

Semantic search has transformed the way search engines understand and serve web content today — and vector embeddings are at the heart of that transformation.
In this in-depth introduction to semantic search and vector embedding models, Matt Hill, a 15+ year veteran of the SEO industry, breaks down the core mechanics driving the shift to more contextual online search, focusing on the role of vector embeddings and how SEO professionals can adapt their strategies for today’s semantic search landscape.
We cover:
- What vector embeddings are
- Types of vector embeddings (sparse vs. dense)
- How vector databases work
- How semantic search uses vector models
- Vector mapping for SEO (with real-world examples!)
- The importance of optimizing website content today for semantic search, not just for exact-match keywords
Key Terms & Definitions: Semantic Search & Vector Models
| Semantic Search | Semantic search is the process of understanding the intent and meaning behind a search query — not just matching exact keywords — using techniques like vector embeddings and natural language processing (NLP). |
| Semantic SEO | Semantic SEO is the practice of optimizing web content so that search engines can understand its meaning and contextual relationships, not just its keywords, often by using structured data, topical depth, and related entities. It’s about aligning content with how semantic search actually works today. |
| Vector Embedding | Vector embeddings are sets of numbers that represent and categorize the meaning or features of complex data or objects (such as words, images, or entire books and webpages) using numerical values, making information easier to find and understand in context. In digital applications, each embedding can exist within a multi-dimensional vector space. |
Vector Mapping | Vector mapping is the process of converting real-world data into vector embeddings that can be placed in a vector space. |
| Vector Space | A vector space is a mathematical environment where vectors are embedded in relation to one another so that their relationships (like similarity or distance) can be measured using math. Essentially, a vector space is where vector embeddings “live,” allowing us to compare meaning, relevance, or context using geometry |
| Vector Database | A vector database is a software system designed to store, index, and search vector embeddings efficiently, especially at scale. |
Understanding vector embeddings
The Dewey Decimal System as a precursor to vector embedding models
I had the recent experience of being in the local town library before a meetup I was attending, and it got me thinking about those old paper catalog systems that I failed to really grasp as a child. You know – those long wooden filing cabinets, each filled with thousands of typewriter-printed, decimal-lined index cards? It surprised me to learn that this same retrieval system, an enigma of my youth, is still utilized today as a staple for library cataloging in 135 different countries.
A search engine in its own right, the Dewey Decimal System (DDC) is really a precursor to everything we have today. Rather than queries and SERPs, this classic search system uses unique decimal codes with numerical and non-numerical characters to make it easy to find what you’re looking for within a vast library of texts.
Each book’s unique library call number can also be referred to as an embedding — a numerical identifier that helps classify information into relevant categories.
In the Dewey Decimal System, the embedding identifies the location and features of a specific book.
For instance, the call number 940.18 RUN is the universal library shelf location for “History of the Crusades” by Steven Runciman.
I mentioned above that the call number is just an embedding, which is just a numerical identifier. But what is that identifier composed of in this example?
By dissecting the DDC embedding, you can see that there is actually a hierarchical flow of information.
- 900: History & Geography
- 940: History of Europe
- 940.18: History of the Crusades
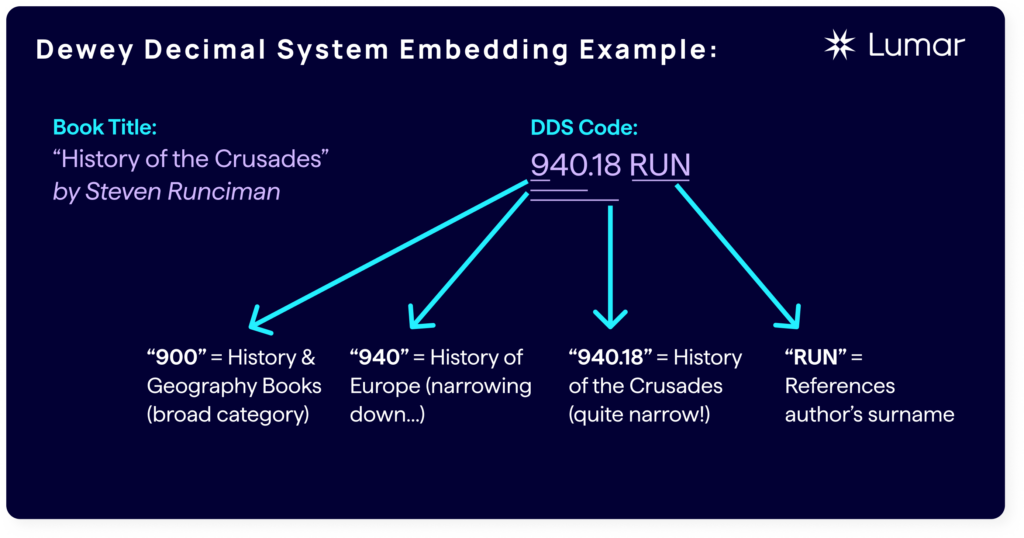
Comparing Runciman’s book title to the DDC classifications above, you see each of the first three digits corresponds to an increasingly greater relevancy to the topic, with the two characters after the decimal allowing for even further specification of the Crusades. Each character closest in proximity is a parent or child topic.
