

Lumar can be used to check and automate if XML Sitemap files are valid.
Before reading this guide make sure you’re familiar with how to set up XML Sitemaps as a crawl source.
Why Check XML Sitemaps Are Valid?
The contents of Sitemaps can be ignored by search engines if the file is blocked from being crawled or the file format is invalid.
A few examples of an invalid XML Sitemap include:
- Errors in the XML tag format.
- URLs in the Sitemap contain a different HTTP scheme.
- URLs not in the same host as the Sitemap location.
Search engines use XML Sitemaps to discover new content and intelligently crawl websites. If important Sitemaps are invalid, then any new primary pages could be crawled less efficiently.
Google’s crawling and indexing system also use Sitemaps as a canonical signal. This is important if a large website has a lot of duplicate content but cannot implement stronger canonical signals like 301 redirects or canonical tags.
When Should XML Sitemap Files be Reviewed?
Check if XML Sitemaps are valid every time:
- A website is updated (sometimes changes aren’t always obvious).
- A website is migrated or goes through a rebrand.
- A change is made to a Sitemap(s) or Sitemap Index.
When checking if XML Sitemaps are valid it is recommended to set up a separate test crawl project. The benefits of setting up a test crawl project away from larger crawls include:
- Crawls can run quicker (less data to process).
- Analysis of the data can be done a lot faster.
- Issues and recommendations can be quickly identified.
Setting up and XML Sitemap Test Crawl
To test whether XML Sitemaps are valid follow these steps:
1. Create a new crawl project in your Lumar account for the domain the Sitemaps belongs to (do not select Enable JavaScript rendering).
