It’s time to talk about bot traps in SEO. From subtle crawl inefficiencies to full-blown indexing disasters, many SEO issues stem from seemingly small implementation choices that cause big problems for search engine bots. These are the kinds of traps that quietly erode search performance over time—until rankings drop, traffic slips, and no one’s quite sure why.
In this SEO explainer, I’m digging into the mechanics behind these bot trap issues, explaining why they matter for SEO, and offering some strategies for fixing or avoiding them entirely.
First off, what are some common bot traps that can trip up search engine crawlers and cause problems for your site’s crawlability and indexability? Well, there are quite a few! But, in my experience, these are some of the most common bot traps SEOs encounter:
- URL parameter / query string issues
- Pagination and page discovery issues
- Repeated URL paths
- JavaScript rendering issues
Let’s dig into these crawler-confusing site problems, one by one…
URL parameter / URL query string issues that can hurt crawl performance and confuse bots
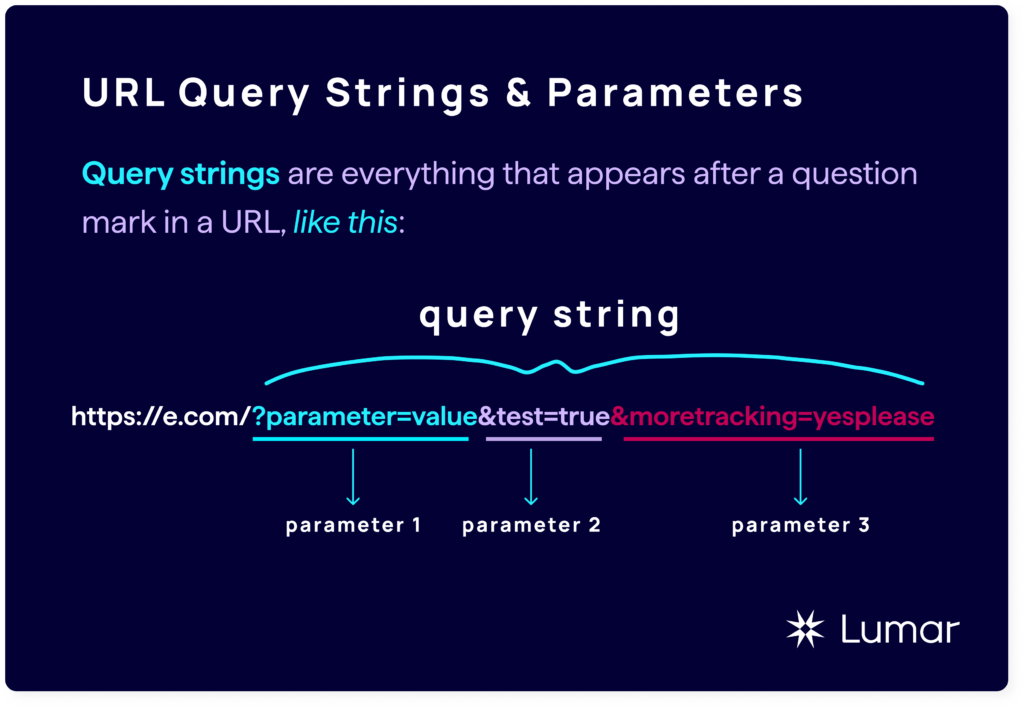
URL query strings (aka URL parameters) are everything that appears after a question mark in a URL.
For example: https://e.com/?parameter=value&test=true&moretracking=yesplease
URL parameters are used to track campaigns, get data in a specific format, and can even modify the page — this can go as far as loading entirely different page content depending on the query string, in some instances.
One of the strengths of query strings, when used in a tracking context, is that they can provide data without having to modify the page. This means if you go to almost any URL and add ?test=true the page should load without any issue 99% of the time
But there is a downside to this flexibility.
Google uses the URL as a unique identifier for each page, so adding a query string onto it creates a new page to index and anchor its value onto. This means your tracking parameters just created a brand new URL with identical content to compete with your existing page.
This is the perfect use case for canonical tags.
Canonical tags help bots group together sets of similar pages and allow you to indicate which URL is your preferred option to be shown in search results. Simple enough, right?
The problem with canonicals is that they are a hint, not a directive. Search engines don’t have to respect your canonical tags. If Google thinks there is enough value being pushed to a different page, despite having a canonical tag in place, it can outright ignore your tags.
The more pages you add with query strings, the more pages Google has to crawl, which could mean crawl budget issues, particularly if you’re working on a large website.
But query strings are here to stay, so how can we keep control of the crawl/indexing issues they may introduce?
First off, even though they are just hints for the bots, canonicals are a must. If you don’t have canonicals in place, anyone can just add a query string to your page and make a duplicate. You have no control at all if you aren’t at least adding canonicals.
Secondly, avoid unnecessary pages. Watch out for adding a unique identifier in a query string, which gets carried around your entire site. If you are paginating, make sure it’s not possible to go from page=2 to page=1. These mistakes add up quickly.
Thirdly, don’t allow user input to be indexed. This is an absolute minefield and will at some point result in a bad actor spamming your website maliciously. If your website outputs the search string onto the page, they will try to get some authority from your site back to theirs. Watch out if you suddenly see thousands of empty search results with multiple languages and websites in the query strings.