With the characters “RUN” appended as another identifier called a Cutter number representing the shorthand code of the author’s last name but is also the alphabetical location for that section. Other embeddings can be appended to the call number that are specific to the local library’s indexing system or modifications to the classification naturally evolve over time where deeper levels of specificity are needed.
Why has the DDC not come and gone like many other relics of the past? Well, the answer lies in that it was designed to be a living library. As the base classification system adds new content, there is no limit to the number of digits that can live after the first three characters and that could be referenced and searched from an index of millions embedding variations.
How vector embeddings are used in search today
Like the DDC numerical identifier concept above, vector embeddings used in search and LLMs today are essentially coordinates to an idea or topic, but within the multidimensional space of the internet.
In today’s hyper-competitive online search environment, with people giving their searches away to ChatGPT and TikTok, Google will continue its neural modeling in order to maintain a long shelf life in the data retrieval ecosystem space, just like the DDC.
Google’s AI Overviews, right now, are a very relevant example of the impact that newer vector embedding models are having on search behavior. But truly, this technology has been at play for a while for Google with the search engine’s attempt to focus on more natural language processing (NLP) models and away from models that encouraged spammy tactics and over-optimization. Google has now collected trillions of search data points across its product suite and core algorithm updates, such as Hummingbird and BERT, that allow for variations in language to be contextually taken into account.
Understanding vector databases and vector search
With all of this discussion around the evolution of search engines, it is important to remember that, at its core, Google search is just a program that simply calculates and ranks the outputs of those calculations. It’s a robot that still needs to turn blocks of text on web pages and in user queries into numerical embeddings for further calculation and categorization.
As a simple example of the types of basic calculations search engines are running behind the scenes to ‘understand’ web content and match it to user queries, we can look at the n-gram model.
N-grams refer to a more traditional method for understanding text patterns, often used before the widespread adoption of vector embeddings. They are contiguous sequences of words or characters used to analyze text.
N-gram example
For example, in the phrase “semantic search evolution”, you’d have the following n-grams:
- 1-grams (unigrams): “semantic”, “search”, “evolution”
- 2-grams (bigrams): “semantic search”, “search evolution”
- 3-gram: “semantic search evolution”
Using this method, Google’s database can store all of the keyword queries submitted based on overall volume, record the presence of individual keywords across the query list, and find patterns to assign an importance to each query.
SEOs usually learn about n-grams early in their careers as a part of understanding the simplified universal method of lexical retrieval using TF-IDF (Term Frequency-Inverse Document Frequency), a statistical equation for the weighing of results.
Key Terms & Definitions: TF-IDF
TF-IDF (Term Frequency–Inverse Document Frequency) is a traditional text analysis method that measures how important a word is to a document in a collection. It boosts the score of words that appear frequently in a page (term frequency) but downweights words that are common across many pages (inverse document frequency).
For SEOs, TF-IDF is used to identify which keywords a page should emphasize to rank well, based on keyword usage patterns in top-ranking content.
As search evolves toward semantic search using more vector models, TF-IDF’s reliance on exact keyword matches is being replaced by models that understand meaning and context.
Unfortunately, in simpler models like TF-IDF, problems present themselves when further nuance and clarification are required to truly understand the meaning of a text or query.
