

What is Schema Microdata?
Microdata is a form of structured markup which allows you to add metadata onto existing page content in order to help search engines understand the purpose of the content and provide richer search results for users.
You can find out more about schema metadata, including further benefits and the different types of markup in our Technical SEO Library.
Schema supported by Google
There are several forms of schema markup that are supported by Google, these include;
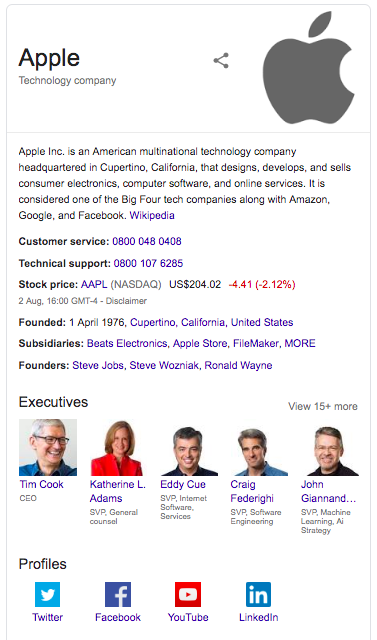
Company information: Provides a company overview, logo, contact details and social media profiles.
Events: This can be used by performers, venues or ticket selling sites to display dates, times, locations and other information about the event. This information can then be shown in Google’s event search features.

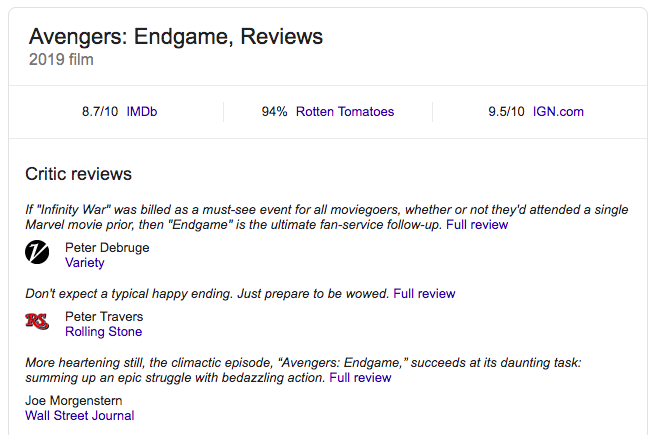
Rich snippets: Shows product information, recipes, reviews, event details (in regular search results), video thumbnails and news article information.
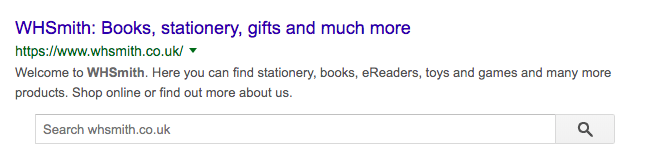
Breadcrumbs & site search boxes: These can enable the user to go directly to the specific information they want.
A full list of items which can be added through schema markup can be found here.
Schema supported by Bing and Yandex
Bing currently supports markup for breadcrumbs, business and organisation information, events, people, products and offers, recipes and reviews. Read Bing’s Markup Overview for more information.
Yandex supports markup for address and organisation information, videos, questions and answers, software and movies. Products and prices, recipes and creative content including blog posts and audio objects are also supported by Yandex. View their schema.org guide for more details.
How to implement structured markup
Using in-page markup, structured data can be added to the HTML code of the page the information is contained on. The code is typically implemented into the head of the page, but adding it to the body is also valid.
Further information on implementation and guidelines for the use of structured markup can be found in Google’s Structured Data guide.
Different markup formats
Schema markup can be implemented using three different methods; Microdata, RFDa and JSON.
Microdata
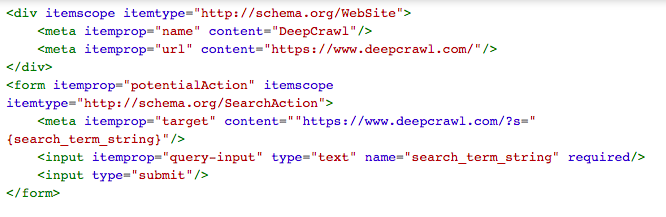
Microdata is an open-community specification used to include additional tag attributes to existing HTML content.
An example of Microdata Website structured markup looks like this:
RDFa
RDFa (Resource Description Framework in Attributes) is a HTML5 extension which uses the in-line markup syntax and supports linked data to describe user-visible content to search engines.
An example of RDFa Postal Address structured markup looks like this:

JSON-LD
JSON-LD (JavaScript Object Notation for Linked Data) is Google’s recommended format for implementing structured markup to a page. This is due to the fact that most new types of structured data come out in this format first. JSON-LD is also provided as a blockcode, so it is easily separated from the page’s content.
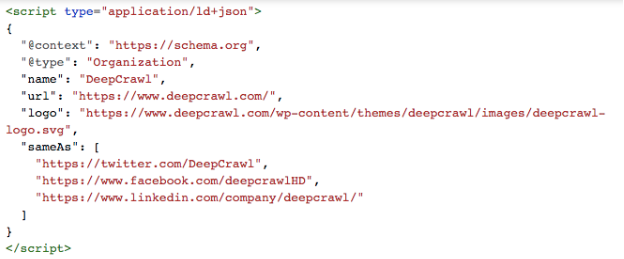
An example of JSON-LD Organisation structured markup looks like this:
Auditing and monitoring schema tags using DeepCrawl
Using DeepCrawl’s Custom Extraction Tool you can check for, and extract, several types of schema tags including microdata, RDFa and JSON. This powerful feature cuts hours out of your site audits by showing you which pages have schema tags, plus which tags have been added/removed since your last crawl.
Extracting schema tags through Custom Extraction
The Custom Extraction settings are found in the fourth step of the crawl setup under Advanced Settings.
To check for and extract schema tags, enter the relevant regex rule below into the Extraction Regex box in Advanced Settings > Custom Extraction > New Extraction Rule.
Pre-written regexes for schema custom extraction
To help you extract your site’s schema tags, we’ve put together some different pre-written regexes below, depending on the method you are using.
Microdata only:
microdata:
(itemtype=["']http\:\/\/schema.org)
microdata-itemtype:
itemtype\s?=['"\s]?http\:\/\/schema.org\/([^\"\s\']*)
RDFA only:
rdfa:
(vocab=['"]http:\/\/schema.org\/['"])
rdfa-typeof:
typeof=['"]([^"']*)"
JSON only:
json-ld:
(<script type=['"]application\/ld\+json['"]>)
json-ld-type:
['"]@type['"]\s?:\s?['"]([^"']*)
Here is an example of how the JSON-LD type custom extraction would appear in the app:
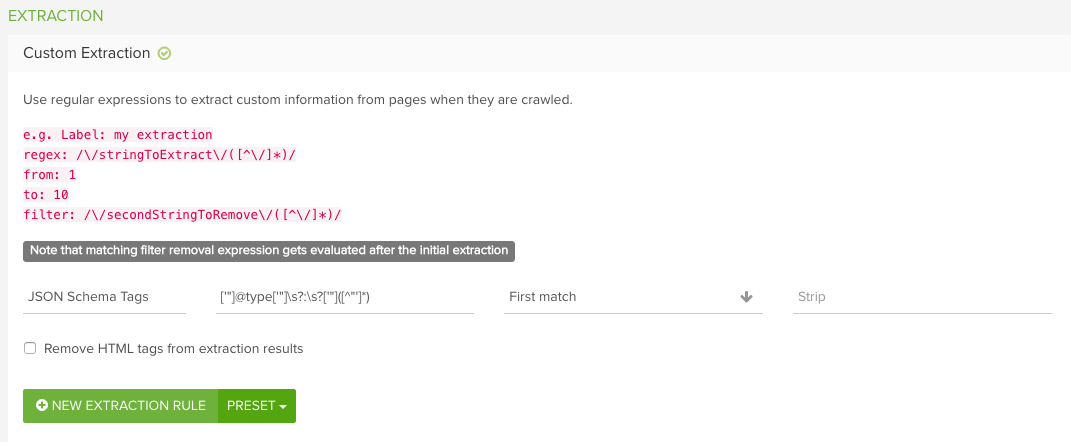
For more information on using regex rules, our regex guide provides a great introduction to help you get started.
Identifying mixed schema formats
Google advises against using both microdata and JSON-LD types on a single page as it can cause confusion and can be complicated to implement and maintain. The following regex will enable you to identify any pages which contain both formats.
Mixed_Schema_Formats:
itemtype="http:\/\/schema.org\/.*?conte(x)t"\s?:\s?"http:\/\/schema.org"|conte(x)t"\s?:\s?" http:\/\/schema.org".*?itemtype="http:\/\/schema.org\/
Custom Extraction Reports
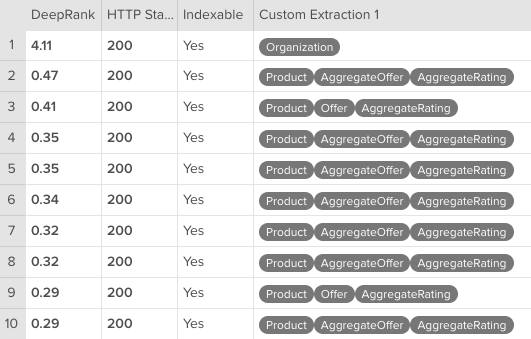
Once your crawl has finalised, you will be able to find your custom extraction reports in the navigation on the left-side of the app.
From here you will be able to see the type of schema which has been identified on each page, along with the key metrics for each in one central report.
Testing and validating schema tags
While extracting your schema tags will tell you where they are within your site, they are worthless if they are not valid. The following testing tools can help to identify any issues which may be occurring with the setup and implementation of structured data.
- Google’s Structured Data Testing Tool on Google Developers.
- Bing Webmaster Tools under Diagnostics & Tools
- Yandex Structured Data Validator on Yandex Webmaster Support
The importance of monitoring structured markup
Ensuring you are correctly implementing structured data is important to help you stand out in saturated search engine results pages. This is particularly useful if you are not currently ranking as highly as your competitors, as it enables you to achieve SERP real estate. In some cases, rich results are also likely to drive more meaningful clicks to your website. Therefore, monitoring and analysing the implementation of these tags is essential to ensure your content is able to appear in search results that are relevant to what your customers are looking for, helping to direct relevant visitors to your site.
Sign up for a DeepCrawl account to identify schema tags on your site
Sign up for a DeepCrawl account to try out our custom extraction feature for yourself and gain an understanding of the schema tags currently on your site.
Learn more about Custom Extraction
Custom Extraction is a powerful tool that can be used to check a number of different elements, including extracting analytics, social tags, backlinks, product data, and much more. It can also be used for performance measurement by collecting chrome page speed metrics, which you can find more about in our guide here.



