

SEO is crucial for publishers because a large proportion of traffic to news and media websites comes via search engines. Whether you are a publisher that operates within a specific niche or a publisher that covers news nationally, there are common SEO challenges that can impact your company’s organic growth if not dealt with appropriately.
Having worked across a range of publishers and news websites, I’ve come across a number of SEO issues that re-appear on a regular basis, as well as interesting technical issues that are just worth sharing.
Common website issues & optimization tips for publishers:
- Category page optimization
- Over and underutilization of tagging
- Lack of evergreen content
- Wrong articles ranking due to content syndication
- Cannibalization of articles due to annual listicles
- Poor crawl paths to old content
- Lack of RSS feeds
- Parameters on internal links
- XML sitemaps
- Org name mismatch
- AMP vs non-AMP page setup
- Missing meta tags for Google Discover
- Cumulative layout shifts
- Incorrect paywall setup
1. Category page SEO issues
Category pages are an important stream of organic traffic to publisher websites, mainly because these templates can rank well for head terms with large search volumes, such as celebrity news, tech news, and news in [location].
More often than not, category pages on news websites are not optimized to their full potential, meaning publishers are leaving traffic on the table for their competitors. In the example below, the metadata is optimized for the term “celebrity news” as that has the highest search volume. However, search terms such as “celebrity gossip”, which serve the same SERP intent and templates, are missing—making it harder for this page to rank towards the top of the SERP results.
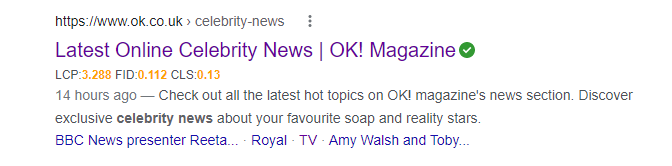
Keyword research is very useful to help identify other relevant keyword variations that users search. Following keyword research, it is important to review the SERPs to see if the same category pages are ranking for different keyword variations or if different pages rank.
2. Over- and under-utilization of tagged pages
Tag (or topic) pages are very common as they can be a useful way to organize multiple articles on the same theme. Incorporating tags in articles allows both users and search engine crawlers to discover related articles on that topic, which helps boost internal linking efforts, relevancy, and user experience.
These tag or topic pages can often begin to successfully rank for organic search terms that include the ‘topic name’ combined with ‘news’ terms (i.e., ‘x topic + news’).
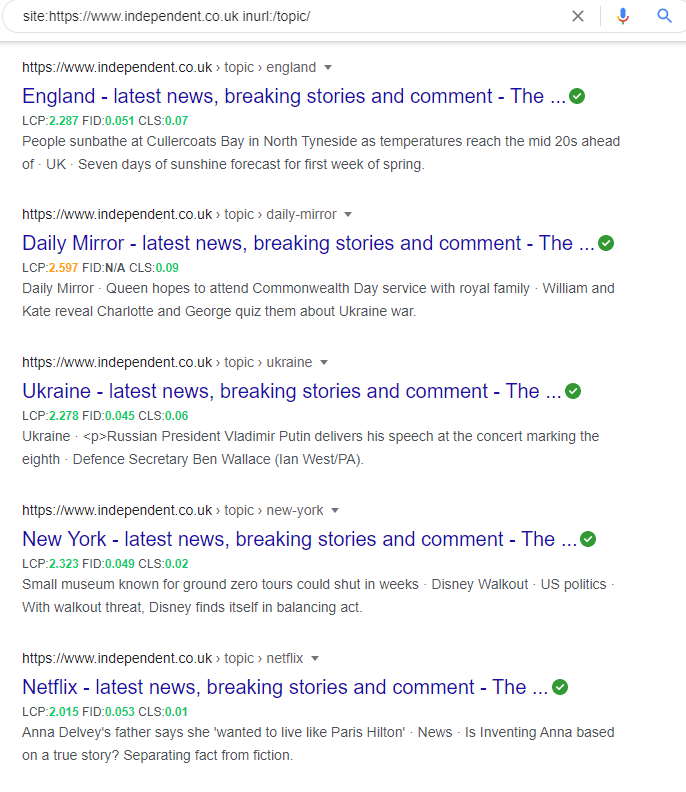
However, precautions need to be taken when creating a topic or tag pages on a large publication’s website. One of the key issues with tag pages is maintaining consistency. For instance, one article being tagged as “movies” and a similar article a week or two later being tagged as “movie news”. This slight nuance can cause multiple tag pages to be created for the same topic, which, when applied across the whole publication, can result in large numbers of duplicate, thin, and low-quality pages.