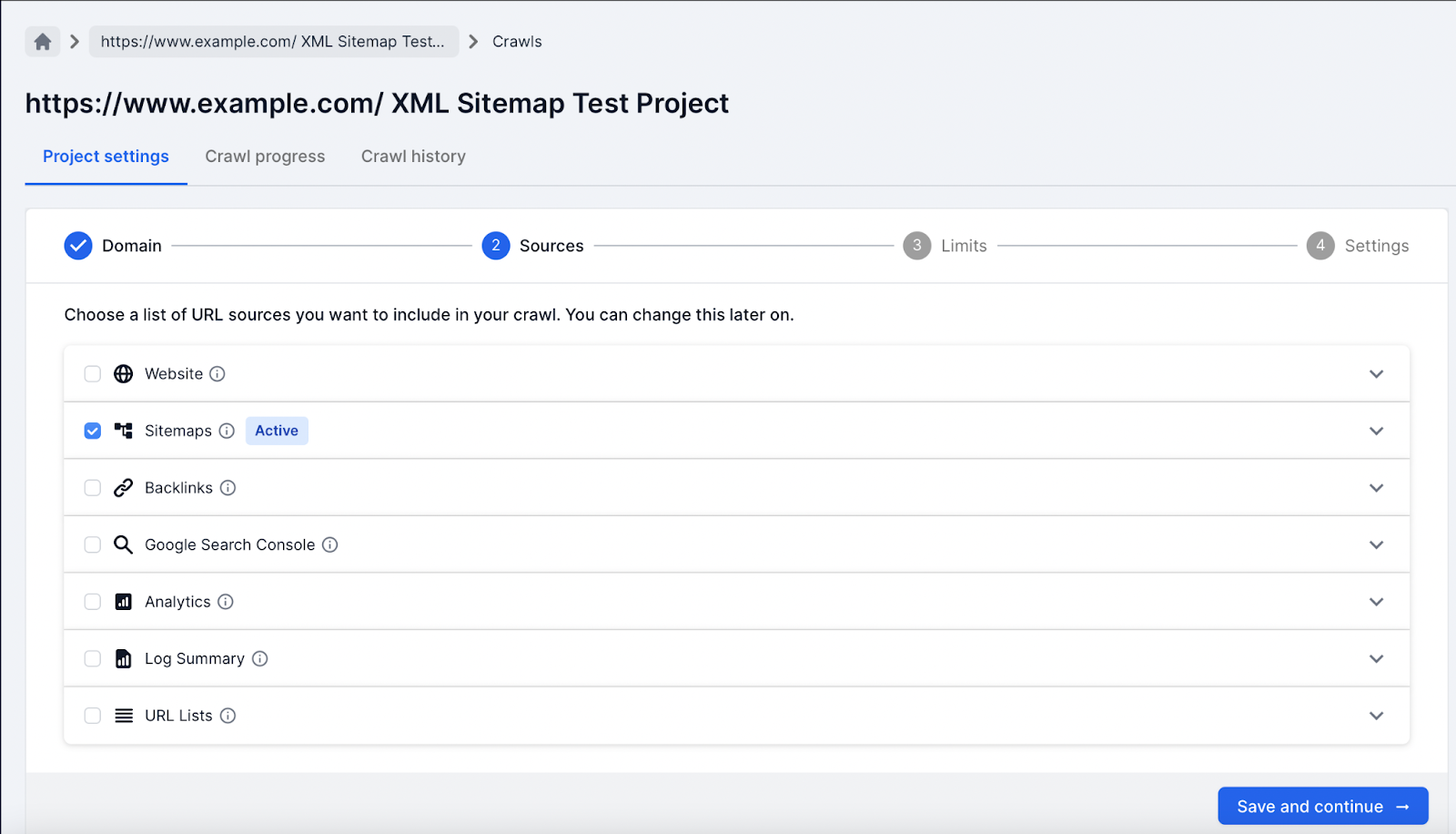
2. Only select the XML Sitemap source.
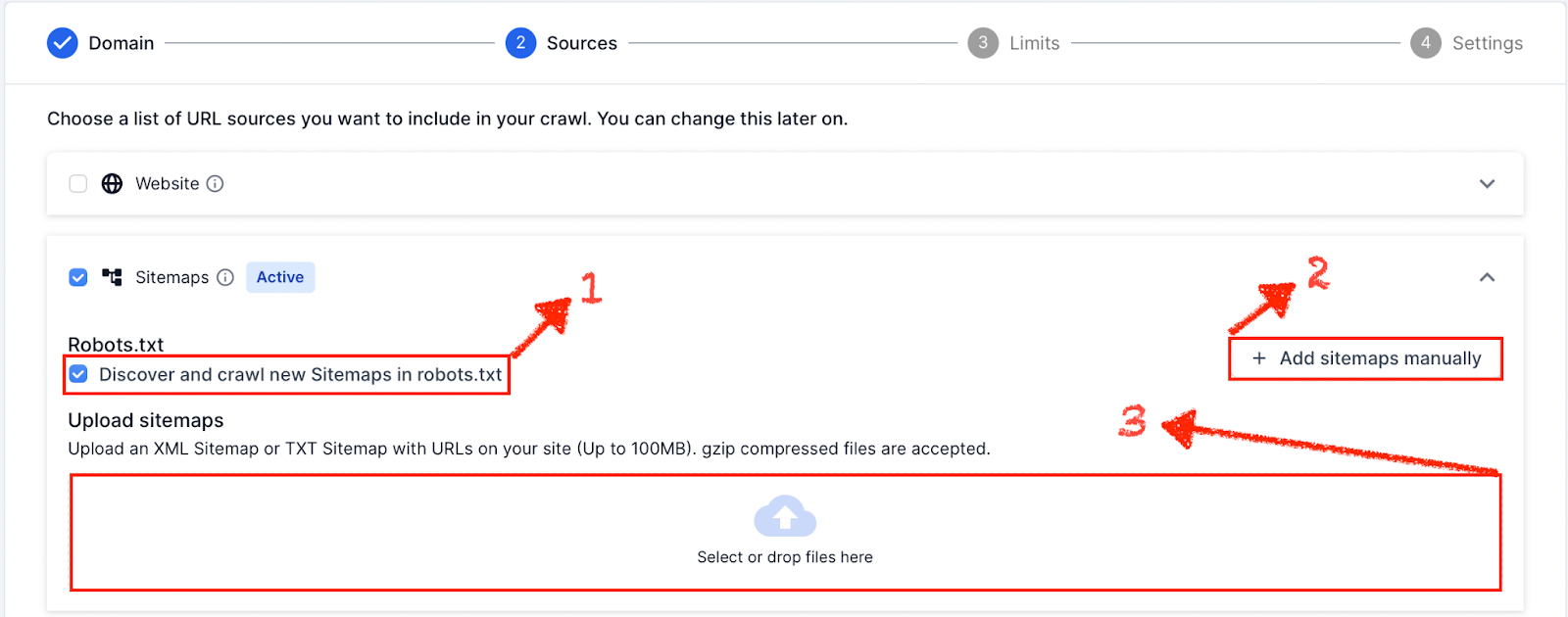
3. Submit XML Sitemap files to Lumar, using one of the following:
- Checking the “Discover and crawl new Sitemaps in robots.txt” option.
- Submiting Sitemap URLs manually option.
- Manually upload XML Sitemap files option.
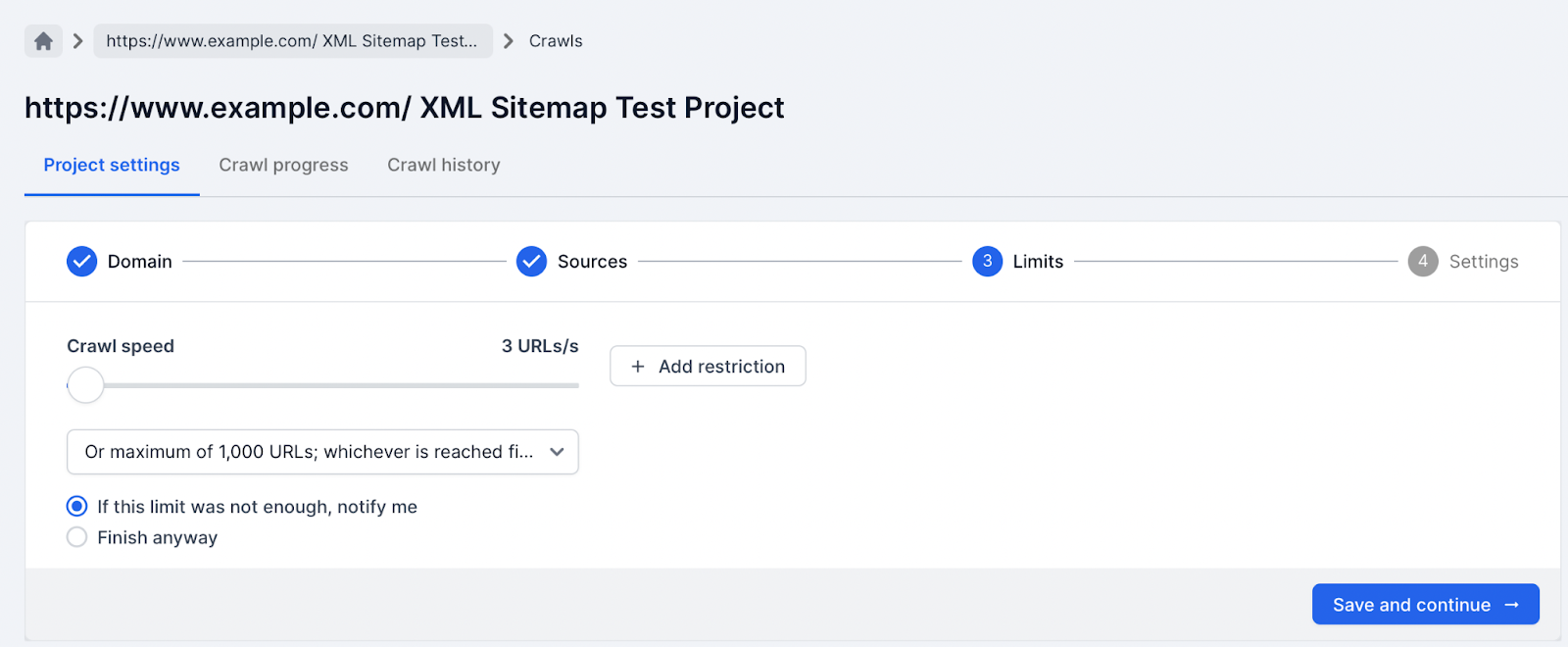
4. Limit the size of the crawl to 1,000 URLs in the limits settings; also depending on your server you might also need to reduce the speed of URLs per second.
5. Hit the run crawl button and wait for the crawl to finish.
Checking XML Sitemaps Are Valid
Once the crawl is finished the Sitemaps can be reviewed using Lumar reports. The following reports and methods will help identify if your XML Sitemap files are invalid:
