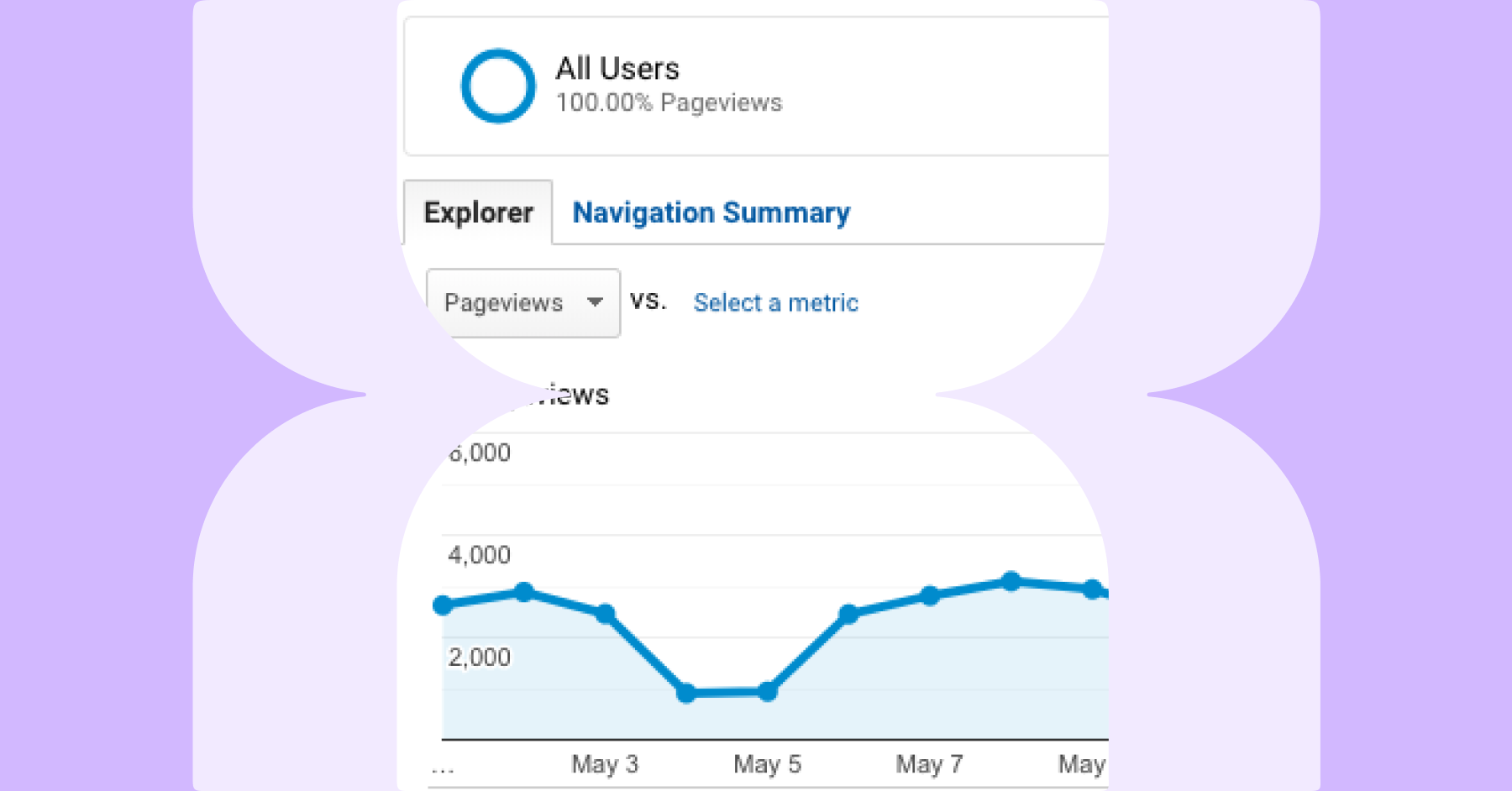

Being able to measure and analyze the impact of technical SEO improvements against wider business metrics has never been so important.
SEOs today need to prove their work leads to greater revenue and business improvement in order to fully understand the value of their work and to build a stronger business case for increasing budgets, acquiring new tools, and having a bigger stake in decision-making.
Lumar has now added a BigQuery connector so you can connect your crawl data to all your other data sources together to do just this.
Why use the BigQuery connector?
Our BigQuery connector will allow you to easily access all your crawl data and integrate it with many tools that you use in your day-to-day work.