Publications can create too many tag or topic pages on their website, which could have an impact on their crawl budget. Historically, I’ve seen this happen due to there being no processes in place for tag management and due to editors being given the ability to create and add any tag to a given article—resulting in 1,000s of tag pages being generated, many of which do not provide much value (particularly if the tag is essentially a duplicate of another tag, just worded slightly differently). When these pages are created on a large scale and are not maintained, nearly empty pages will begin to appear. Rules should be in place within your publication to prevent empty or very thin pages from being created or indexed by search engines.
3. Lack of evergreen content
For lots of publishers, especially news publishers, the focus will be on real-time news events and producing articles that will have a short shelf life. This means organic traffic can be very erratic, unstable, and media websites will sometimes struggle to see YoY traffic growth.
More and more publishers are now investing in evergreen content; I have seen this firsthand over the past few years. The main reason for this is that evergreen content can provide more consistent year-round organic traffic and offers longer-term value compared to articles that are relevant only for a short news cycle.
Publishers should find their niche and conduct in-depth market research to uncover evergreen topics and keywords that users are searching for. Once the research has been completed, a comprehensive content plan along with supporting SEO playbooks should be built out for the year so that evergreen content can be created in the background on an ongoing schedule, alongside real-time news stories.
It is important that evergreen content can be easily found within the website, as these articles can quickly get buried within the website architecture when there are many news stories being written and published to the site daily. Building out creative internal linking modules on category pages and on article pages can help evergreen content to be discovered by both users and search engine crawlers.
4. ‘Wrong’ URLs ranking due to content syndication issues
Content syndication is when the same piece of content has been republished across multiple websites. This typically occurs with publishers who have a network of publications within their portfolio and articles get pushed out across all relevant publications with the intention of broadening the reach.
Google’s own webmaster guidelines suggest that they will always try to show the most appropriate article to users but it might not always be the preferred version. Duplicating content across multiple sites via syndication may lead to keyword cannibalization issues, but, strictly speaking, syndicating content is not against Google’s guidelines (as long as it does not manipulate their rankings and is not syndicated in a way to deceive users).
One common issue publishers see related to content syndication practices is when the ‘wrong’ publication in the portfolio is ranking for a news story that would be better suited to a different publication on the syndication network, or the wrong/secondary publication is outranking the original article.
It is recommended that syndicated pieces of content refer back to the original or primary version of the article through an on-page link to prevent sending confusing signals to crawlers.
Other solutions that can help the primary article rank above the secondary syndication sources include:
- Add on-page text copy and an anchor link that references the original version of the article i.e., ‘This article first appeared on x-publication.’.
- Embed a rel=canonical tag into the HTML of the duplicate versions of articles that references the original source (the primary URL that you want to rank for a syndicated article).
- Add a noindex robots meta tag within the HTML of the duplicate articles to restrict Googlebot from indexing syndicated content on Google News and Search. (.g., <meta name=”Googlebot” content=”noindex”> ).
5. Cannibalization of article keywords due to listicles
Listicles are a common content type, especially on the commercial content side of publisher websites. Listicles can cause a lot of keyword cannibalization for a media site if there is not a clear content strategy in place and regular content reviews.