XML Tag Errors
It is important to make sure all XML files tags are formatted correctly. If the XML tag format is not valid then crawlers, like Lumar, will cut off at the errors and any body content below the error is not processed.
For example, if there are errors at the start of the XML file then this could mean the entire file is not read.
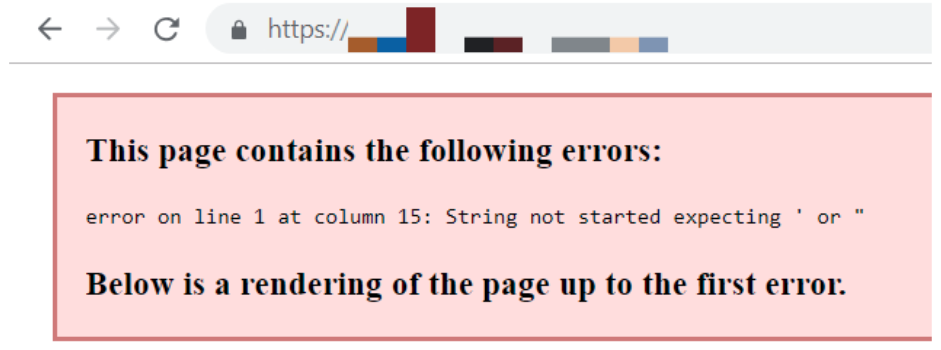
If all the XML Sitemaps have XML tags with errors at the beginning of the files then a project dashboard will show 0 pages crawled and processed.
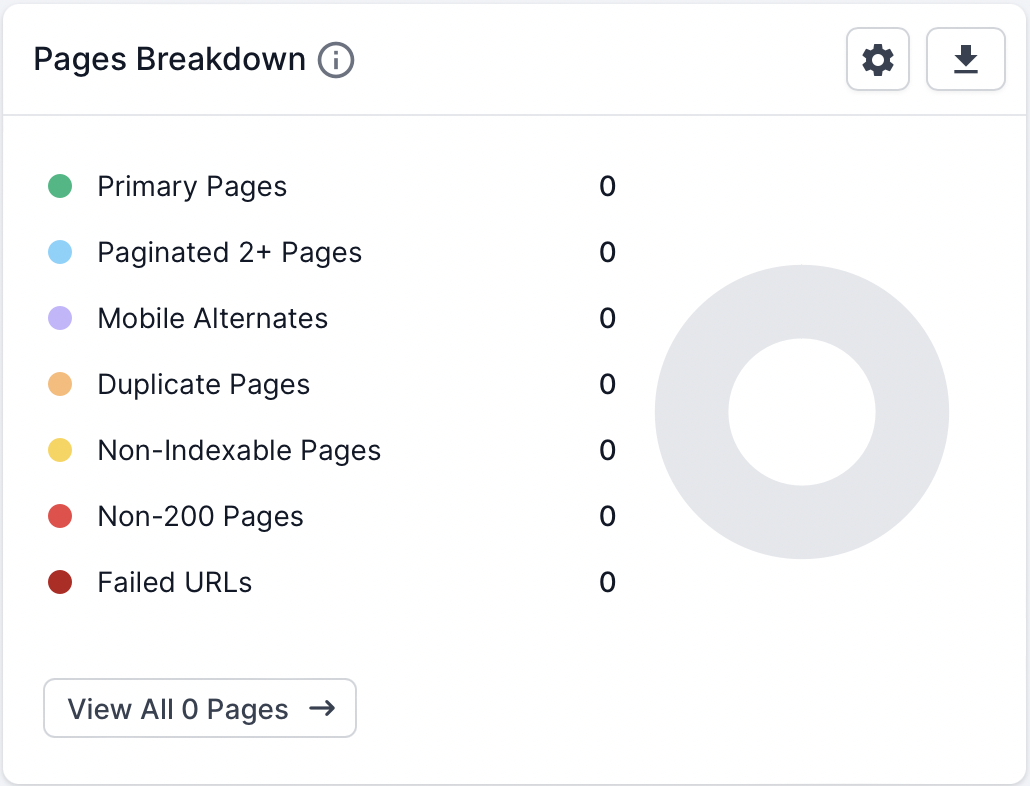
Navigate to the Links → Sitemaps → XML Sitemaps report. This report displays all the XML Sitemap URLs which Lumar fetched, parsed and all the metrics associated with the files.