Look at the following example:
| Bill | ran | from | the | giraffe | towards | the | dolphin |
| Bill | ran | from | the | dolphin | towards | the | giraffe |
While the two sentences do not match and have different meanings, older algorithm models would score them as having a higher than 95% match because all of the same words are present in both.
This very basic example shows a clear area where more relational data is needed to properly interpret the different meanings of two sentences.
Semantic SEO enters the chat…
Today’s search engines incorporate semantic retrieval methods that use vector embeddings to go beyond simple keyword matching like TF-IDF to better understand the user’s intent behind a search prompt.
As Google users are increasingly searching on the go and often vaguely piecing together their queries in a way that aligns with their intent, that behavior needs to be captured and accounted for within the search algorithm.
Google Fellow and Vice President of Search, Pandu Nayak, provides an example of this need for better contextual understanding in search by citing the query: “insights how to manage a green.” This query will not make sense to the average person, but through combining massive amounts of embeddings and the relationships between those data points, Google’s systems can ascertain that the search query pertains to management styles based on a color-coded personality guide.
In order to understand how search engines like Google are using new methods like neural matching to improve semantic understanding and search results, we first need to unpack the concept of vector databases.
What are vector databases, and why are they important for SEO today?
Pretend for a second you are Tom Cruise. Or at least Tom Cruise in that one scene in Minority Report where his character is selecting and moving around all of those different data points in a three-dimensional virtual database. But rather than solving a crime, let us continue to pretend that maybe he’s just doing all of this to locate a specific copy of that “History of the Crusades.” Each of those data points he is moving is just a vector line originating from source classifications such as “War,” “Europe,” “History,” “Religion,” “Middle Ages,” etc. He is querying each source index, with the output being a connection point of all those vector details. That leads us exactly to a specific numerical location point on the virtual 3D grid where all the vectors come together to show the version of this author’s book we’re looking for. This is basically how a vector database works.
Taking my ridiculous comparison aside, vector databases, in a search engine context, can be thought of as all of the different indexes or libraries that Google uses to locate and serve your search results after you input a query.
This vector embedding fundamentals article from Hugging Face provides a great example that showcases the power of vector databases based on pure machine learning:
When seeking to answer “what is the nearest city to Chicago,” a human might immediately think to pull out a map. However, vector databases allow Google to simply turn this search into a mathematical equation. Using latitude/longitude coordinates, layered with population sizes by zip code, the shortest distance of comparable size can be calculated – Cicero. The power of these vector databases is that they can communicate with each other to provide even more relevant results based on conceptually understanding and comparing related dimensions of a topic.
While we don’t have public information on the exact formulas Google uses to calculate vector embeddings within their search systems, there have been a number of great published studies from researchers involved with Google’s shift to vector models that may shed some light on the process.
One example is this research piece from Tomas Mikolov, the team lead who introduced Word2Vec technology into Google’s algorithm in 2013. As suggested in the name, Word2Vec introduced all English words as vectors in Google’s systems to calculate similarity scoring. Other attributes of each word can then be layered on top and assigned weighting.
Keyword clustering and semantic relevance
Keyword clustering can provide a visual representation of basic vector embeddings, as in the example below.