Historically, the only way for users to get all URL data about a crawl was to generate a CSV, download it, decompress it, and parse it. As our CSVs are not made for programmatic use, any update we do to the CSV data or format tends to break user-built integrations.
BigQuery availability gives users access to all data with a powerful SQL querying interface. If users are able to install the BigQuery ODBC driver in their environment, they will be able to query BigQuery as if it was any other SQL database. Developers can also utilize Google SDKs to quickly test/deploy apps without writing much code
Many businesses will not load their commercially sensitive data into Lumar (i.e. traffic, sales, etc). If they have their business data in a BQ (or any SQL db), they should be able to merge their business data with DC data in BQ and analyze it for problems there.
When BigQuery is enabled for a project, we will automatically import all new crawls to a dataset that is shared with you.
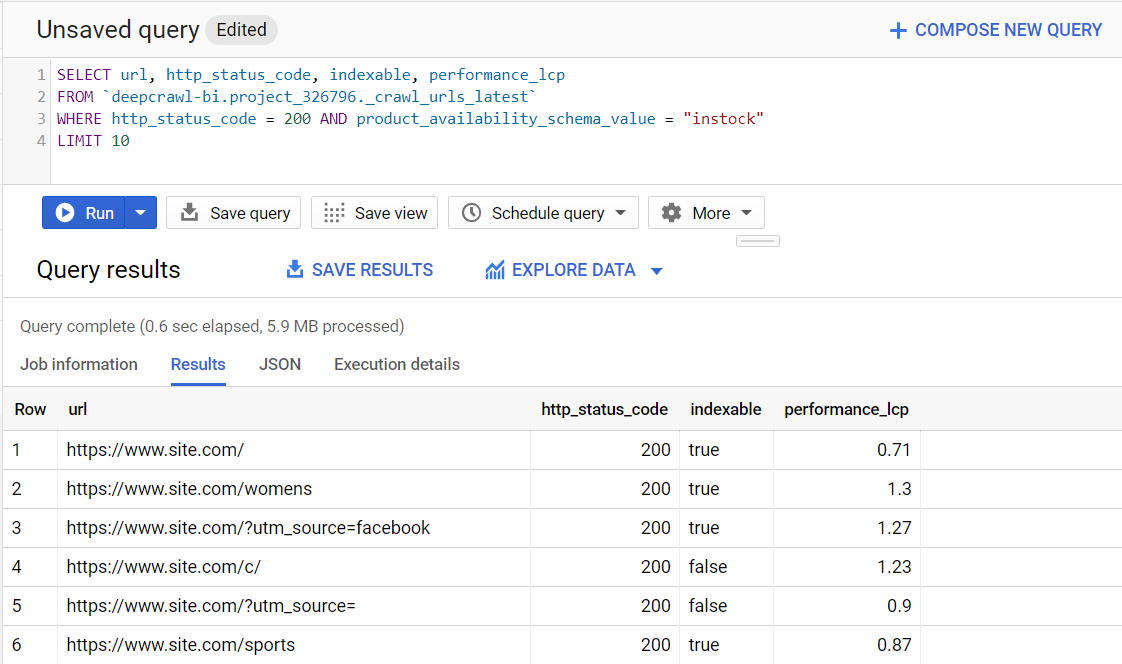
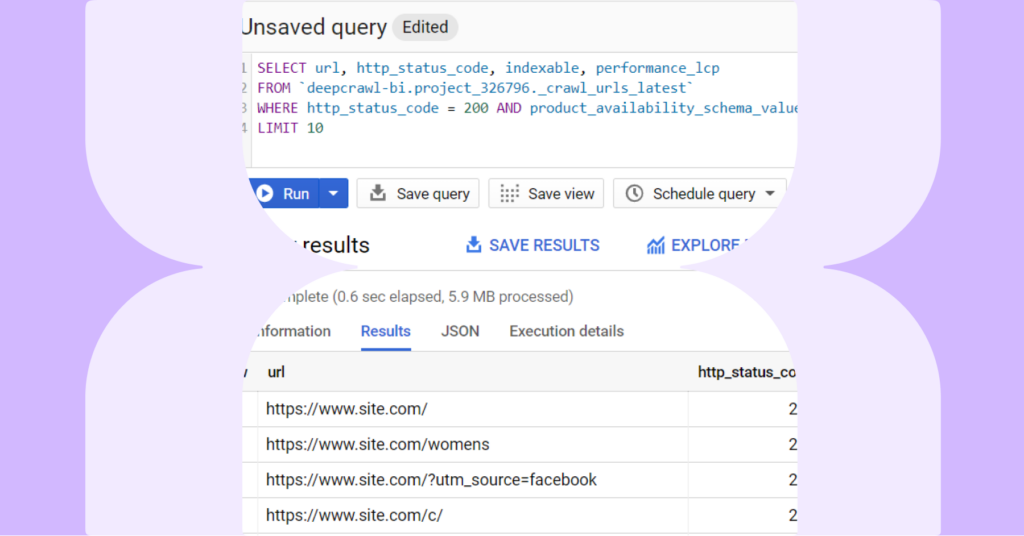
Data format
Each Lumar project is a BigQuery dataset which uses its ID as its name (such as project_123456), each crawl is a table inside this dataset – each table is named crawl_urls_[DATE]-[crawl ID] such as ‘crawl_urls_20201225_654321.