Finally, make sure any filters you use to curate your content add the query parameters in the same order. For example:
https://e.com/?shoes=blue&size=large is viewed by bots as a completely different page from https://e.com/?size=large&shoes=blue — despite the fact that the content is identical!
Pagination & page discovery bot traps
Next up in the world of bot traps that SEOs need to be aware of: pagination.
This search bot trap is a common one for e-commerce & publishing sites, but technically, any site that uses a paginated approach can easily slip into exposing search engines to deep, outdated content instead of higher-priority content.
The trap is in allowing navigation through pagination one page at a time. Page one only links to page 2 (or page 2 and page 1000), resulting in the only path to later pages of content being a page-by-page move through the pagination.

To try and illustrate this better:
Page 1 → Page 2 → Page 3 → Page 4 → Page 5
So, getting to any content on page 5 requires 4 clicks. This is already pretty deep in the site, and this is likely to be the only path to discovery for this content.
This is made worse if you link to the first and last pages in the paginated navigation, as effectively, the potentially oldest content in the paginated series is given the same priority as the second page.
The end result of this is loads and loads of levels in a crawl, making content more difficult to discover, particularly in the middle, and potentially promoting content that might be old, archived, or otherwise low-priority.
So, how do you fix these potential pagination issues?
Typically, you want to expose multiple pages in your pagination, allowing both bots and users to move to multiple pages from one view, not just the next in the sequence, e.g.:
1→ 2, 3, 4, 5
3, 4, ← 5 → 6, 7
This allows pages to be discovered much more quickly and avoids pushing bots (and people) down a long, slow trail of only being able to discover one page at a time.

In addition, consider if you need the last pagination to be part of the sequence. Do users actually want to navigate to the very last page? Is the content on that page just as relevant, or is it more likely to be unimportant or outdated?
In the case of publishers, consider moving content to a separate archive to keep your main pagination clean and easier to move through.
Reducing noise can help new pages get picked up quicker and perform better as a result.
How Google handles URL paths — and potential traps to avoid
Looking for even more bot traps? Let’s talk about URL paths…
There are two interesting Google behaviours around repeated URL paths.
First: If you repeat a URL path 3 times, Google won’t index the page, thinking that it is caught in a bot trap:
/path/path/path/
This is a pretty unusual occurrence, but it isn’t unheard of for sites to sub-in category elements with the same name, particularly if the site is quite big and clunky.
You might find multiple instances of replacers like “-” being used in the URL to make a behind-the-scenes mapping work correctly, for example:
/-/-/-/product
You can read more about this issue in the article, “Never Repeat Pathnames in a URL more than Twice.”
The second example of potentially problematic Google crawler behavior relating to URL paths is related, but instead of Google ignoring the URL paths, it will endlessly discover them.
Using skip links on a page to jump users down to specific content can be useful, but if you use a relative path, you might find that Google just keeps adding that skip link to the URL and endlessly discovering new pages!
/longpage#FirstParagraph
This is how a skip link should work, but if it’s not properly set up, that page will load and allow you to get to:
/longpage#FirstParagraph#FirstParagraph
And that page will just keep adding extra hashes to the end infinitely.
Even if your site doesn’t have crawl budget issues, this will cause them as Google has an infinite path to follow and it really wants to check out every single page it can find.
For one of our clients, a skip link issue resulted in 25 million additional pages being crawled within a week.
So, avoid the infinite loops, keep an eye on your Search Console for sudden spikes in pages, and make sure you check that recently crawled pages report in your GSC settings often if you rely on things like this!
JavaScript rendering issues that can trip up search bots
Did you know that when Google initially fetches your site, it does it without using a renderer?
This means that anything on your page that relies on JavaScript for loading will not be visible to Google’s search bots.
So if your navigation relies on JavaScript to populate links, none of those will be discovered until it returns with the renderer. This can mean slower discovery for those pages.
If you rely on things like Tag Manager to inject canonicals or other key data for bots, then you could be confusing Google, leading to its bots potentially ignoring more of your “hints” and weakening the control you have on your site.
And did you know that even at this unrendered stage, Google can choose to index your page?
So Google might just index that half-loaded page that heavily relies on JavaScript to get stuff done. This can result in really unexpected rankings or completely missed intents. An e-commerce site isn’t really an e-commerce site if no purchase buttons show up and it’s just blocks of text.
Did you also know that a fraction of a percent of the pages that Google crawls took more than several months to be rendered?
The trouble is that a fraction of a percent for Google is in the trillions of pages, so there isn’t any guarantee that Google will be timely with its return and render of your page! One example was well into the years, and the renderer still hadn’t returned.
But before you panic, there are a number of ways to plan for this and help ensure that your JavaScript isn’t creating extra SEO risks.
You could prerender and serve Google a nice finished page. Though this is kind of an old method now and has its own problems, such as effectively maintaining two separate websites…
You could also ensure that when JavaScript fails, your site still has all the important stuff on there. For example, ensuring your site’s navigation elements still have their anchor tags, or that buttons still function as buttons — it’s all possible without using JavaScript on these elements. I would highly recommend this method if you can do it.
In addition to all the Google talk here, remember that LLMs also don’t render JavaScript; they don’t need it. So if you want to make sure your content appears in LLMs, then you need to make sure it is still visible to bots when JavaScript is turned off.
While Google has gotten better and better at rendering JavaScript, its use is also getting increasingly complex on websites, and ensuring your site can fail gracefully is a key way to protect against unexpected issues.