

This week’s Lumar webinar is a dive into smart SEO crawling strategies. In particular, we’re looking at how Lumar can be used for efficient and effective flexible website crawling.
Senior technical SEO Chris Spann is joined for this session by solutions engineer Jeremy Kao. Together they have a wealth of knowledge about using the Lumar platform to run crawls on websites – large or small – from any sector imaginable.
Watch the full SEO webinar above — including audience polls and Q&A session — or read on for our key takeaways from the presentation.
Crawl scope, frequency, and data sources
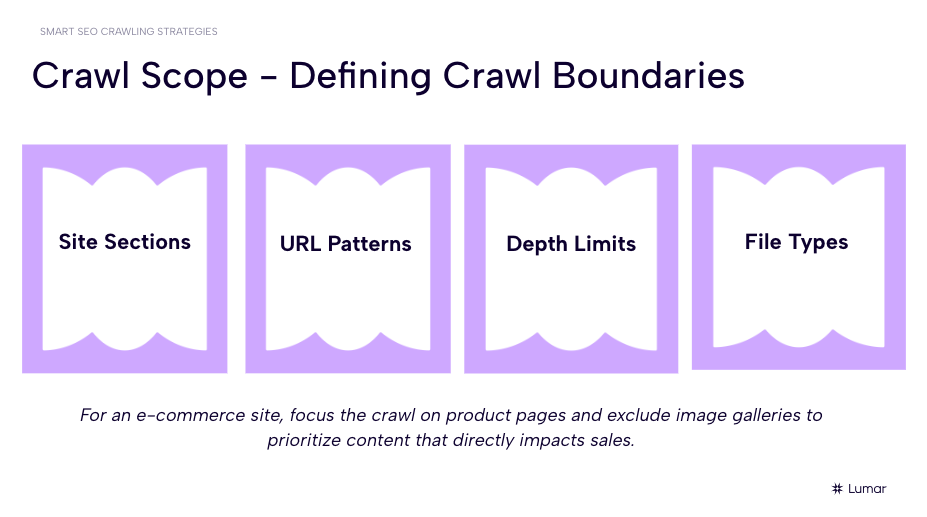
Establishing your crawl scope
When determining your crawl scope, start with defining the boundaries. This means setting precise limits on the pages to be crawled.
“This step ensures that your crawl focuses on relevant areas of the website while conserving resources,” Kao explains.
For example, you might want to limit the scope of your website crawl by setting boundaries for the following attributes:
- Site Sections: It is vital to target specific sections of your site (for example, blog pages or product categories) to ensure the crawl is concentrated on your relevant SEO goals.
- URL Patterns: With Lumar’s website crawler, you can easily include and exclude certain pages in your crawl by filtering for specific URL patterns. This keeps the crawl targeted and refined, ensuring that resources are used efficiently.
- Page Depth Limits: Page depth refers to how many clicks from the homepage it takes to get to certain parts of your site. Kao notes that setting page depth limits on your crawls is about striking a good balance. We want to make sure the crawl is going deep enough to be useful, but not too deep that it is wasting resources on unimportant pages.
- File Types: You can also include or exclude different file types depending on your SEO objectives. For example, in e-commerce SEO, we might want to focus the crawl on product pages and exclude videos or PDFs to prioritize content that more directly impacts sales.
To keep your website crawls focused, you likely don’t need to crawl your entire site every time you run a new crawl. Full SEO website audits are important to run on occasion, but for your day-to-day SEO needs, it’s often more efficient to run more limited crawls that focus on extracting your key data.
“You don’t need to crawl 300 levels deep to know that you have a pagination problem,” says Spann, “You could probably work that out at 40 levels deep, or 30 levels deep.”
Crawl scope for enterprise-scale websites
When implementing SEO on extra-large enterprise websites, establishing the best crawl scope for your needs becomes even more crucial.
Spann gives an example of a large e-commerce auction site he works with — they have millions of product URLs that change daily.
“They have so many individual product pages that there are too many to really focus on. So their real SEO focus is on category pages. So as a default, we don’t go into product pages for them too often and we just spend our time on category pages because there are still plenty of those; there’s more than enough to access there,” he explains.
Working on an auction site with short-term product availability, ever-changing stock, and product pages that are created and sunset rapidly, Spann notes that: “It’s very rare that their product pages rank particularly well [due to the short timeframes involved with auction products], so we may as well focus on the more evergreen pages that are going to be sticking around.”