The crawl data itself contains all of the data that we know about each URL in the crawl.
Lumar SQL Cheat Sheet
We’ve structured our data in a way that will allow you to get all of the insights that you need.
Rather than manually selecting a crawl, you can use the below queries to logically choose the table you want to work with (such as “latest crawl”, “all crawls from the last 30 days”). The connector comes with some default data views which internally use these queries, so in some cases, it is easier to use those.
Data Projects & Billing Projects
Unless you request otherwise, your data will be saved into the BigQuery project “deepcrawl-bi” and shared with you.
While you will have the permission to access this data, this project does not come with any querying capabilities. The querying capability will come from a separate Billing Project that you can create using the steps outlined here (this is specific to your organization, so you should not share it). Therefore, when using data in the deepcrawl-bi project with any tool, you must specify the separate Billing project.
Permissions
Data is shared with you on a project-by-project basis. This means that you may share a project with a single team member and that person will not have access to any of your other BigQuery data.
Compatible systems
Below are some of the popular systems that natively integrate with Google BigQuery. Other systems may be compatible with BigQuery (or compatible with our other BI integrations) – please ask your CSM if you do not see your favorite tool.
Business Intelligence Tools
Looker
Lumar connects to Looker via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available in Looker.
See: Looker docs: BigQuery Integration
Tableau
Lumar connects to Tableau via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available in Tableau.
See also: Tableau docs: Google BigQuery
Create a datasource
When creating a datasource, find Google BigQuery under “Connectors”. After authorizing Tableau to access your BigQuery data, you will be presented with a list of your BigQuery projects – you’ll need to select both the Billing Project and the Project that you were assigned.
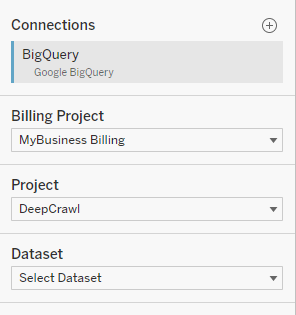
The Dataset is your Lumar project, and the number corresponds to the ID of your project in our system. To find your project ID, please see our BigQuery cheat sheet.
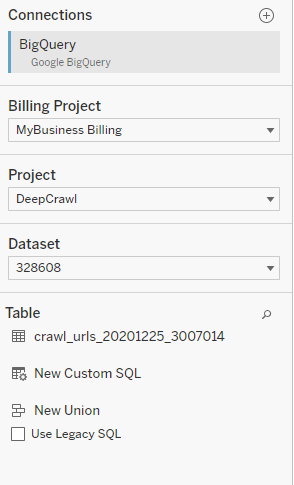
After choosing your project, you will be presented with all of the crawls currently in BigQuery. Choosing any of the tables will give you access to the data in that crawl, or you can use one of the preconfigured views (such as latest_crawl) to always have access to the latest data.
PowerBI
Lumar connects to PowerBI via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available to PowerBI.
See also: Microsoft docs: Connect to a Google BigQuery database in Power BI Desktop
Find Google BigQuery in the Get Data wizard and sign in to your Google account.
