

We were very excited to welcome Dawn Anderson, Managing Director at Berty and DeepCrawl CAB member, to our webinar this month. Joining our host, DeepCrawl’s CAB Chairman, Jon Myers, Dawn explored what natural language processing is and how it can be used to help understand search intent. She also debunked some theories and myths being shared about Google’s BERT update.
We’d like to say a big thank you to Dawn for her great presentation and for taking the time to share her knowledge with us, as well as to Jon for hosting and all those who attended.
You can watch the full recording here:
What BERT really is
BERT was rolled out by Google in October 2019 as their latest algorithm designed to help better understand searches, both in terms of the query and content. However, it’s important to remember that BERT is many things, not just a Google algorithm as we know it. BERT is also an open-source research project and academic paper that was released in October 2018. An acronym for the framework called Bidirectional Encoder Representation from Transformers, BERT is a machine learning model used to consider the text from both sides of a word.

BERT has become important recently because it has dramatically accelerated natural language understanding for computers. One form of BERT, known as Vanilla BERT, provides a pre-trained starting layer for machine learning models performing natural language tasks, and allows the framework to be fine-tuned in order to continually improve.
As it has been pre-trained on over 2.5 million words from the whole of the English Wikipedia database, BERT takes the heavy lifting out of the task of manually building datasets for machine learning and natural language processing models. As well as being pre-trained on Wikipedia data, BERT has been fine-tuned with ‘question and answer datasets’.
What challenges does BERT help to solve?
There are a number of challenges that BERT is being used to help solve, one of these is looking at language and the problem that words can cause. This is because words are voluminous, while also being ambiguous and polysemous, with many different synonyms for the same word.For example, the word ‘run’ has over 600 possible meanings.
So, with more content continuing to be generated, words are becoming more problematic and harder for computers to understand. Along with this, the rise of conversational search had led to issues with understanding the difference between the meanings of words.
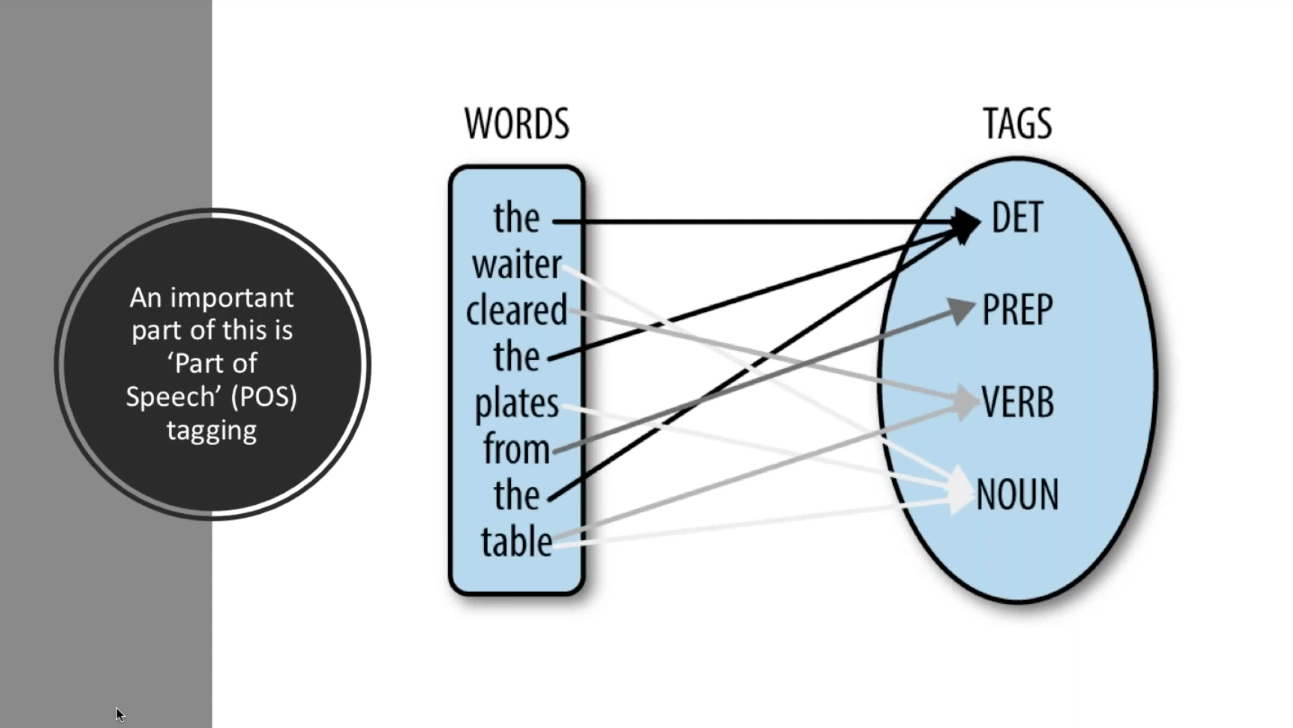
The big issue that BERT solves here is by adding context to the words being used. This is important because a word’s context changes as a sentence evolves and develops, due to the multiple parts of speech a word could be used in. One example of this is the word ‘like’. In the short sentence ‘I like the way that looks like the other one’, Stanford’s Part of Speech Tagger Online determined that the word like is considered to be 2 separate parts of speech, with different meanings.