Focused SEO crawls and setting exclusion criteria
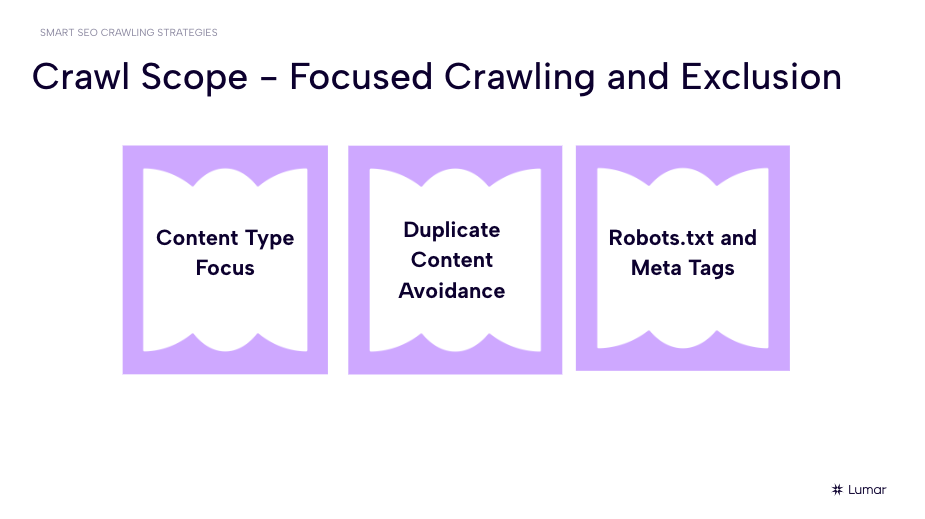
Next, Kao and Spann dig into how focused crawling can target specific content on your site and the importance of setting crawl exclusion criteria to omit irrelevant or duplicate content.
Content type focus
When designing your website crawl around specific content types, you’ll want to align the content you include in your crawl to your broader business goals.
Kao gives the example of implementing SEO on a news website — in that case, you may want to limit your crawls to focus on your article pages or forum pages that are really your business’s bread and butter. If your news site primarily focuses on a certain topic or beat, you may even want to limit your crawls to focus on articles that fall within that subject area. Or you may want to focus on the articles that generate the most traffic and engagement.
Duplicate content avoidance
You may also want to set up your crawls to skip over pages that contain duplicate content from other pages to save on your crawl resources.
If your initial full site crawl identifies numerous duplicate pages on your site, you can choose to exclude those duplicate pages from subsequent crawls.
“This way we’re not wasting crawl resources by crawling the same thing over and over,” says Kao.
Guiding crawlers with robots.txt and meta tags like nofollow, noindex, or disallow
Many SEOs use robots.txt directives and meta tags like nofollow, noindex, and disallow, to guide search engine crawlers away from irrelevant or sensitive areas of their websites.
“By default, Lumar will respect a robots.txt [when crawling your site],” says Spann, “Because out of the box, we’re trying to be as similar as a search engine crawler as we possibly can be. But it is often very interesting to crawl with an ignored robots.txt. Because, guess what? A search engine crawler crawling your site doesn’t have to obey robots.txt. So crawling your site with Lumar, with the option for ‘obeying robots.txt’ turned off, is a very good way of finding links to dev sites that shouldn’t have been left there, or links to sections of the site that shouldn’t be public and that you’re relying on a robots.txt to keep hidden.”
Crawl frequency
It’s important to understand which areas of your website require more frequent crawls — and which site sections can be left for monthly, quarterly, or ‘only when updated’ crawls. Creating crawl strategies that align with different crawl frequency needs can help your SEO team work more efficiently and save on valuable crawl credits and resources.
Spann gives the example of a news website that also hosts affiliate content related to credit card offers.
“Some of the US newspapers do it now. They will build a credit card deals page and that will change over time — but that content is going to change way less frequently and there will be fewer pages in that site section than there are in, say, the ‘US political news’ section of the site,” explains Spann.
“So this is where you start looking at it and going: ‘Right, well, what needs crawling daily or weekly? And what can we get away with crawling monthly, or maybe it only needs crawling every time there’s a new release.”
Knowing when to run crawls is vital too. Spann points to the importance of being aware of when your site is busiest and not running crawls then.