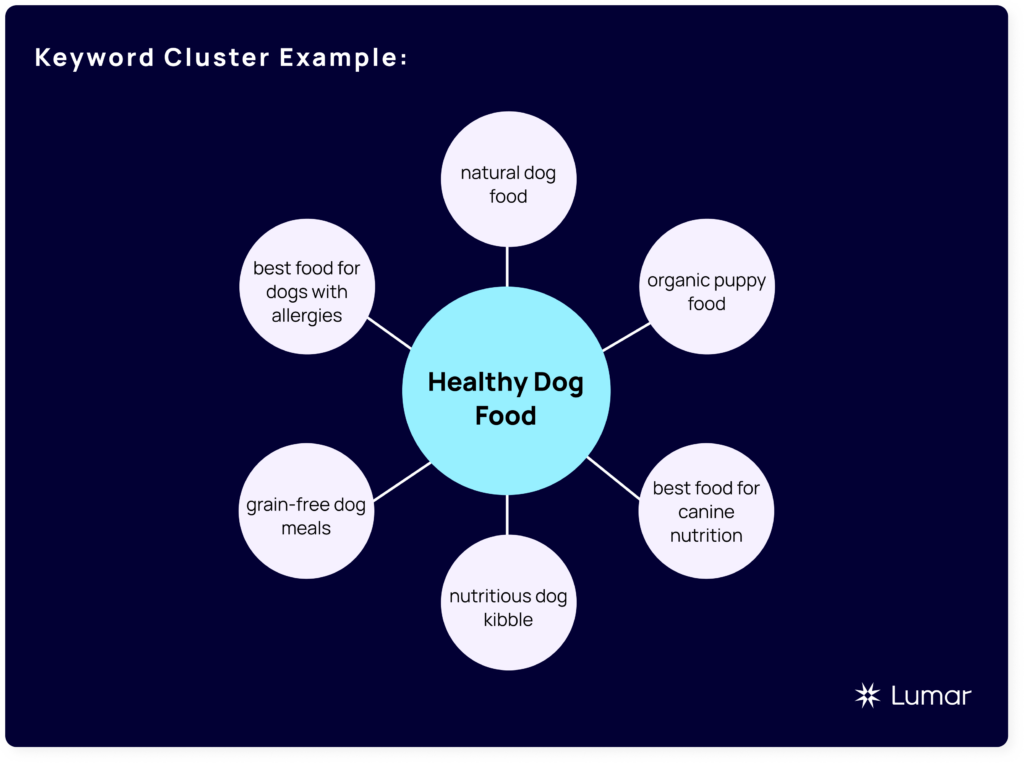
In a basic keyword cluster, each of the ‘spokes’ radiating from the core key phrase shares contextual meaning, even though they use different phrasing.
If each keyword phrase outlined below existed in a multi-dimensional vector space, they would appear close together because vector models learn that these related phrases often occur in similar contexts.
In a vector space, clusters can have thousands of related keywords or queries, with their density determined by their relative distance from each other and if they are pointing in the same direction (also known as cosine similarity).
Key Terms & Definitions: Cosine Similarity
Cosine similarity is a metric used to measure how similar two vectors are by calculating the cosine of the angle between them. In the context of semantic search and vector embedding models for SEO, it quantifies how closely the meaning of two pieces of text (e.g., a query and a webpage) align, based on their positions in a high-dimensional vector space. This helps search engines retrieve content that matches user intent, not just exact keywords.
Establishing similarity and relevancy across multiple characteristics
While keyword clustering exercises are useful for visualizing basic topical categorizations, Word2Vec showed that vector embeddings can go beyond simple clustering and rank relevancy to specific dimensions or characteristics (For example, for terms related to kings or queens, vector embeddings may match these terms to related characteristics like royalty, masculinity, age, etc.) based on references across multiple indexes in a vector database.
Eventually, the BERT language model went on to incorporate this contextual weighting into Google’s ranking algorithm.
Key Terms & Definitions: BERT
BERT (Bidirectional Encoder Representations from Transformers) is a language model introduced by Google researchers back in 2018. BERT’s key feature is its ability to consider the full context of a word within a sentence, including its relationship to words before and after it.
To understand how today’s Large Language Models (LLMs) build on the concept of semantic relevance even further than the earlier vector embedding models, we can look at a sentence like: “Tim Cook damaged Apple at its core.”
LLMs are able to establish a contextual relationship between “Apple” and “Tim Cook” because of all of the references that exist in their vast knowledge bases between the two entities — understanding Apple as a company entity and Cook as its CEO in this context — to know that Tim Cook didn’t spoil a perfectly good snack.
Types of vector embeddings: dense and sparse
Sparse vector embeddings: limited contextual understanding
In the context of SEO, TF-IDF leverages sparse vector embeddings. These embeddings are called “sparse” because they consist mostly of zero values—each dimension in the vector corresponds to a specific word in the vocabulary, and only the words that actually appear in a document have non-zero values.
Sparse vector embeddings are more traditional relational data as they are mostly used to perform basic comparisons of sequences. Think of it as a list of items with most of those items having a zero value, compared to the non-zero elements in that list.
Let’s say you have a blog post with the topic of “healthy diet for your dog” or “puppy treats with natural ingredients,” and you want to rank for those specific terms and other qualifying queries related to this topic. A sparse vector analysis would list out all of the words and phrases in the blog post and assign each a score out of ten that speaks to the terms’ relevancy to the user’s query. While most of the words (and, or, the, but, etc.) would have a score of 0, the remaining portion of the words with a 1-10 score can then easily be weighed against the whole document.