If all the Sitemaps have responded with a 200 (live) HTTP status code but 0 zero URL count this indicates that Lumar’s crawler managed to fetch the file but either the file was empty or Lumar was not able to download and read the file.
If the XML Sitemap is not empty (it contains URLs) but 0 URLs are being found then the most likely cause is due to XML tag format errors.
To double check if the XML Sitemap(s) are using invalid XML tags, then submit the URLs to Google Search Console Sitemap report. The Sitemap report flags any unsupported file formats which can help to clarify if the errors are causing an issue with crawling.
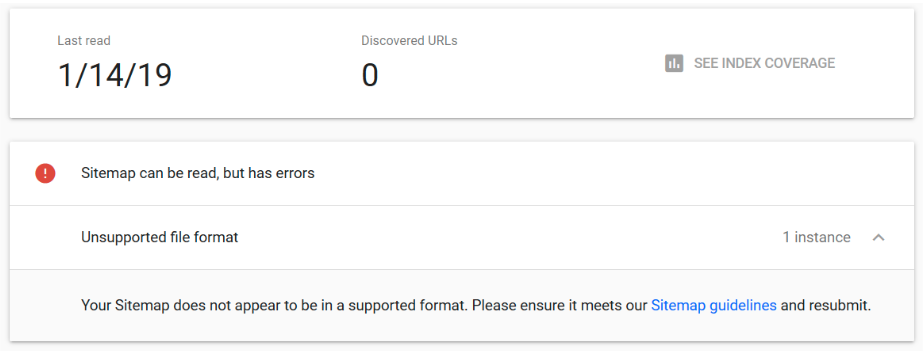
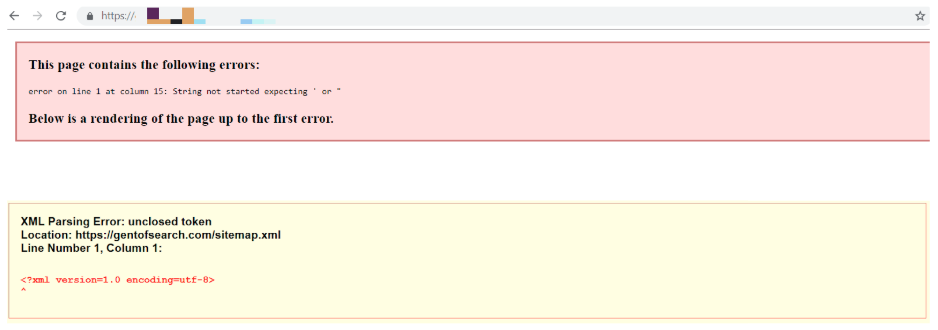
To identify which XML tags are causing the errors, open the Sitemap(s) in either Firefox or Google Chrome. When an XML Sitemap URL is loaded in a browser it will indicate which tag is causing the issue and where it can be found.
Blocked Sitemaps
Search engine crawlers, like Googlebot, will not be able to crawl XML Sitemaps if they have been blocked in the /robots.txt file with a Disallow: rule.
Lumar allows site owners to understand if Sitemaps are blocked using the /robots.txt file by displaying any blocked XML Sitemaps in the Broken/Disallowed Sitemap report.