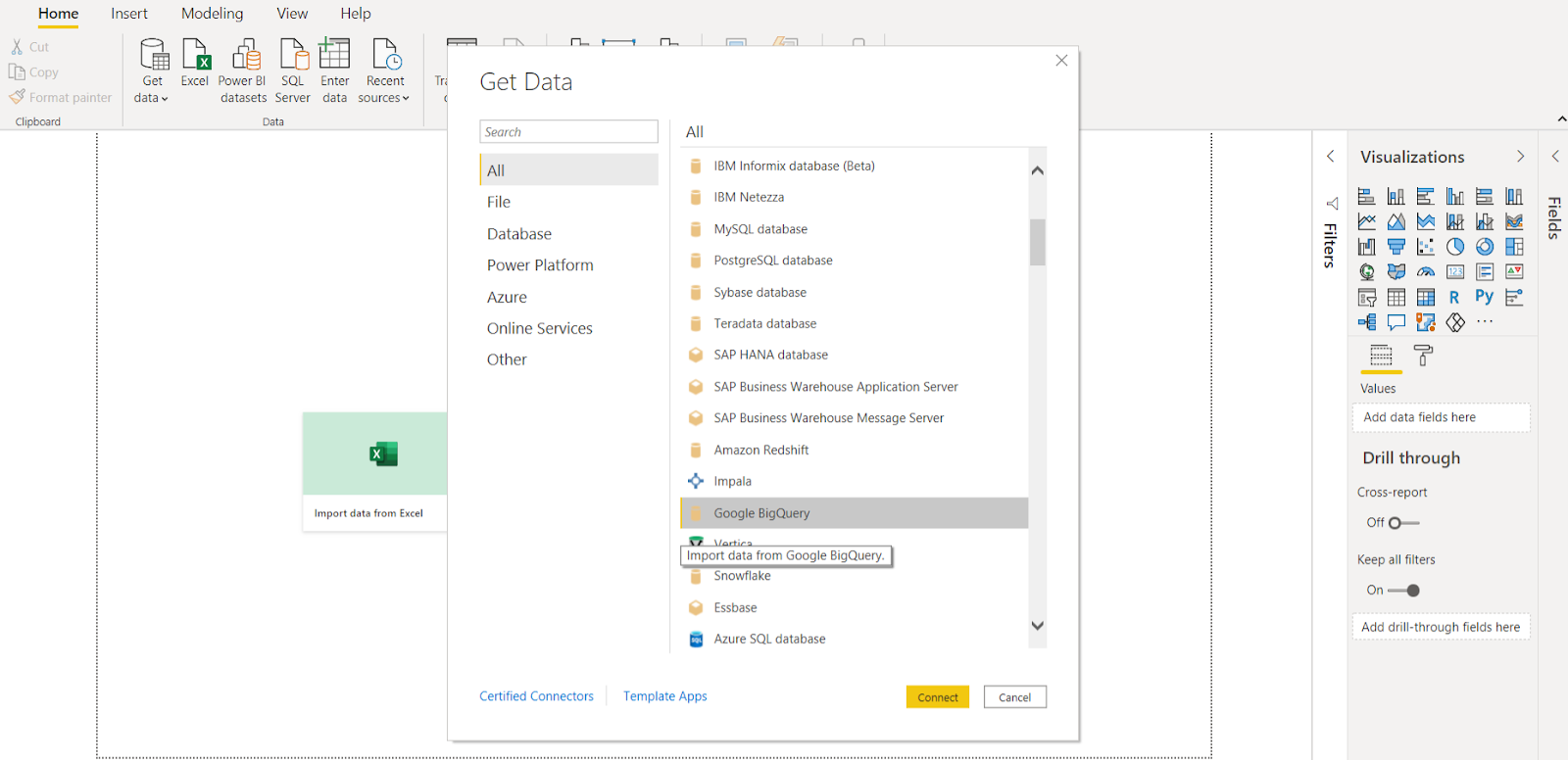
Find the project that you wish to import, tick a table, and you’re done.
Google Data Studio
Lumar has two ways to connect to Google Data Studio:
- Native connector which gives access to high-level report data (such as the number of 404 Pages in a crawl)
- BigQuery integration which gives access to raw URL-level data (such as URLs and HTTP Status Codes)
Lumar connects raw URL-level data to DataStudio via our BigQuery integration. When a crawl finishes, it will be loaded into BigQuery, and data will become available in DataStudio.