Dense vector embeddings: understanding relationships between entities
Dense vector embeddings, on the other hand, allow for the capture of more nuanced and relational data characteristics. The development of dense embeddings is crucial for semantic search, as human language is filled with far more complex information and relationships of meaning that cannot always be distilled into the simplistic categorizations available via sparse vector embeddings.
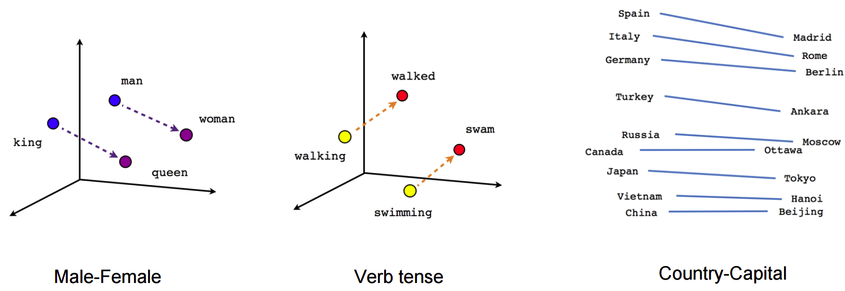
Looking at the above vector examples, you can see that meaning and context can be captured in relationships between entities even if those entities aren’t exactly the same. The similarity of characteristics is captured through cosine similarity rather than a simple stack-ranked algorithm.
SEOs thinking about how Google can reference their content for use in LLMs are rethinking their content audits by looking for dense vector workflows to create a neural net (or cluster) of information around the topics we want to be visible. These neural nets can also be referred to as encoders that allow topics across HTML, audio, images, etc., to be connected. It’s how a search for “two dogs running” serves the below image.
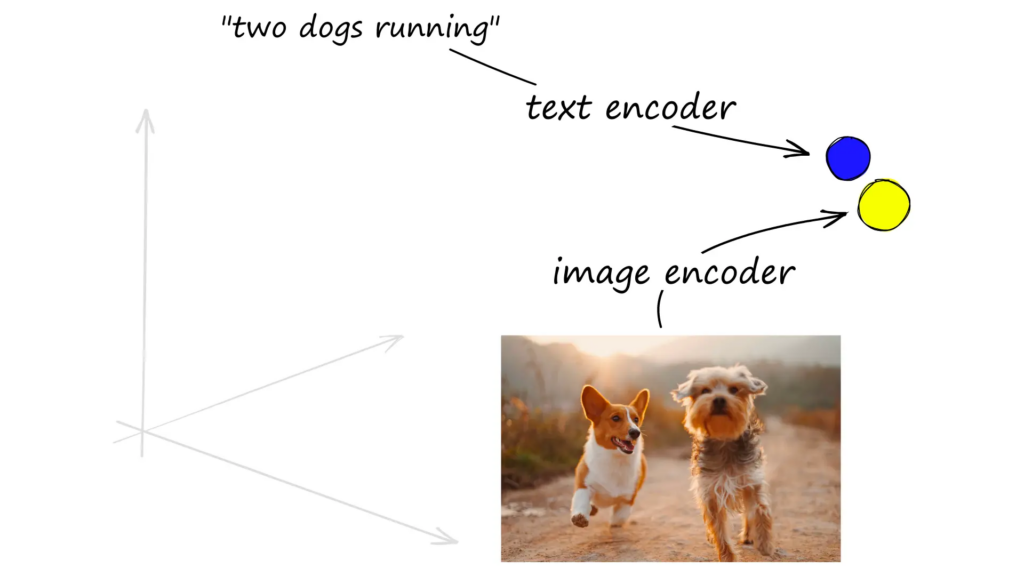
Vector search explained
Most people who use Google, YouTube, or Bing to search for things daily are not asking themselves about the mechanics of how their results are being served to them. For most, it is as simple as:
1.) You type in some keywords
2.) Those keywords are calculated against a large library of content
3. Get a list of results satisfying those keywords with references to more information on the topic.
However, as you would imagine, the folks at Google are thinking a lot about their retrieval methods. Which methods of data retrieval provide the best user experience? Which methods of data retrieval are the most cost-efficient? How can we keep track of an ever-growing number of webpages and types of media being served on the internet?