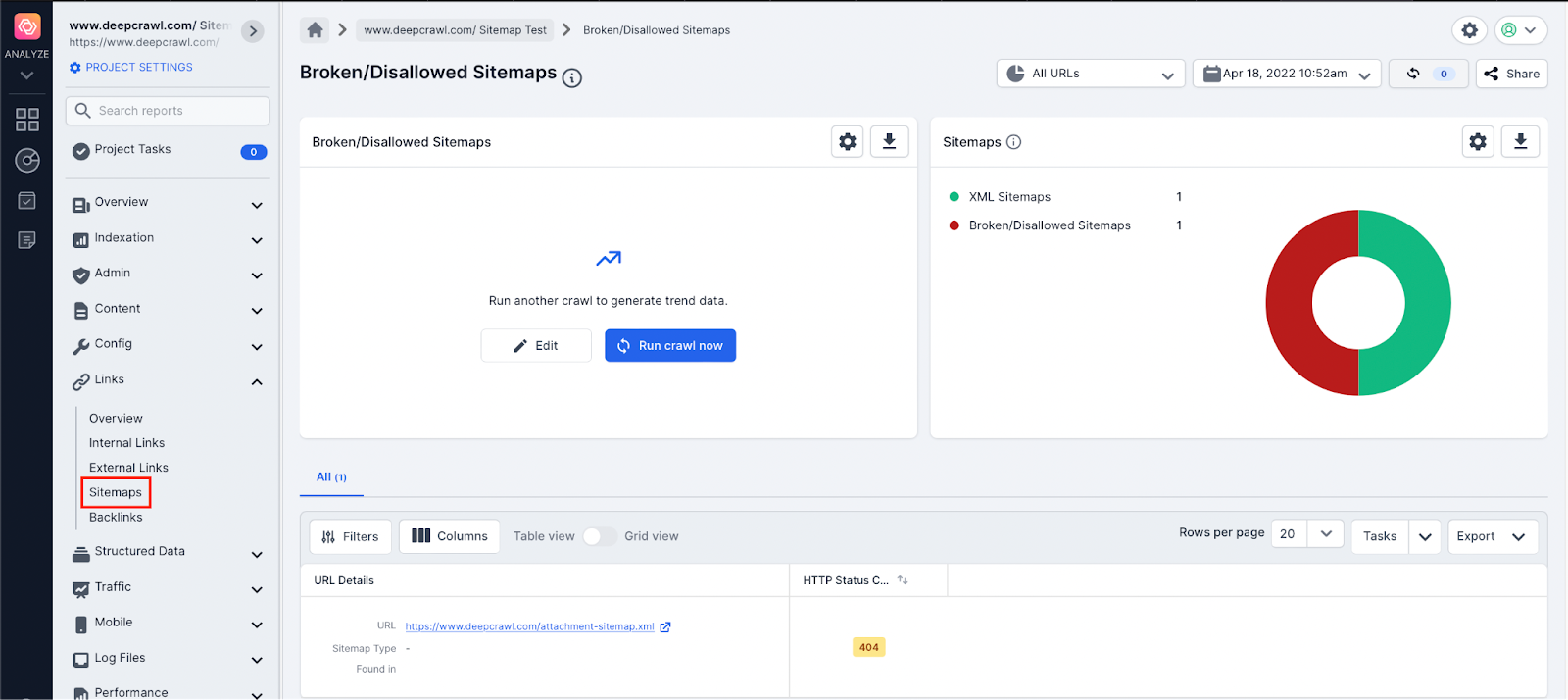
It is important that XML Sitemaps are crawled as it helps search engines discover new content, and it helps Google to better understand when pages were last updated using the lastmod XML tag (only if it is consistently accurate).
Google’s indexing system also uses Sitemaps as a canonical signal. This can be useful if large websites cannot implement stronger canonical signals (301 redirects or canonical tags) to indicate the preferred page to rank in search engine results.
Use the Broken/Disallowed Sitemaps report to identify the XML Sitemap URLs which are being blocked and the robots.txt Tester in Google Search Console to identify the specific Disallow: rule which is blocking the file.
Discovering Broken Sitemaps