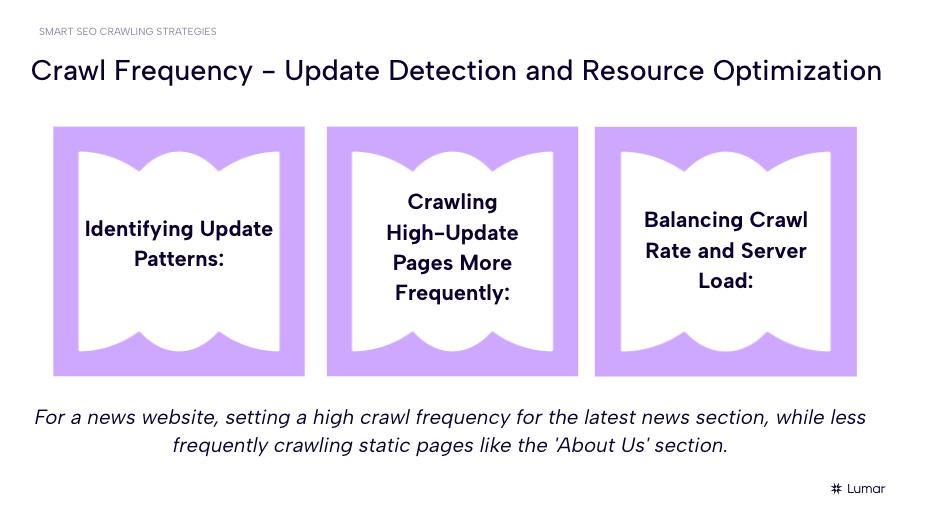
When establishing how often you will run SEO crawls on your website, you may want to consider:
- Which site sections are updated most frequently? (For site sections that are updated daily, you’ll want to run more frequent crawls.)
- When does your site get the most traffic? (Schedule crawls for off-peak hours.)
- How does seasonality affect your business? (Crawl more often during times of the year that are most crucial for your business so you can catch any issues that may impact your traffic during these important months.)
Content prioritization for SEO crawl frequency

Spann reflects on his time working in-house for a travel website. He notes how they learned to crawl pages such as ‘Flights to Spain’ frequently as these were high-traffic, high-conversion pages that also saw a lot of developer work. Their ‘Airport Parking’ pages would be crawled much less often due to these being a lower ROI part of the site.
Crawl data sources
Kao points to the importance of having multiple data sources for our website crawls. This is crucial for building a comprehensive SEO strategy.
“[Having multiple data sources for your crawls] ensures a well-rounded and in-depth understanding of your site’s performance and potential areas of improvement,” Kao says.
“At Lumar, we use various data sources married into the web crawl data to make sure that you have full visibility — and also to make sure that these data sources can speak to one another and give you actual insights. In the realm of SEO, understanding the full scope of your website’s landscape is not just beneficial, it’s crucial.”
“We want to make sure we’re able to comprehensively look at the site, harness the power of all the different crawl data sources that we’re pulling in, and then feed that into the big picture of our SEO efforts.”
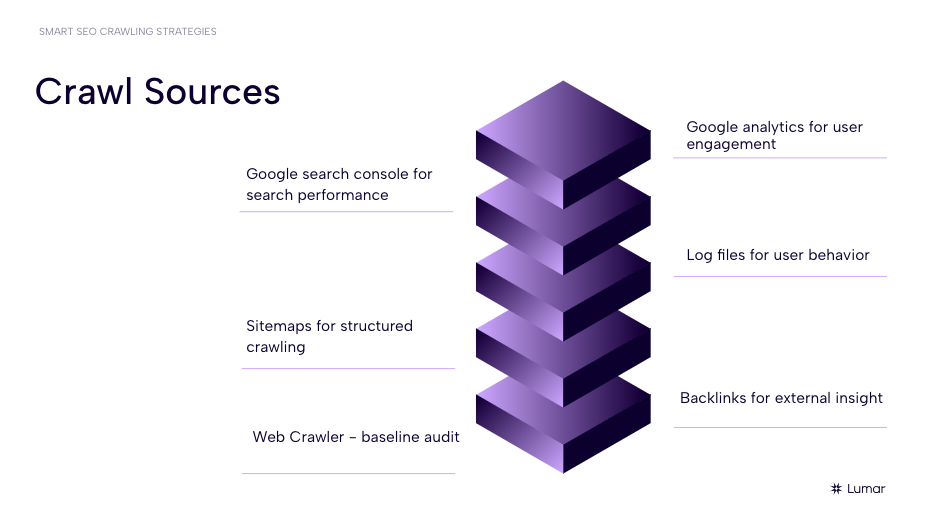
Some additional website data sources you may want to integrate into your website crawls include:
- Google Analytics – For user engagement insights.
- Google Search Console – For search performance insights.
- Log Files – For user behavior data.
- Sitemaps – For structured crawling.
- Backlinks – for external insights.
And of course, you’ll need a great website crawler to run your baseline audit.
Spann notes that large enterprise websites sometimes don’t know what their focus pages should be from an SEO standpoint. Running comprehensive crawls with multiple data sources can help SEO teams figure out where to focus their efforts.
Past crawl data – leveraging previous crawls and learning from past patterns – is useful, too. This feedback loop ensures our crawls are refined and relevant going forward.
Parity crawls
What is a parity crawl in SEO?
A parity crawl is when you crawl, analyze, and compare different versions of a website to ensure consistency or equivalence.
Parity crawls can help SEO teams get a fuller picture of how their website behaves and performs across different devices, website versions, or between staging and live sites.
Types of parity crawls you may want to run:
- Mobile vs. desktop parity crawl
- Staging vs. live site parity crawl
- User agent parity crawl
- Language or geolocation parity crawl
When should you run a parity crawl?
When comparing the crawls, you may want to check elements of your website’s health and performance such as:
- Checking that content renders consistently across platforms or devices
- Functionality is equivalent across different device types
- UX is optimized for both mobile and desktop
- Load time analysis across device types
- Checking the live site matches the staging site post-update or post- website migration
Creating custom extractions for your website crawls
Have you ever wanted to extract specific information from your website, at scale, without being limited by the built-in metrics and reporting options from your crawler?
Lumar has you covered. With Lumar, you can easily build your own custom data extractions to pull just about any information you’d like from your website crawls.
For a real-world example, Kao points to a US-based pharmaceutical company that required an ISI (“Important Safety Information”) element on every drug page on their site as a legal requirement. Lumar’s custom extractions can be used to crawl these product pages at scale to ensure that every page that needs an ISI has one in place.
“I could talk infinitely about. Custom extractions and, good was more specifically custom JavaScript, which is where things get really, really exciting,” says Spann.
“Custom JavaScript gets really exciting because we can then start doing strange things to pages — we can remove page sections and see how well things get crawled. Elements of pages… we can just strip them out.”
“Or you can do interesting things like counting the number of certain elements on a page. So if you have a theory that pages with X or Y particular content type on them rank well… we can count those elements and can show you where those content types exist on pages [across your site].”
While the Lumar platform includes hundreds of built-in reports for technical SEO metrics and website accessibility metrics, users are not limited to crawling their sites for only these metrics — personalizing the data you’re pulling out of your site crawls with custom extractions is a major boon for SEOs and website managers using the platform. Using regex, Lumar users — like the pharma website managers in Kao’s example — can extract the exact information that meets their unique needs.
Along these same lines, using different regional IPs in your crawls is another part of the Lumar tool kit – giving you access to region-specific views of your website data, allowing you to analyze local search results, and making it easier to customize your international SEO strategies based on specific locales.
Crawling staging sites vs. live sites
Being able to crawl both the staging and live versions of our sites is a great way to evaluate changes and identify potential SEO errors promptly (ideally pre-launch). It also helps with SEO impact forecasting and SEO value protection.
Lumar’s Protect app also helps SEOs and developers prevent SEO mistakes before website updates go live with automated SEO QA testing.

Lumar SEO platform highlights
To sum things up, Kao refers back to Lumar’s flexible crawling capabilities as being a real highlight of the platform:
“Making sure that we can pull together not only your web crawler data,” is a major highlight in the Lumar platform he says, “But also marrying that data with things like sitemaps, backlinks, GSC, GA, log files, or any specific URL list that you want to amend — thereby giving you those deep insights and making sure those data sets can speak to one another.”
Being able to draw these various data sources into scheduled website crawls (alongside any custom extractions you’d like to add) and running crawls across both live sites and staging environments helps SEOs be in the best position to create their most efficient and effective SEO strategies in 2024.

Meet the SEO Experts
- Jeremy Kao, SEO Solutions Consultant, Lumar
- Chris Spann, Senior Technical SEO, Lumar
Register now

Don’t miss the next Lumar webinar!
Sign up for our newsletter below to get alerted about upcoming webinars, or give us a follow on LinkedIn or Twitter/X.
Want even more on-demand SEO webinars? Explore the full library of Lumar SEO webinar content.