To use BigQuery in Data Studio, you must select the correct billing project as below:
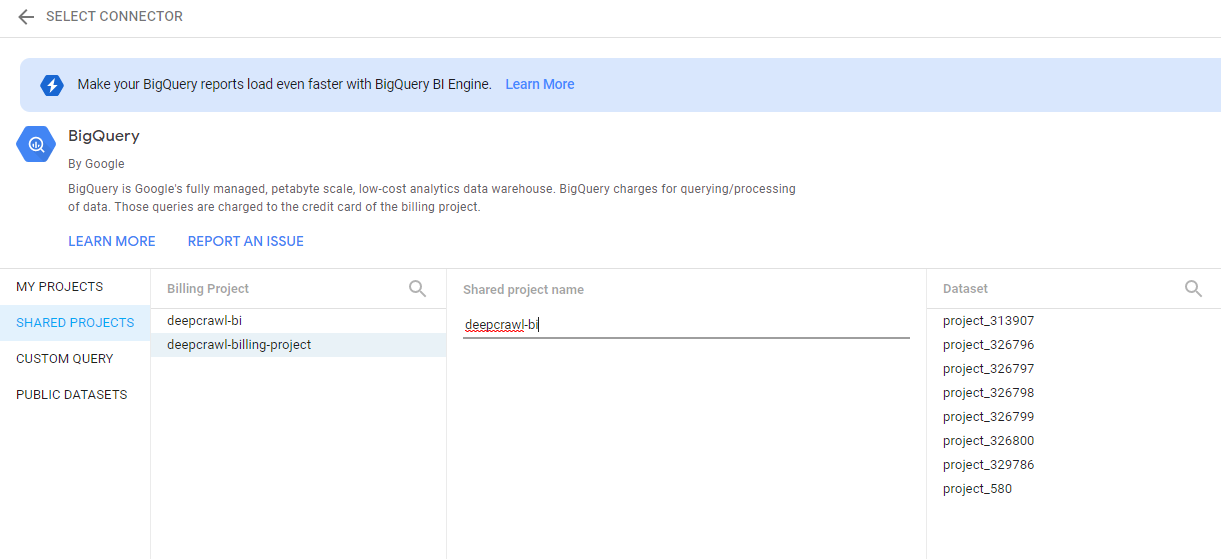
- Open the Data Studio BigQuery Connector
- Choose “Shared Projects”
- Select your billing project in the first column.
- Type “deepcrawl-bi” in the “Shared project name” input
- Your projects will appear in the Dataset area
Data Hubs and Data Lakes
Google BigQuery
Our integration with Google BigQuery will automatically send your Lumar data to BigQuery when a crawl finishes.
There is no additional setup to do – your CSM will share your BigQuery project with you, and you can access data in BigQuery or using a Google SDK.
Azure
Lumar data can be loaded into Azure via our Google BigQuery integration. When a crawl finishes, it will immediately be loaded into BigQuery and can be accessed with Azure Data Factory.
Please see Microsoft’s official guide for more information: Azure Docs: Copy data from Google BigQuery by using Azure Data Factory
Tealium
Lumar connects to Tealium via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available in Tealium.
Tealium advertises that they can connect to Google BigQuery, but does not provide documentation for doing so. You will need to contact your Tealium CSM for information about importing Lumar data into Tealium via BigQuery
Data Science
Jupyter
Lumar connects to Jupyter via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available in Jupyter.
There are many guides available about connecting BigQuery to Jupyter, see:
- Google: Visualizing BigQuery data in a Jupyter notebook
- TowardsDataScience: Using Jupyter Notebook to manage your BigQuery analytics
Python Pandas
Lumar connects to Pandas via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available in Pandas. Find out more about the Lumar BigQuery integration.
See: Downloading BigQuery data to pandas using the BigQuery Storage API
Apache Zeppelin
Lumar connects to Zeppelin via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available in Apache Zeppelin. Find out more about the Lumar BigQuery integration.
See: BigQuery Interpreter for Apache Zeppelin
Dataiku
Lumar connects to Dataiku via our BigQuery integration – when a crawl finishes, it will be loaded into BigQuery, and data will become available in Dataiku. Find out more about the Lumar BigQuery integration.
See also: Dataiku docs: Google BigQuery
You will need to first create a Service Account for your Google account:
- Find the Service Accounts page under “IAM and Admin” menu in Google Cloud Console
- Choose “Create Service Account” and give this service account a relevant name, such as “dataiku-[yourname]”
- When granting access to the project, it is recommended that you give the Service account only the minimum amount of permissions that it will need. For our purposes, “BigQuery User” may be appropriate.