When early lexical retrieval models were being examined, there was one contrarian model that was tested against the more traditional search engine models. The model, called the uniterm model of retrieval, was “designed to allow rapid lookups on topic keywords and then cross-reference those keywords across multiple topics.” Applying this concept to search marketing, each new query is mapped to an index so that all queries can be compared against each other. This core concept is the basis of vector search.
According to Elastic Search, vector search solves this problem of scale by “leverag(ing) machine learning (ML) to capture the meaning and context of unstructured data.” From an SEO perspective, rather than measuring a single query against the index, Google can simultaneously compare the query and all of the other related queries around to reference against a multitude of indices covering images, video, news, etc.
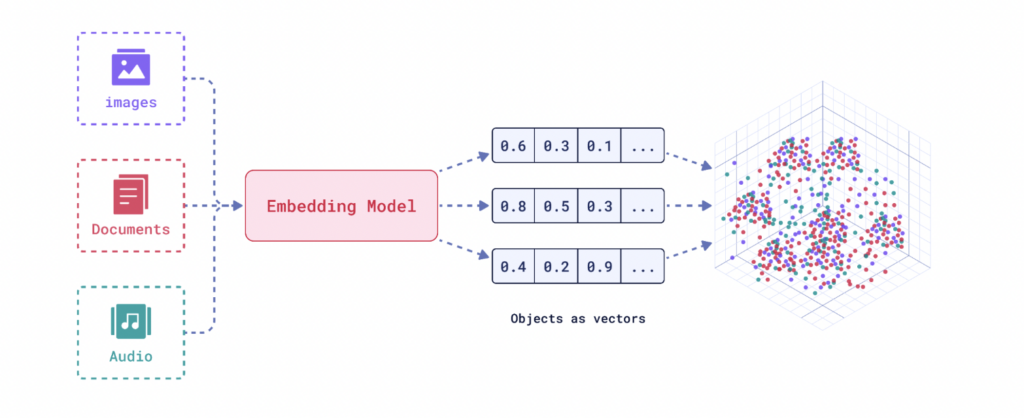
Remember my earlier, primitive example for how an early-career SEO understands how search engines work? With vector search, you can still keep it simple but up to date with just a slight modification:
1.) You type in some keywords
2.) Those searched keywords are mapped against multiple indexes to account for semantic variety
3.) The semantically referenced query is calculated against a large library of content
4.) Get a list of results satisfying those keywords with references to more information on the topic.
The net outcome? Better, more relevant search results for Google users and more data for Google to build upon. Google is organically creating self-classifications as new bodies of work are introduced over time as a living library of more dense vector relationships.
Hybrid search models today
Vector Search is one of the tools that make up the semantic retrieval side of the hybrid search model that is present in Google’s algorithm today. The truth is that the lexical method of data retrieval that Google has been using for years is still present in Google’s algorithm today. All of these historical data sets now represent even more vector embeddings to be referenced against.
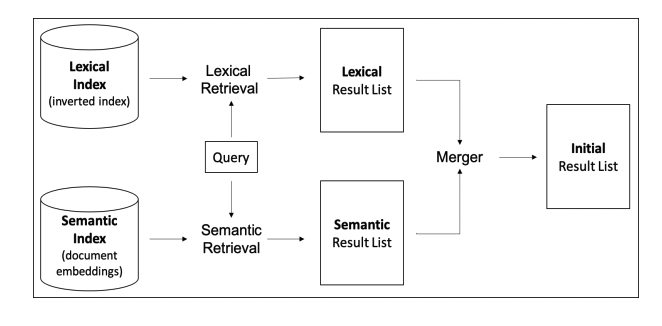
Semantic SEO strategies
How is the adoption of vector models by search engines revolutionizing the way SEOs assess their content strategies today?
Well, we know that AI overviews have diluted web traffic, bringing back into focus the old saying, “quality over quantity,” when it comes to your organic traffic these days. With most search experiences being served without a single scroll below the fold of the search results (Only 9% of Google searchers make it to the bottom of the first page of the search results, according to a Backlinko study) or without a single click-through to a website, quality, qualified traffic is at a premium.