Search engine crawlers, like Google, need to be able to fetch a live Sitemap file and parse its contents to discover new pages. If an XML Sitemap returns a 4xx (client error) or 5xx (server error) HTTP status code then web crawlers will not crawl and parse the contents of the file.
Lumar allows site owners to understand if Sitemaps are returning a 4xx or 5xx HTTP status code using the Links → Broken/Disallowed Sitemaps report.
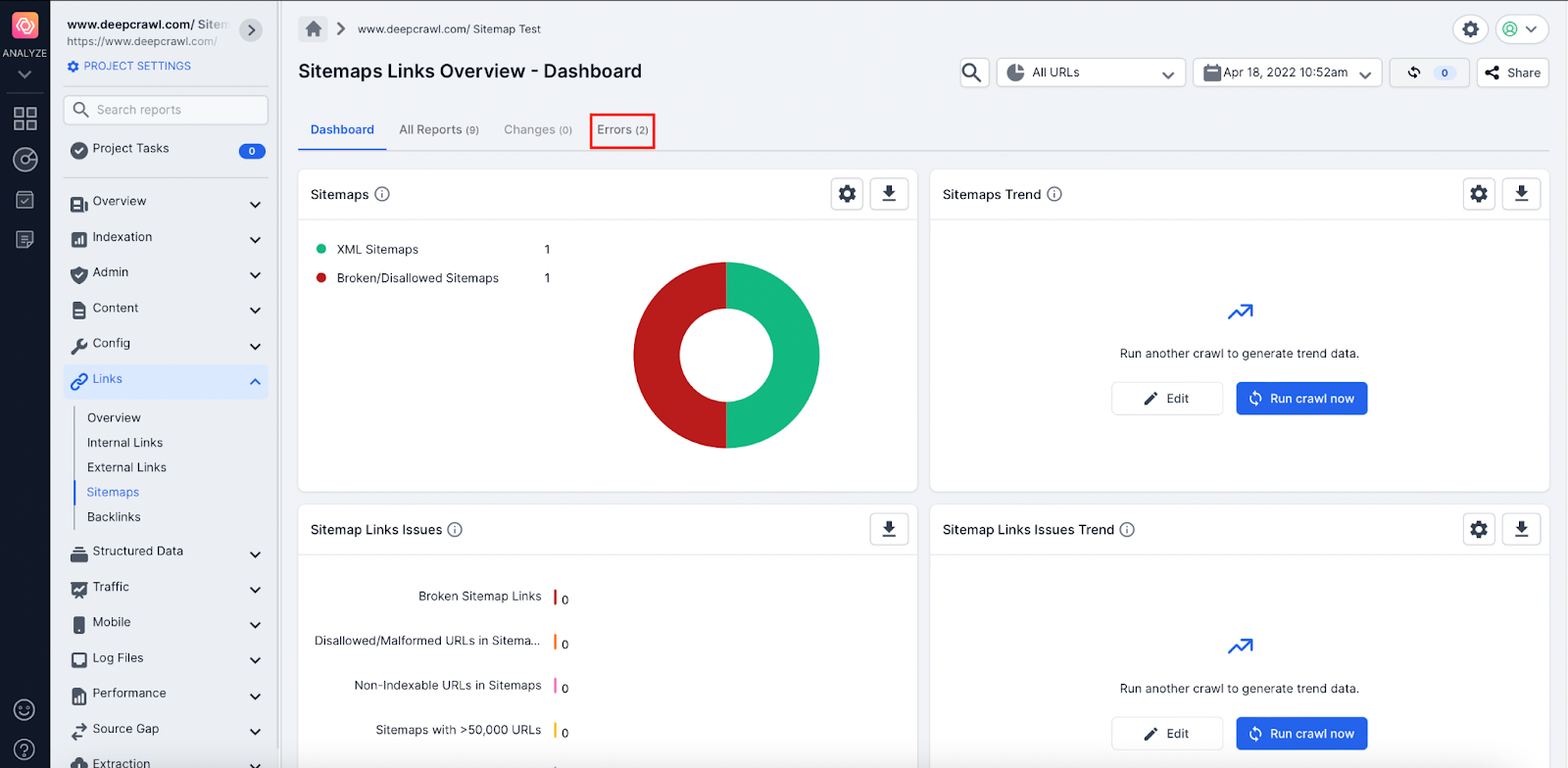
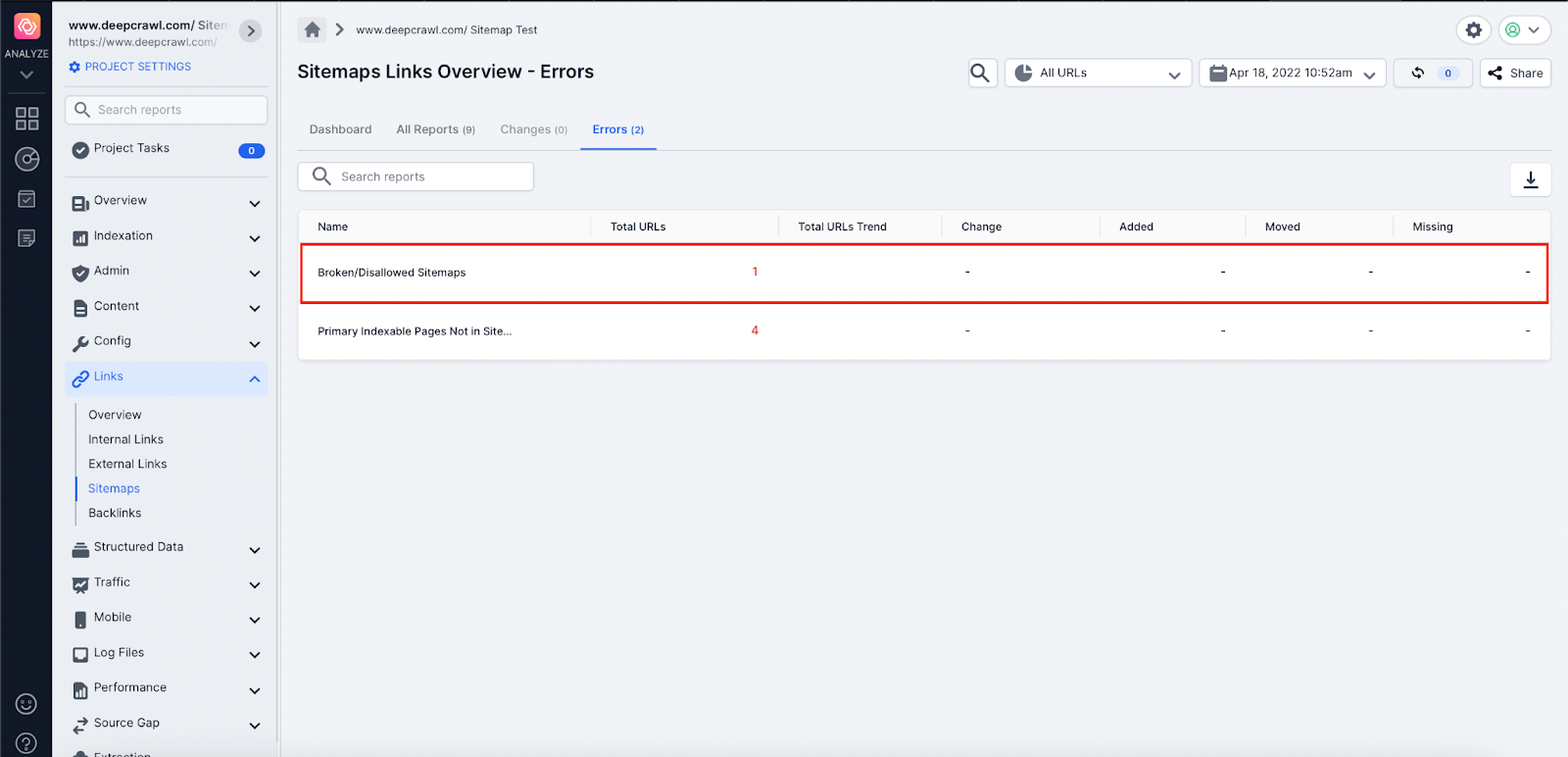
As already mentioned in the Disallowed Sitemap files section, it is important the search engines crawl and parse important XML Sitemap files to help discover new content. Any URLs found by Google in an XML Sitemap are also used as a canonical signal to help set the preferred page.