Natural language recognition is not natural language understanding
Just because a search engine recognises a word, it doesn’t mean it will necessarily understand its context. This is because in order to gain an awareness of natural language, it requires an understanding of context as well having common sense reasoning.
This is something that is very challenging for machines, but is largely straightforward for humans. For example, as humans, we will look at factors such as the other words supporting a certain word, the previous sentence or who we are talking to in order to understand the context and therefore the informational need of a question being asked. However, a machine cannot do this as easily.
Natural language understanding is not structured data
Another important thing to remember is that natural language understanding (NLU) is not structured data. Instead it is used to understand all of the words in between the structured data entities. Essentially, NLU adds context to the words that join together all of the content within structured data.
Natural language disambiguation
As not everything that is mapped to the knowledge graph is used by search engines, natural language disambiguation is used to fill in the gaps between named entities. This is based off of the philosophy that “you shall know a word by the company it keeps” (John Rupert Firth, 1957). This is the notion of co-occurrence, which is used to provide context and change a word’s meaning.
There are two levels of co-occurrence:
- First level relatedness: Content that you would expect to see on the same page as each other, based on the topic, for example.
- Second level relatedness: Content that may be on a connecting page that is also shared with another connecting topic. This may be categories or tags on a site, where content is clustered together to help search engines understand what each topic is about.
Second level relatedness is particularly important when the content is ambiguous. For example, you wouldn’t expect to see an article about a river bank on a page about finance. Whereas if a page were about financial banks you would expect this to live on a page about finance.
This is why language models that are trained on very large text collections need to be tagged up by datasets using distributional similarity in order to learn the weights and measures of words and where they live near each other. BERT is used here to perform the tasks to train these models.
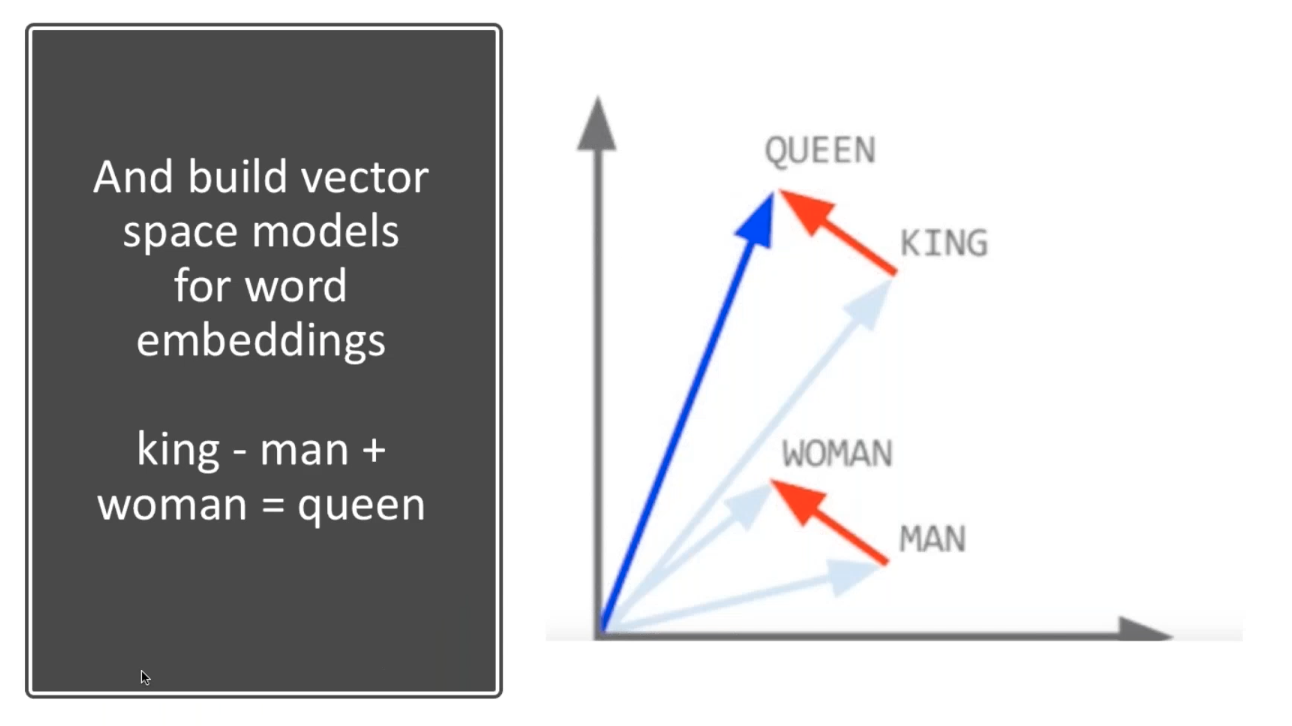