- On step 3, you do not need to grant access to further users
- After the Service Account has been created, find Create Key in its hamburger menu, and create a JSON key. A file will now be downloaded to your computer
Dataiku natively supports BigQuery in its paid version. If it does not work, you may need to install the Google BigQuery JDBC driver as described on the Dataiku Docs
Visit the Connections screen in Dataiku and create a new Google BigQuery connection
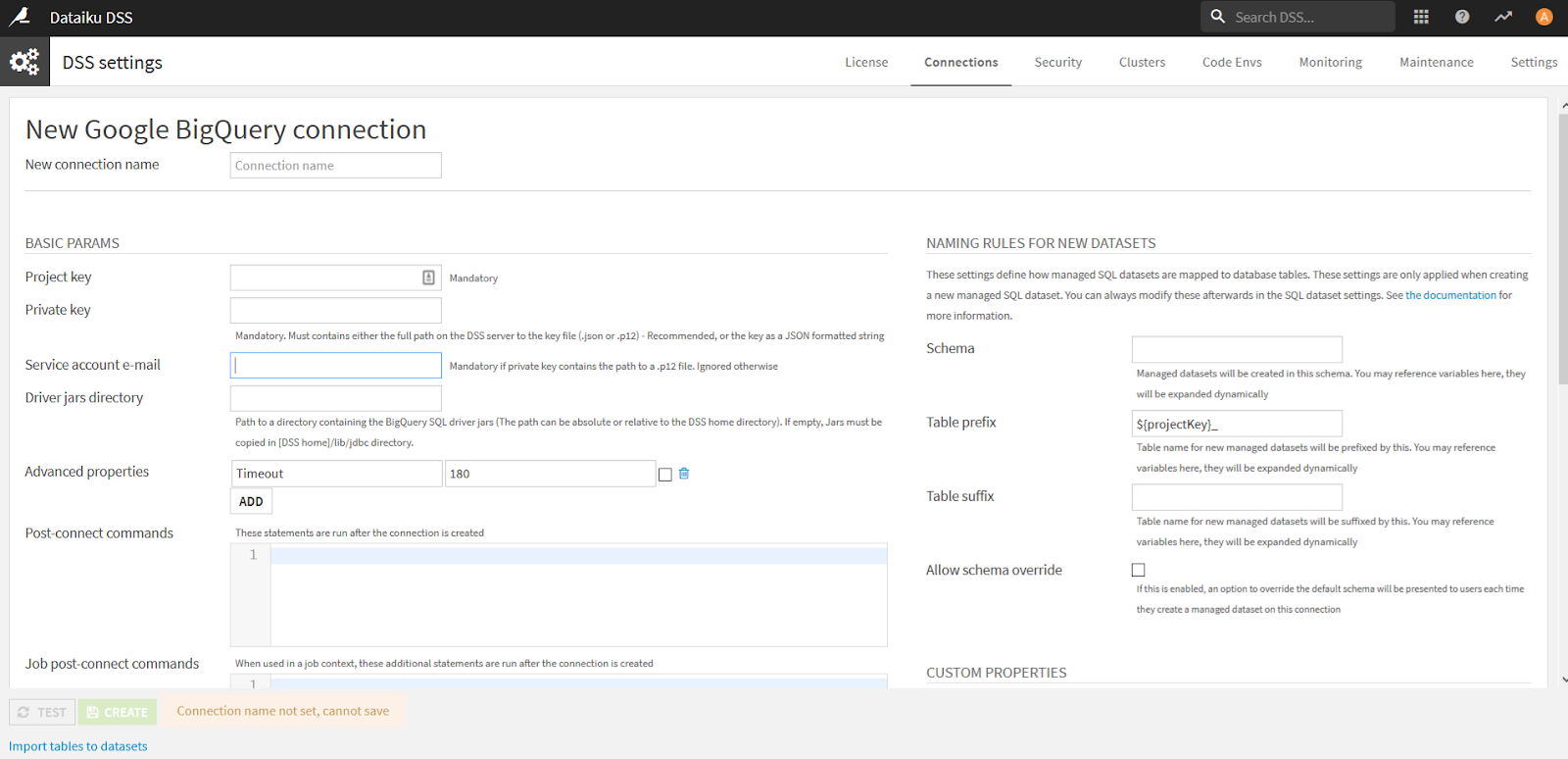
Open the Service Account file that you downloaded with Notepad or another text editor, and use its contents to populate the below fields as follows:
- New connection name: “Lumar” will help you identify this connection, but any label will work
- Project Key: Copy the “private_key_id” from your JSON file
- Private Key: Copy the “private_key” from your JSON file
- Service Account Email: Copy the “client_email” from your JSON file
You should now be able to test and create the connection. BigQuery datasets should now be able to be created.
How can I get started?
If you want to get started with Lumar’s BigQuery connector, reach out to your Customer Success Manager today.
Summary
As always please share any feedback as this helps to improve Lumar. If you have any questions about this new feature, please feel free to get in touch with our team.