Using vector models in your SEO workflows and strategies
There are a myriad of potential SEO use cases for vector models that I think are underutilized today. These include:
- Advanced keyword/topic clustering
- On-site user recommendation engines
- Pattern detection
- Content generation
Utilizing vectors & LLMs in SEO platforms
At Lumar, one of the ways we use vector-powered LLMs in our website optimization platform is to detect differences in the language of a page compared to its hreflang tag. Hreflang information is used by search engines to show the most relevant version of a page to users based on their respective country location. Where the primary language of the page does not match the hreflang language used in hreflangs pointing to the page, search engines may ignore the hreflang links, or the page may be incorrectly shown to users in search results.
Lumar utilizes vector relationships to determine the dominant language of the page, including in text that may not be visible to the user, such as pop-ups. We support SEOs in doing website internationalization at scale by helping identify the extent of language gaps and prioritize international SEO issues through measurable and actionable metrics.
Using vector embeddings to improve SEO workflows
There are a lot of cool things happening in the SEO space right now using vector embeddings.
In Mike King’s article, in which he urges SEOs to rethink the weight of the inverted-index method of SEO prioritization, he speaks to some pretty innovative ways to automate several common SEO workflows using vector embeddings.
For instance, he explains how to use vector embeddings and cosine similarity scoring (converting cosine similarity calculations into a score between 0 and 100) to plan your redirect mapping strategy for site migrations or internal link optimization using vector embeddings and cosine similarity scoring. Vector-assisted link mapping with an emphasis on both site architecture and relational content similarity adds plenty of opportunity for SEOs to automate this process. He even uses this same methodology for backlink outreach strategy, where cosine similarity is used to best identify link targets.
Another way vector embeddings can be used in SEO workflows is during the competitive analysis and strategy phase. SEOs can compare both the amount of overlapping cannibalization within your own websites AND the cosine similarity scores between your content vs. your top-performing competitors’ content.
Advanced keyword clustering with vector models allows SEOs to better build content strategies with denser embeddings for varied content opportunities that take into account branded traffic delineation and the historical context of competitive rankings.
Semantic SEO case study #1: Broadening content strategies with semantic analysis and entity optimization
In his recent blog post discussing how SEOs should be looking towards the future, Gianluca Fiorelli emphasizes that SEOs need to shift from the long-time industry keyword-matching mindset to opt instead for content strategies that take into account broader audience interests along the search conversion funnel. He doesn’t want to dissuade SEOs from standard keyword research completely, but he reminds us that “search engines and LLMs now rely on embeddings (not just keywords) to surface content.”
In practice, that means not solely focusing on your target keywords in the relevant page elements, but also starting to focus on semantic optimization and entity SEO.
Incorporating “entity-based” SEO in your strategy could help you illustrate the most popular formats for your specific content pieces (for example, potentially using short <ol> lists vs. long-form reviews) and take into account all of the related subtopics that should be present.
While this concept isn’t new, what is innovative here is Fiorelli’s approach of using vector embeddings or semantic analysis throughout each step of his SEO strategy.
This could include:
- Classifying your client’s industry and identifying the key entities associated with that industry
- Using Google NLP tools to scrape queries associated with those diverse entities and their SERPs
- Building a site taxonomy based on proven entities relating to the consumer journey
- Analyzing new embeddings against your current site content to spot gaps and opportunities
Fiorelli covers a recent case study showing a content strategy that more intuitively aligns his clients’ ideal search consumer profiles to the business needs and objectives. After implementing new semantic SEO and entity-focused optimization strategies for his client in a highly technical manufacturing niche, they began to see rankings for unexpected keyword topics, and the brand began to see more citations on LLMs like ChatGPT and in AI Overviews.
“Search engines and LLMs now rely on embeddings (not just keywords) to surface content.”
Gianluca Fiorelli in “A guide to Semantics — or how to be visible in both Search and LLMs”
Semantic SEO case study #2: Understanding how semantic similarity scores correlate with SERP rankings
At Lumar, our Chief Product Architect, Michal Magdziarz, conducted a study to examine how higher semantic relevance scores correlate to higher search engine rankings.
What we found from studying 2,000+ search queries, calculating the top 10 SERP results’ semantic relevance scores, and comparing those scores against their SERP positions:
- Vector models were much better at assessing and scoring on-page elements for semantic relevance than TF-IDF models.
- Vector models were also better at demonstrating the correlation between high semantic relevancy scores and SERP position.