How BERT provides context
On its own, a single word has no semantic meaning, and even if search engines understand the entity itself, they still need to understand a word’s context. This is where BERT is used to provide ‘text cohesion’, in order to hold everything together. Cohesion is the grammatical linking within a sentence that holds the text together and gives it meaning. Without understanding the words around it, a single word could mean anything in a sentence.
Another important element of how search engines understand what different parts of a sentence mean is Part of Speech (POS) tagging.
BERT is made up of the following key components; Bi-directional modelling, Encoder Representations and Transformers. Dawn explored these in further detail;
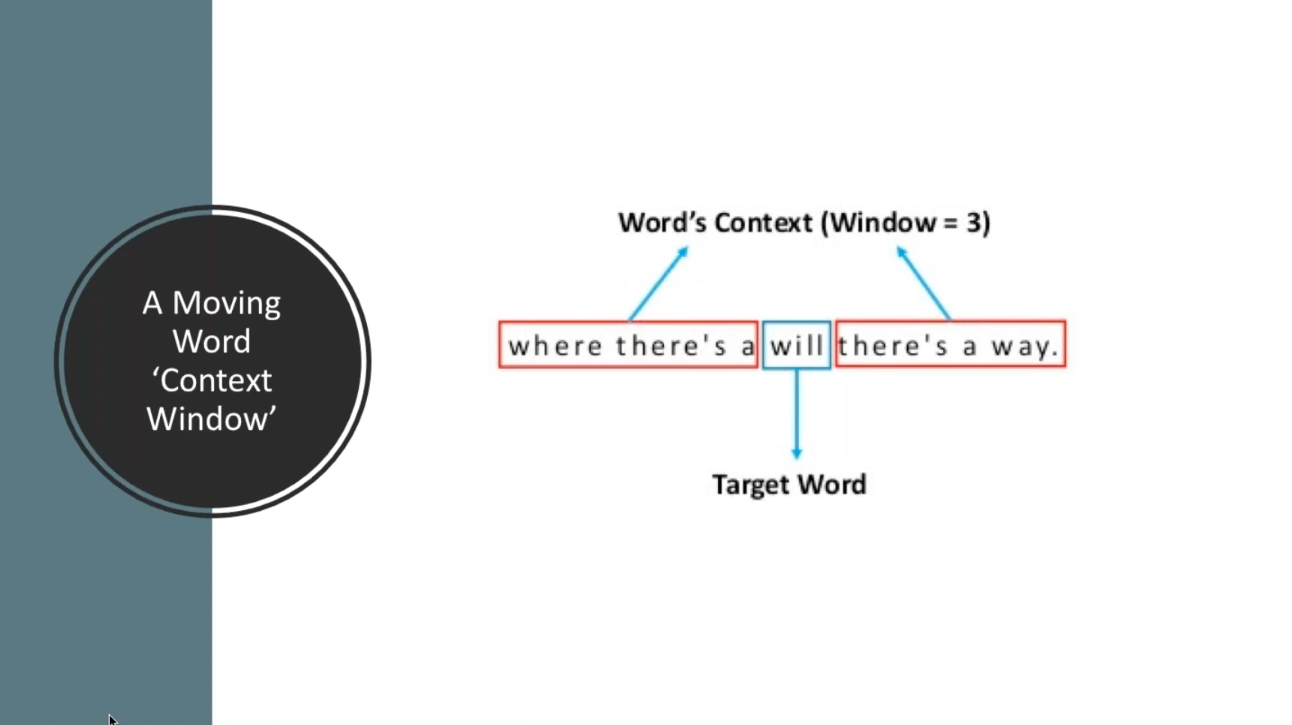
Bi-directional
The first thing to understand about BERT is that it is bi-directional, so it is able to use a moving word ‘context window’ to look at all of the words surrounding a target word, in order to add context to ‘context-free word embeddings’.
Unlike BERT, most language models are uni-directional meaning they can only move in one direction, either left to right or right to left, but not both at the same time. The problem with uni-directional modellers is that they will only take into account the words that have come before and not the words that come after, and this can make a big difference when understanding the context of a sentence.
By using bi-directional modelling, BERT is able to see the whole sentence on either side of a word in order to get the full context.

Encoder Representations
Encoder representation is essentially the action of sentences being fed into the encoder and decoders within model and representations coming out, based on the context of each word.
Transformers
Transformers are all of the layers that form the basis of the BERT model. They enable BERT to not only able to look at all of the words within a sentence, but also focus on each individual word and look at the context from all of the words around it, at the same time.
BERT uses Transformers and ‘Masked Language Modelling’ which means that certain words in a sentence are ‘masked out’ causing BERT to have to guess certain words.
 Natural Language tasks BERT helps with
Natural Language tasks BERT helps with
Since its release, BERT has helped to advance the State of the Art (SOT) of a number of natural language processing tasks, including;
- Named entity determination