When it comes to search engine optimization for listicles, there are several things to keep in mind:
Numbers included in URL
A lot of the time a listicle will be numbered and content editors will include the number of items in the listicle within the URL structure. This is not optimal because if you want to extend the list in the future, the URL will no longer align with your title or the number of items shown on the listicle page. In this scenario, editors will either update the article and keep the URL as-is, or create a brand new article with an updated URL that reflects the new number of items included in the listicle. But when an editor creates a brand new article/URL, more often than not, they won’t 301 redirect the old listicle to the new one.
Having two or more listicles targeting the same keyword, but with different numbers, usually causes URL cannibalization in the search results and is not the best use of anyone’s time. For example:
- http://www.example.co.uk/15-best-wall-clocks.html
- http://www.example.co.uk10-best-wall-clocks.html
Ideally, URLs should not include the number of items in the list as this will enable editors to continually update the article.
Keyword variations used in the URL
Keyword cannibalization can occur when publishers have two or more articles listing the same products, but use a different keyword variant to describe the same product. For example, running shoes and running trainers. When conducting SERP analysis on Google, the top results are the same whether someone searches for “running shoes” or “running trainers”. An example:
- https://www.example.co.uk/10-best-running-trainers.html
- https://www.example.co.uk/the-10-best-running-shoes.html
It is important that keyword research and SERP analysis is undertaken before creating multiple listicles that target similar keywords in order to see if search engines are serving the same or different articles in the top 3 positions for both keyword variations.
Dates or years included in URL
Listicles are usually created or updated yearly, but there will be times when editors include the original year within the URL. There can be the odd occasion where it makes sense to include the year or date in a URL, but most of the time it should not be included as it limits the article’s future and means you’ll have to start from scratch to optimize a new page for the next year’s version of the listicle, rather than building off of previous years’ rankings. For example:
- https://www.example.com/posts/best-jokes-2020
- https://www.example.com/posts/best-jokes-2021
6. Poor crawl paths to older content
For publishers, their most recent news articles will always take priority as they are naturally dedicated to reacting to current news events in real-time. However, older news articles or more evergreen content pieces can get buried deep into the website’s architecture when there is not a clear crawl path for search engines (or users) to access the older content. It is important to create a clear path to older articles, as these articles can still contribute significantly to overall organic traffic.
Publishers take different approaches on how to combat this issue, which include:
- Creating category or topic pages just listing the most recent content and then relying on XML sitemaps for other articles.
- JavaScript “load more” buttons to uncover older articles.
- Series of paginated pages with hardcoded URLs
- Creating an ‘archive’ section of their news site that houses all past articles published across the website.
JavaScript “load more” buttons
A common technical approach for websites with a lot of articles or posts is to include a “load more” button at the bottom of the category or topic pages to uncover older articles.
However, most of the time the “load more” button is not crawlable by search engines due to JavaScript rendering issues resulting in older articles still not being easily found by crawlers. This is because search engines such as Google are not able to click on buttons, but they can follow links. Most of the time the “load more” button is literally just a button with no URL associated with it.

Pagination series
Another approach used for directing users and search engines to older articles is pagination. This is when a page includes a paginated series of links at the bottom of the primary content on that page where hardcoded links with URLs reference the ‘next’ and ‘previous’ pages in the sequence. For example:
https://www.example.co.uk/news/live/business/page/3
and
https://www.example.co.uk/news/live/business/page/4.
This setup is optimal, as all pages can be found via the crawl path links, resulting in older articles being found by crawlers (and users!). The sequence should at least reference the next, previous, and last result page, but ideally, also reference the next few result pages in the sequence in order to reduce the crawl depth of the website.


Archive pages
An archive page can also be used to house older articles once they fall off the first page of a site section dedicated to a specific content category or topic. This setup enables crawlers to find older content in an accessible way without content becoming orphaned pages (that is, having no internal links pointing to its URL).
There are different ways to order an archive by date or taxonomy. There is no real right or wrong way to implement this, but you want to ensure that, however you set up an archive section, the setup does not generate a large volume of near-empty pages (see the above section on ‘thin page’ issues relating to tag pages).

