

You can restrict the overall size and depth of a crawl before you start or during your crawl.
This is useful to prevent a lot of URL credits being used unintentionally, or to run a discovery crawl, when you first start to crawl a website and don’t yet know the optimal settings.
Crawl Depth & Max URL Limits
On step 3 of the crawl setup, you will see a set of options to limit the crawl. The first option is the crawl speed and you can use the slider to select the required speed.
The second option is crawl depth, which allows you to only crawls pages reached within the number of clicks or levels from the starting page. The starting page of a website is level 1. All the pages linked from the start page are level 2. All the pages linked from level 2 are level 3 etc. Enter a number between 1 and 1,000 to set the crawl depth.
The last option is the pages level limit. The default will be set to ‘1,000’, but if you click on this you will see that it drops down to give a number of preset options to get you started. These settings are fantastic if you’re setting up a crawl quickly and just want to select an approximate number of URLs.
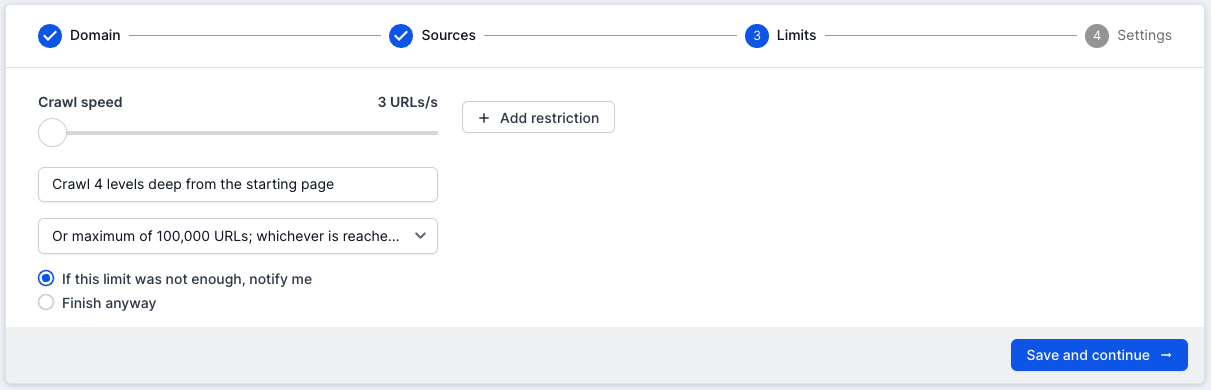
Another option, which gives more control and versatility, is to choose the bottom option from the drop-down list, which is ‘Custom’. This will allow you to choose a specific number of URLs.
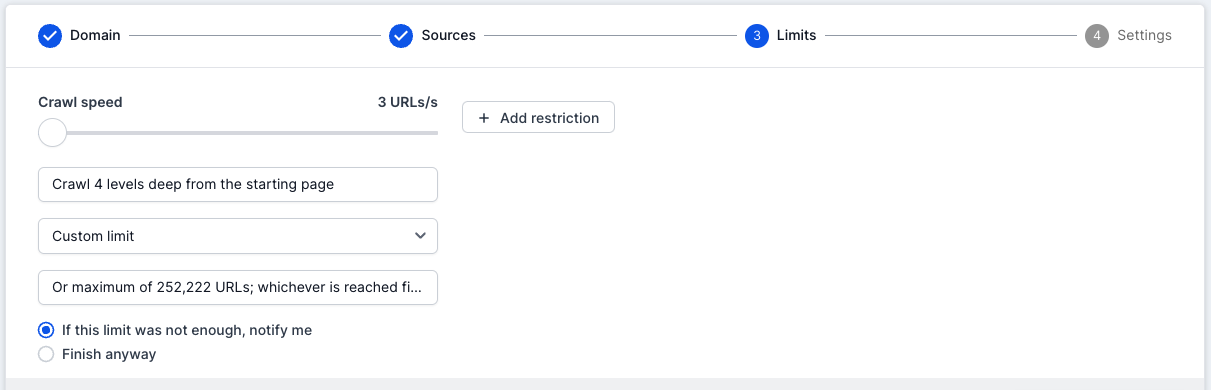
The crawl will stop after reaching the number of URLs you specify or the depth limit and either finalise or pause depending on your settings.
The maximum URLs per crawl setting in your account can be adjusted, to prevent regular crawls from using excessive credits. Contact support@lumar.io to change it.
Pause & Finalize
Select ‘Finish anyway’ to generate your reports automatically when the crawl limits have been reached.
Select ‘If this limit was not enough, notify me’ if you want the option to adjust your crawl settings, resume the crawl or to finalize it when the crawl limits are reached.

It’s also worth noting that you can change these settings whilst a crawl is running.
It’s not possible to restrict a List or Sitemap crawl based on max pages or max level restrictions. All pages in the list or Sitemaps will be crawled although you can manually pause and finalise at any point.
Page Grouping
It’s possible to limit the number of pages crawled for any page type using the Page Grouping function in Advanced Settings.
This is useful if you have a large number of pages with a certain URL type that you know you want to leave out of the crawl e.g. user profile pages.
Simply add a regular expression to match the URLs you want to limit and add a % value.
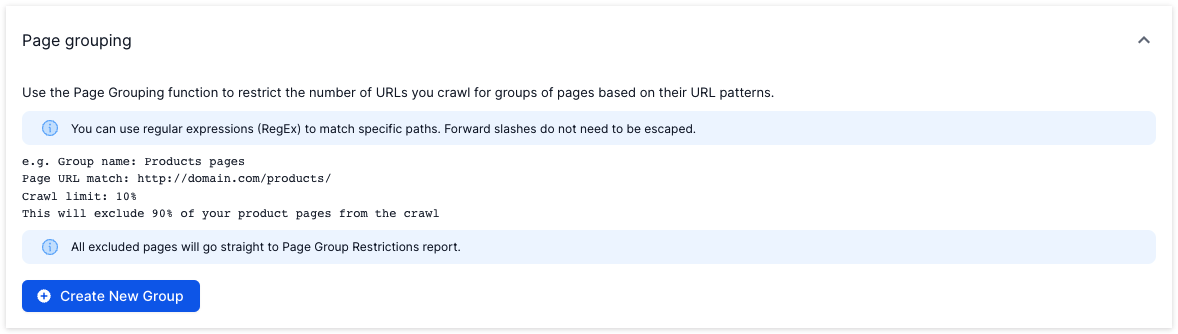
Please note: The “.*” regular expression is being appended by default to the end of Page URL Match so /search will match /search/anything, /search/anything2 etc.