Use the Lumar Broken/Disallowed Sitemaps report to identify:
- Important Sitemaps which are broken and referenced in robots.txt and Sitemap Index.
- Old Sitemaps which are still referenced in the robots.txt and XML Sitemap Index.
- Incorrectly typed Sitemap URLs referenced in the robots.txt or Sitemap Index.
We have provided recommendations for each type of broken Sitemap:
Important Broken Sitemaps
Any important XML Sitemaps which are broken need to be updated and set live (returns a 200 HTTP status code) and the contents need to follow the current Sitemap best practice.
Old Broken Sitemaps
If a website relies on the /robots.txt file or Sitemap Index alert method, then it is important that any references to old Sitemap URLs are updated to the new Sitemap URL.
If no new Sitemap URL exists then the Old Sitemap should be removed.
Incorrectly Typed Broken Sitemaps
Again, If a website relies on the /robots.txt file or Sitemap Index alert method then an incorrectly typed Sitemap URL means that Google might not discover all XML Sitemaps (especially if URLs are unique to the platform e.g. /sitemap_gt260000.xml).
For any broken Sitemaps which look correct, check the URL carefully for any typos and update the /robots.txt and Sitemap Index file for the correct Sitemap location.
Over 50,000 URLs in XML Sitemaps
The Sitemap protocol requires that a Sitemap or Sitemap Index file should contain no more than 50,000 URLs or be over 50MB in size. Any Sitemap file which exceeds this limit is invalid and its contents will not be downloaded and extracted by search engines.
Lumar allows site owners to quickly identify invalid Sitemaps which exceed the 50,000 URL limit.
Any Sitemaps which exceed the limit of 50,000 URLs should be broken up into smaller files and the new XML Sitemap location should be included in the Sitemap Index or robots.txt file.
Inspect Sitemap and URL Location
It is important to understand the location of XML Sitemaps because the location of the XML Sitemaps determines what pages can be included in the file.
A Sitemap file location must include URLs that are on the same:
- Host
- Website directory
- HTTP protocol
website Directory
If a Sitemap file is located in a directory then the URLs within the Sitemap must be from the same directory.
Examples of URLs that are valid in the https://www.deepcrawl.com/blog/sitemap.xml Sitemap include:
https://www.deepcrawl.com/blog/
https://www.deepcrawl.com/blog/post-1/
Examples of URLs that are invalid:
https://www.deepcrawl.com/catalog/
https://www.deepcrawl.com/catalog/jedi/
Note: To avoid issues it is strongly recommended all Sitemaps are hosted in the root directory of the website (https://www.deepcrawl.com/sitemap.xml).
Host
A Sitemap should contain URLs from the same host as it is located.
Examples of URLs that are valid in the https://www.deepcrawl.com/sitemap.xml Sitemap include:
https://www.deepcrawl.com/
https://www.deepcrawl.com/blog/post-1/
Examples of URLs that are invalid in the https://www.deepcrawl.com/sitemap.xml Sitemap:
https://blog.deepcrawl.com/
https://marketing.deepcrawl.com/
Note: It is possible to have valid XML Sitemaps which are hosted on different hosts but it requires configuration. Please follow the instructions on the Sitemap protocol site.
HTTP Scheme
A Sitemap should include URLs that are on the same HTTP scheme as the host it is located on (https:// vs https://).
Examples of URLs that are valid in the https://www.deepcrawl.com/sitemap.xml Sitemap include:
https://www.deepcrawl.com/
https://www.deepcrawl.com/blog/post-1/
Examples of URLs which are invalid in the https://www.deepcrawl.com/sitemap.xml Sitemap:
https://www.deepcrawl.com/
https://www.deepcrawl.com/blog/post-1/
Review Sitemaps Locations With Lumar
By default, Lumar extracts and saves the URL location of Sitemaps it crawls.
Use the XML Sitemap report to understand the location, host and HTTP scheme of each Sitemap crawled by Lumar.
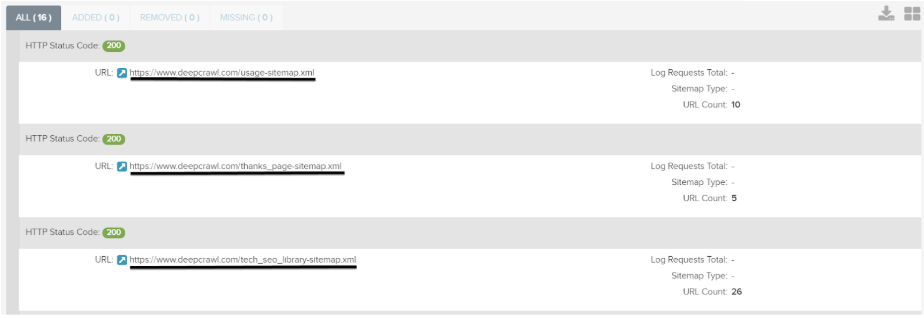
By default Lumar also crawls and extracts the URLs in each Sitemap and saves the source Sitemap where the URL was found.