7. Lack of RSS feeds
When setting up a Google Publisher account and listing the different sections within “content settings”, publishers have the option to use feeds (RSS or Atom), web locations, video, and personalized feeds.
In the past, when publishers have relied on web locations for content to appear, issues have consistently occurred, such as:
- Content not always being pulled through due to their category pages being heavily built using JavaScript.
- Content not appearing quick enough in Google News.
- Outdated content appears at the top of the publisher’s news feed.
- New articles are not being shown in Google News.
Updating sections to RSS feeds from web locations has proved to be a lot more reliable in showing a publisher’s latest content in Google News. RSS feeds have also enabled sections to be set up for publishers when their category pages are built with JavaScript.
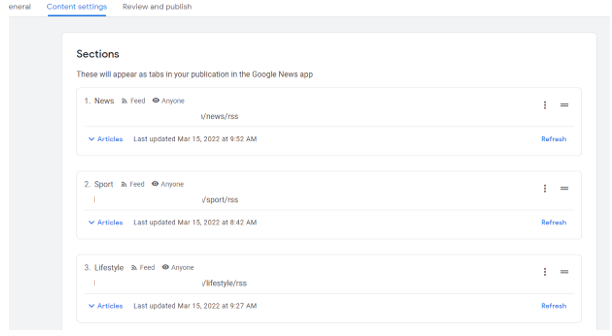
8. Parameters on internal links
Most publishers will include internal linking modules across their website to help with UX and SEO. The most common linking modules you will typically see on media and news websites include:
- Editor picks
- Most popular
- Trending articles
It varies across websites on how these modules are set up, but a common issue that appears across numerous publishers is when their internal linking modules include parameters at the end of each URL. For example:
- https://www.example.co.uk/news/politics/article-name?ico=editors_picks
- https://www.example.co.uk/news/politics/article-name?ico=most_popular
- https://www.example.co.uk/recommended/article-name?itm_source=parsely-api
These URLs will not typically cause duplication issues, as the parameter article URL will canonicalize back to the clean URL. However, on a large scale, this can waste crawl budget as a search engine will crawl the parameter URL first to uncover the canonical tag and then crawl the canonicalized URL version.
Ideally, internal links should not include parameters and all internal linking modules should link to the canonical URL version.

9. XML sitemap issues for news websites
Sitemap Issue 1: Caching on XML news sitemaps
This issue is not too common, but it was an interesting technical issue that has appeared in a past project I’ve worked on. In this project, caching on XML news sitemaps prevented new articles from appearing in Google News in a timely manner. As we all know, time is of the essence for media companies and news articles need to be pushed to Google as quickly as possible!
Make sure there is no caching in place on your news XML sitemap, otherwise it can prevent your latest articles from appearing in Google News for a number of hours (depending on the cache time frame in place).
Sitemap Issue 2: ‘Last modified’ date mismatch
There have been occasions where the “last modified” date of articles in XML sitemaps have not matched with the “last modified” date on articles themselves. This can send conflicting and confusing signals to search engines, as it makes it difficult for a search engine to know when an article was last updated. John Mueller has previously mentioned that the last modified date is a small signal to aid the re-crawling of URLs and, if modified dates are inaccurate, search engines may ignore the date specified when re-crawling URLs.
Sitemap Issue 3: XML sitemap structure
Breaking down XML sitemaps in a granular manner won’t necessarily aid the indexation of a website, but it can be very useful in diagnosing technical issues across a publication’s website with a vast number of URLs.
When a publisher I worked with faced a large number of indexability issues (out of 500,000 URLs submitted in their sitemap, only 150,000 URLs were indexed), it indicated that there was a technical issue on their website—but initially, we were not sure what the issue was. Due to their XML sitemaps not being broken down in a logical manner (as detailed below), it made it very difficult for us to pinpoint which sections of their website faced indexation issues until a large-scale technical audit was conducted.