- High-ranking pages in the SERPs, across all query types studied, consistently exhibited strong semantic relevance to the search query across multiple on-page elements (including main content, H1s, title tags, etc.)
- Across all models (both vector and TF-IDF), a strong correlation was shown between highly semantically relevant short page elements (like Title or H1) and higher search rankings.
- Semantically relevant “Main Content” elements showed a weaker correlation with high-ranking SERP positions compared to semantically relevant short page elements (like H1s and Titles). — Despite the weaker SERP position-semantic relevance correlation shown on the Main Content extractions compared to other element types across all models used, the vector models were again able to show a much stronger correlation here compared to TF-IDF models.
(You can read more details from our study on semantic relevance in our eBook, “From Keywords to Context: How Semantic Relevance is Redefining SEO”.)

The future of semantic SEO (i.e., why should YOU care?)
In his SIGIR keynote, Google DeepMind researcher Marc Najork stated that “direct answers lower the Delphic cost of information seeking.” In simpler terms: Google is aiming to reduce the effort users need to find accurate answers, hence the rise of generative AI Overviews in search. These AI-powered summaries aren’t going away anytime soon.
What does that mean for website publishers and SEOs? While some traffic may bypass the traditional organic links, the visitors who do reach your site should be more qualified — SEO today is not just about getting more traffic, it’s about getting better traffic to your site.
Although traffic may be distributed differently, it’s becoming more targeted. Content that aligns with user intent — rather than just trying to match keywords — will likely attract higher-quality traffic over time.
Vector embedding models can complement traditional SEO methods. However, for many SEOs, there’s a learning curve. Start small. Begin integrating vector-based insights into manageable parts of your SEO workflows — for example, by analyzing semantic relationships across your website content and using that data to improve your internal linking strategies. Or try doing deep, dense vector analysis to help plan your content.
Understanding and incorporating vector-based semantic relevance strategies into your SEO plans can be a gradual shift for your team, but I believe it’s one that will define the next era of SEO.
Innovations in AI and NLP are shaping the future of SEO
SEO Strategy Creation and AI for Semantic Intent
I have been speaking with more and more SEOs who want to account for AI bot traffic on their sites and build new strategies to optimize their site content for LLMs.
For brands worried about how a growing number of AI bots are fetching and using their content, the hard truth is that the SEO space is evolving and practitioners need to take note or get left behind. There are many voices throughout the SEO ecosystem who have varying opinions on how to solve for this. For some SEOs, there is even the thought that the SEO landscape should be split, with a distinction between AI bot optimization (or ‘GEO’) and optimizing for click-throughs and user interaction.
Ann Robinson from VereNorth talks about “not reinventing the wheel.” Monitoring rankings and query volume will still be a play for SEOs, but combining traditional content research methods with entity comparison and answering related topics is going to be just as important for the industry moving forward. In practice, what this looks like is:
- Describing the desired topics you want to rank for using related terms and comparative entities on prominent page elements
- Refining those topics with continued research into related entities and synonyms being added to a text, or referencing an original text through internal links
- Ensuring schema is being used on-page to distinguish entity properties and remove ambiguity.
Continuing to refine your content actively in this way is important. It will also be important to understand different types of prompts for how users may find your content when it’s referenced elsewhere. Putting a governance strategy in place to understand where AI bot traffic is hitting your website.
Conclusions on semantic relevancy & vector models’ impact on SEO
Just like the Dewey Decimal System once reshaped how we organized knowledge, vector models’ enhanced ability to unearth semantic relevancy is reshaping how we retrieve it.
But unlike the more static shelves inside a physical library, search engines are dynamic, ever-expanding collections built on live user data and constantly evolving algorithms.
Semantic relevancy isn’t just a trend in SEO — it’s becoming the backbone of modern search. Google’s incorporation of advanced semantic understanding models into its systems signals a future of online search where meaning matters more than keywords.
But for SEOs and searchers alike, this shift comes with some new complexity. Search engines have had some occasional missteps on their path with vector models — from factually incorrect AI Overview results, to a weaker-than-expected roll-out of Reddit-heavy SERPs.
The challenge in the SEO industry is to adapt like Google does. Treat your websites not as static assets, but as living libraries—constantly updated, structured for clarity, accessible to new technologies, and optimized for true relevance.