All the URLs found in the XML Sitemaps can be found in the Links → Sitemaps → All Sitemaps Links report.
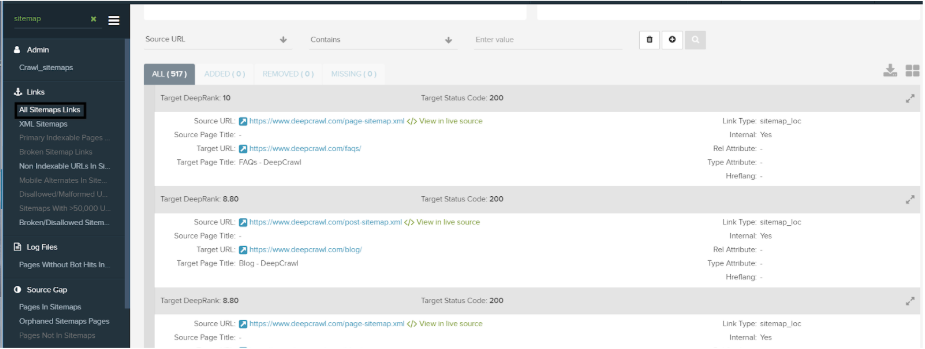
Use this report to identify:
- URLs not on the same host.
- URLs not on the same directory.
- URLs not on the same HTTP scheme.
To identify these Sitemap location issues:
1. Use the advanced filters in the segmentation feature at the top of the report.
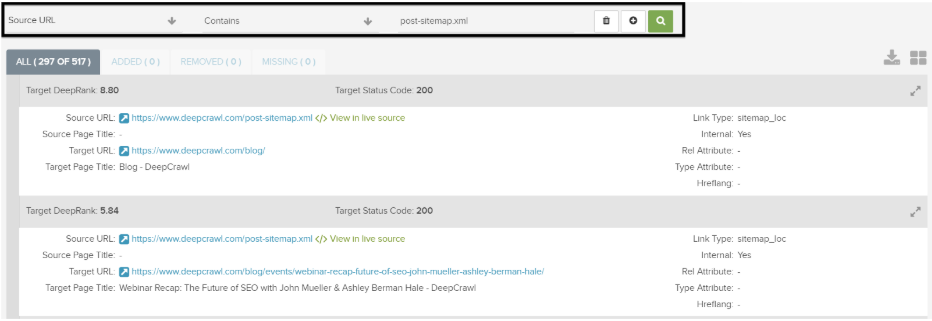
2. Set the Source URL metric to contain the Sitemap URL you want to inspect.
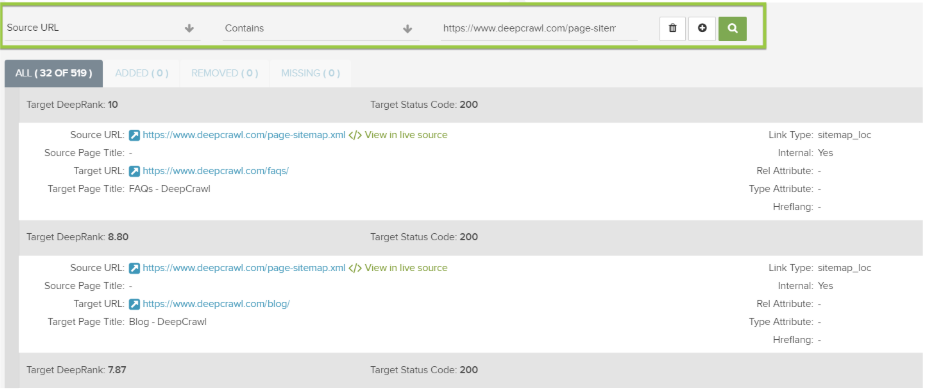
3. Add a new filter.

4. Select the Target URL and set it to Does not contain.
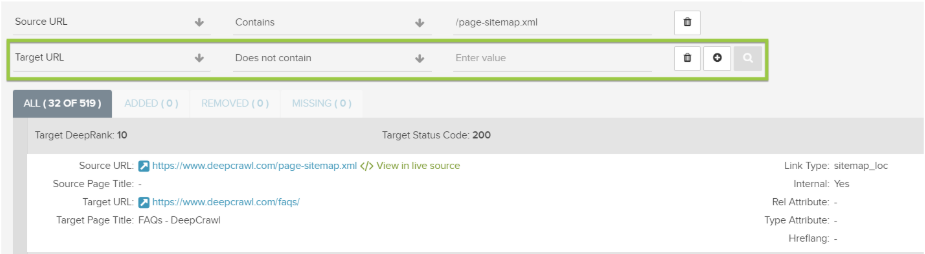
Depending on the issue you want to identify, input the following (only select one at a time):
- Host: Set the Target URL to the domain where the Sitemap is located.
- Directory: Set the Target URL directory where the Sitemap is located.
- HTTP Scheme: Set the Target URL as the HTTP scheme where the Sitemap is located (https:// or https).
If any URLs are found using the incorrect host, directory or HTTP scheme we recommend that the URLs in the Sitemaps are updated or removed.
Summary
Use Lumar to monitor and check XML Sitemaps are valid. Any invalid Sitemaps will be ignored by search engines which could affect the crawling and indexing of your website.
Also, we recommend reading the following official resources:



