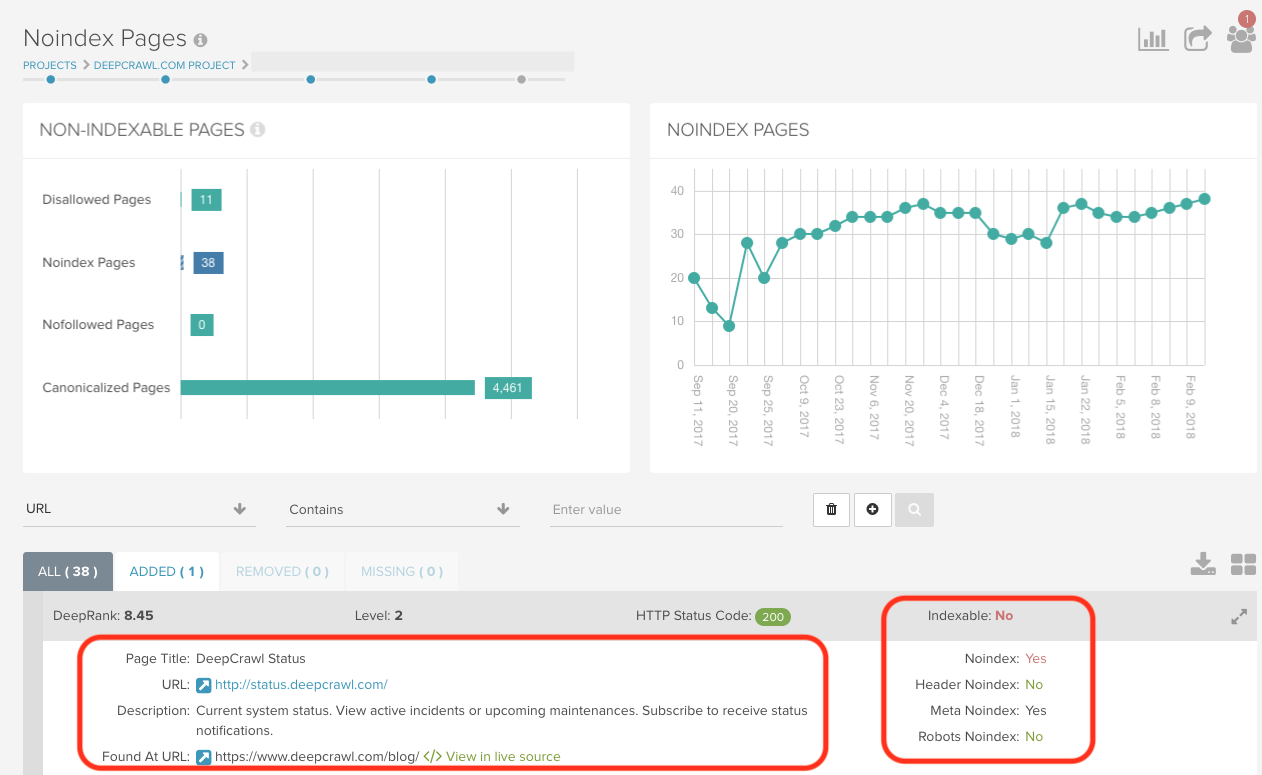
Discover this report, and over 200 others, by signing up for a Lumar account.
You can also test how your noindex directive is working in the Search Console testing tool, as you would with any other Robots.txt directive (in Crawl > robots.txt Tester).
Other changes to Robots.txt
This update is just one of a number of changes coming to the robots.txt protocol as it works towards becoming an internet standard. Google have explained these further in their updated robots.txt specifications document on the Google Developers blog.
Want More Like This?
We hope that you’ve found this post useful in learning more about the update to the robots.txt noindex protocol to control the crawling of your site.
You can read more about this topic in our Technical SEO Library guides about URL-level Robots Directives and Robots.txt.
Additionally, if you’re interested in keeping up with Google’s latest updates and best practice recommendations then why not loop yourself in to our emails?