Poor examples of XML sitemap URLs:
- http://www.example.co.uk/sitemap_article.xml?p=3
- http://www.example.co.uk/sitemap_article.xml?p=4
Ideally, XML sitemaps should be split up by the different website sections. For example, all URLs that run off the path “Entertainment” should be placed in an entertainment XML sitemap. Here’s a better example:
- http://www.example.co.uk/sitemap_entertainment-article-1.xml
- http://www.example.co.uk/sitemap_entertainment-article-2.xml
10. Organization name mismatch in Google Publisher Center
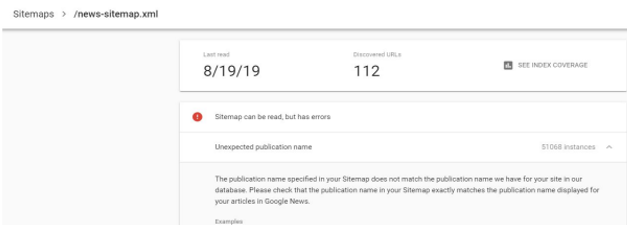
It is important that the organization name used in your XML sitemap or within your Schema markup is the same name used in Google Publisher Center. If the organization name is not identical, it can result in indexing issues and consequently affect AMP and Rich Result performance within Google News.
A publisher I worked with faced this issue when going through a CMS migration and their organization name in their new XML sitemap no longer reflected the same name that was listed in their Google Publisher Center account. An error appeared in Search Console highlighting the inconsistency. This resulted in poor indexation and their news articles not appearing in the ‘top stories’ carousel or within Google News until their organization name in Google Publisher Center was updated to match the new XML sitemap.
11. AMP vs non-AMP pages
AMP Issue 1: AMP version of a page has differing structured data from non-AMP version
When auditing drops in AMP article traffic, I have seen scenarios where a drop in traffic occurred due to the structured data on the non-AMP article being different from the structured data on the AMP article and preventing the AMP article from ranking.
Structured data should be mirrored across both the AMP and non-AMP articles—otherwise, it may affect rankings.
For one publisher, they saw a drop in traffic to their AMP articles because the non-AMP version of their article included @type NewsArticle, whereas the AMP equivalent included @type BlogPosting. In this scenario, the incorrect article type was also being used in the AMP version, because for all news articles, the “NewsArticle” type should be included.
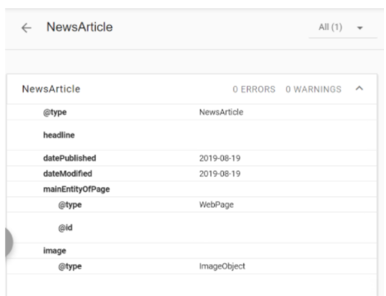
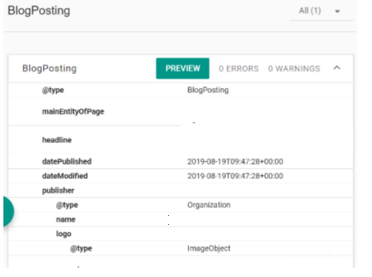
AMP Issue 2: AMP page not canonicalizing to non-AMP version
Publishers who use AMP across their articles need to ensure that the AMP URL canonicalizes to the non-AMP URL. If the canonical is not correct it invalidates the AMP setup because AMP URLs cannot include a self-referencing canonical tag. When auditing publisher websites over the years, this issue does appear fairly frequently and has a knock-on effect on mobile traffic.
12. Missing meta tags for Google Discover
This is a fairly new issue faced by media websites, but publishers who are missing the “max image preview” tag on their pages could be hindering their content’s performance within Google Discover. In 2021, Google published two case studies that showed a dramatic increase in traffic as a result of adding the “max image preview” directive to articles.
The main reason why this meta tag can improve a page’s search performance is that it tells Google what size image to show in the preview. As Google Discover is a very visual platform, it is important that a large image is displayed alongside articles, as it can result in an increase in click-through rate (CTR).
This is the meta tag that needs to be added:
<meta name=”robots” content=”max-image-preview:large”>
13. Cumulative layout shifts (CLS)
Layout shifts can be a common issue across publishers’ websites. When cumulative layout shifts (CLS) happen, it can impact the user experience as readers will usually get frustrated and distracted. This mainly occurs due to the setup of display advertisements across the website or due to fonts or images being loaded.
CLS issues with advertisements
Advertisements have been the most common reason for CLS shifts because they are usually loaded after the initial paint of the page via JavaScript. A lot of publishers do not reserve space for their advertisements to load, which results in a large shift where the article gets pushed down the page to cater for the advertisement to load. To combat this issue, white space needs to be reserved using common advertisement slot sizes when the page first loads in order to prevent any layout shift.
CLS issues with fonts
Downloaded web fonts can cause what’s known as a “Flash of Invisible Text” (FOIT) or a “Flash of Unstyled Text” (FOUT). This can trigger a small layout shift that impacts the usability of the page when it initially loads.
To prevent this from happening, it is recommended to preload the web fonts required on a page by using rel=”preload” in the link for downloading the web font.
CLS issues with images
When images are loaded, they can also cause a slight layout shift depending on how they are being served and rendered. This mainly occurs because dedicated width and height attributes have not been added to the images. Adding width and height attributes to images can prevent the layout from shifting.
14. Incorrect paywall setup
It has become common for lots of publishers to implement paywalls across their websites over the years. This essentially means that content is gated and usually can only be viewed if a user has subscribed to view the content. The two most common paywall setups are “lead-in” and “metered” paywalls.
The most common SEO issues publications run into with paywall set-ups include:
- Paywall structures that do not allow search engines to view the hidden content
- Not including the correct schema markup in the source code
- Allowing the cache to be available in the SERPs
Paywall Issue 1: Not allowing search engines to view the hidden content behind paywalls
Some publishers will go with the “lead-in” approach for their paywalls, where a small excerpt of the article is shown on the front end. However, the main issue with the lead-in paywall approach comes when the same small amount of content is also shown to search engines. The paywalled content will struggle to rank well in this situation, as search engines will have access to only a small sliver of that page’s content to assess and rank.
Ideally, publishers should show a small amount of content to users — but show the whole article to Google, as this gives the article its best chance to rank. If the paywalled content is hidden from users but accessible to search engines, then it can still be properly evaluated and ranked in the SERPs, despite only a small excerpt being shown to human users.
Paywall Issue 2: Not including the correct schema markup on paywalled content
It is important that the correct paywall schema markup is in place to signal to search engines which parts of the article are behind a paywall for human users Schema markup will help search engines recognize that the content is not being “cloaked” and instead is just behind a paywall. Missing the paywall schema markup can put your website at risk for penalties as it will look to Google like content cloaking.
To prevent this from happening, make sure your hidden content on a paywalled page is marked up appropriately. Google has put together documentation on how to markup your paywall content correctly.
Since a website’s premium content is not visible to non-paid users, but is visible to Googlebot, it technically meets the definition of “cloaking” unless the paywall markup is properly in place. “Cloaked” content is viewed negatively by Google, so you’ll want to avoid that.

Paywall Issue 3: Cache for paywalled content available in the SERPs.
Publishers go through a lot of effort to set up a paywall across their website and prevent giving away their content for free. However, a common thing that is missed on paywalled content is disabling the cache that Google stores and shows in their SERPs. If the caching of a page is not disabled, users can still see the hidden content for free, more often than not.
To prevent this from happening, the meta tag <meta name=”robots” content=”noarchive”> should be added to the head of each article.
Due to the unique nature of media industry websites, there are plenty of SEO issues that commonly affect news publications’ websites — issues that other industries may not encounter to the same degree. As you can see, there are quite a few specific optimization efforts that publishers need to keep in mind if they want to rank well in the search engines. By sharing the common issues that I have experienced on these sites over the years, I hope you will be better equipped to understand the factors that contribute to your publication’s rankings—and have the knowledge you need to overcome these issues if you encounter them.