- Textual entailment (next sentence prediction)
- Coreference resolution (understanding pronouns)
- Question answering
- Word sense disambiguation
- Automatic summarization
- Polysemy resolution (words which have different meanings)
Named Entity Determination
Search engines may still find it difficult to understand when a person or brand is being mentioned, particularly because named entities can be polysemic and have several different meanings. Named entity determination is all about correlating everything together in order to understand who or what is being spoken about in what context. BERT is able to extract these entities in unstructured data in order to understand them and therefore provide more relevant results for users.

Textual Entailment
In the action of a conversation, the next sentence makes a big difference as it helps to further convey the meaning. BERT is able to identify and understand which sentence is likely to come next from two choices in order to provide context for the conversation.
How BERT may impact search
BERT will help Google to better understand human language, and the more it understands, the more it will be able to self-teach and become better at understanding all of the nuances. This will lead to the ability to better scale conversational search, which is likely to advance voice search even further. Dawn also explained that BERT will provide big leaps forward for international SEO, as it enables Google to better understand ‘contextual nuance’ and ambiguous queries from the English language, of which a large percent of the web is built on.
Should you try to optimise content for BERT?
Dawn concluded the webinar by explaining that BERT is a black box algorithm, and even the model itself sometimes doesn’t know why it makes decisions. It’s also important to remember that BERT is more of a tool than an algorithm and, therefore, it probably isn’t the best use of time to try and optimise content for it.
Hear more from Dawn in our upcoming Q&A post
If you have any questions from the information that Dawn shared during her webinar, please tweet them to us using the hashtag #AskDawnA and we will collate all of the questions for a Q&A post.
Get started with DeepCrawl
If you’re interested in learning about how DeepCrawl can help you to identify technical issues on your site which are impacting both search engines and users, while also assisting with your optimisation efforts, why not get started with a DeepCrawl account today.



