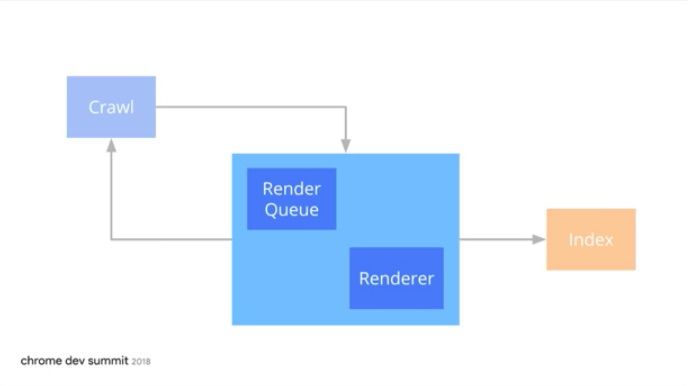

Lumar can now crawl JavaScript websites by using our page rendering service (PRS) feature. This release allows us to analyse the technical health of JavaScript websites or Progressive Web Apps (PWAs).
Page Rendering Service (PRS)
Lumar can use the page rendering service to execute JavaScript just like modern search engines. The page rendering service allows Lumar to discover links and content which is client-side rendered using modern JavaScript libraries or frameworks.
The page rendering service uses the most up-to-date version of Google Chrome for rendering JavaScript. For security and to ensure that we are up to date with web technologies, we update our rendering engine with a new release of Google Chrome whenever a stable update is available.
For all the latest features that Google Chrome supports we recommend referring to chromestatus.com or use the compare function on caniuse.com.
How is the PRS different from how Googlebot renders JavaScript?
At Google I/O 2019, Martin Splitt a Webmaster Trends Analyst at Google announced that the web rendering service (WRS) component of Googlebot uses the latest stable version of Chrome to render web pages.
This announcement now means that both Lumar’s page rendering service (PRS) and web rendering service (WRS) component of Googlebot are using the latest stable version of Chrome to render the web.
As our PRS has been designed to fetch and render pages similar to the behaviour of Googlebot and the WRS, and both are using the same stable release of Chrome, there should be few discrepancies in the types of web platform features and capabilities supported compared to what Googlebot can render.
For a full list of features that the latest stable version of Google Chrome supports we recommend referring to chromestatus.com or use the compare function on caniuse.com.
For information around WRS and Googlebot our team recommends the following resources:
- How Google Search indexes JavaScript sites
- Google I/O 2019: Google Search and Java Script Sites
- Fix Search-related JavaScript problems
- JavaScript: SEO Mythbusting
- Googlebot: SEO Mythbusting
How is the PRS different from how Bing renders JavaScript?
Bing has officially announced that Bingbot renders JavaScript when it is encountered. The Bing crawling team announced in October 2019 that Bingbot will now render all web pages using evergreen Edge. This means Bing’s crawler will now render using the most up-to-date stable version of Edge.
If you wish to better understand if Bingbot can render pages, then we recommend using the Bing mobile-friendly test tool – as it uses the same customisable rendering engine as Bingbot.
How does PRS work in Lumar?
Lumar is a cloud-based website crawler that follows links on a website or web app and takes snapshots of page-level technical SEO data.
The page rendering service works in Lumar as follows:
- Start URL(s) and URL data sources are inputted into the project settings.
- The web crawler begins with the start URL(s) based on the project settings.
- The start URL is fetched using the PRS.
- The PRS fetches a page and will wait a maximum of 10 seconds for the server to respond and page to load.
- The PRS will then wait a maximum of 5 seconds for any custom injection scripts to run.
- Once the page responds and loads, and the custom scripts are run the crawler grabs both the raw HTML and rendered HTML of a page.
- The rendered HTML is parsed, and the SEO metrics are stored by the crawler.
- Any links discovered in the rendered HTML of the page are added to the crawl scheduler.
- Example continues to crawl URLs which are found and added to the crawl schedule.
- The crawl scheduler waits until all web documents on the same level (click depth) have been found before the crawler can begin crawling the next level (even if lower level pages are in the URL crawl queue).
- All SEO metrics fetched by the crawler is passed to our transformer which processes the SEO data and calculates metrics (e.g. DeepRank).
- Once the transformer has finished analysing the data, it passes it to the reporting API, and the technical reports in the Example app are populated.
This process allows us to crawl and render the DOM which enables us to crawl websites which rely on JavaScript frameworks or libraries.
How to set-up JavaScript rendering in Lumar
To enable and set-up JavaScript rendering in Lumar we recommend reading How to Set-up JavaScript rendering in Example.
Make sure PRS can crawl your website
Before crawling your website with the PRS, our team recommends reviewing the specifications below.
PRS and anchor links
It’s important to remember that that JavaScript sites need to follow current link architecture best practices to make sure that the PRS can discover and crawl them.
Lumar will only discover and follow links which are generated by JavaScript if they are in an a HTML element with an href attribute.
Examples of links that Lumar will follow:
- <a href=”https://break-hearts-not-links.com”>
- <a href=”/get/to/the/crawler.html”>
Examples of links PRS will not follow (by default):
- <a routerLink=”I/am/your/crawler.html”>
- <span href=”https://example.com”>
- <a onclick=”goto(‘https://example.com’)”>
This is in line with current SEO best practice and what Google recommends in its Search Console help documentation.
PRS and dynamic content
It is essential to understand that rendered HTML elements which require user interaction will not be picked up by the PRS. So any critical navigational elements or content which do not appear in the DOM until a user clicks or gives consent will not be captured by Lumar.
Examples of dynamic elements the PRS will not pick up:
- Onclick Events
- onmouseover and onmouseout Events
- Deferred loading of page elements (lazy loading)
This default behaviour is in line with how Google currently handles events after a page has loaded.
For further information about how Google handles JavaScript:
- Ask the Expert: Bartosz Goralewicz Answers Your JavaScript Questions
- The Chaotic Landscape of JavaScript with Bartosz Goralewicz & Jon Myers
- Google Reveals JavaScript Rendering Secrets at Chrome Dev Summit 2018
- A Search-Marketer’s Guide to Google IO 2018
- Essential JavaScript SEO tips – JavaScript SEO
PRS is stateless when crawling pages
When the PRS renders a page, it is stateless by default, meaning that:
- Local storage data is cleared when each page is rendered.
- HTTP cookies are not accepted when the page is rendered.
This also means that by default any content which requires users to download cookies will not be rendered by the PRS.
This in line with Google’s own web rendering service specifications.
PRS declines permission requests
Any content which requires users to consent is declined by the page rendering service by default, for example:
- Camera API
- Geolocation API
- Notifications API
This in line with how Google’s web rendering service handles permission requests.
PRS static geo IP address
The PRS is unable to run a rendered crawl with a specified geo static IP. All requests from the rendered crawler will come from either 52.5.118.182 or 52.86.188.211, both of which are based in the United States.
If you need to whitelist us to allow crawling, you should add this IP address to your whitelist.
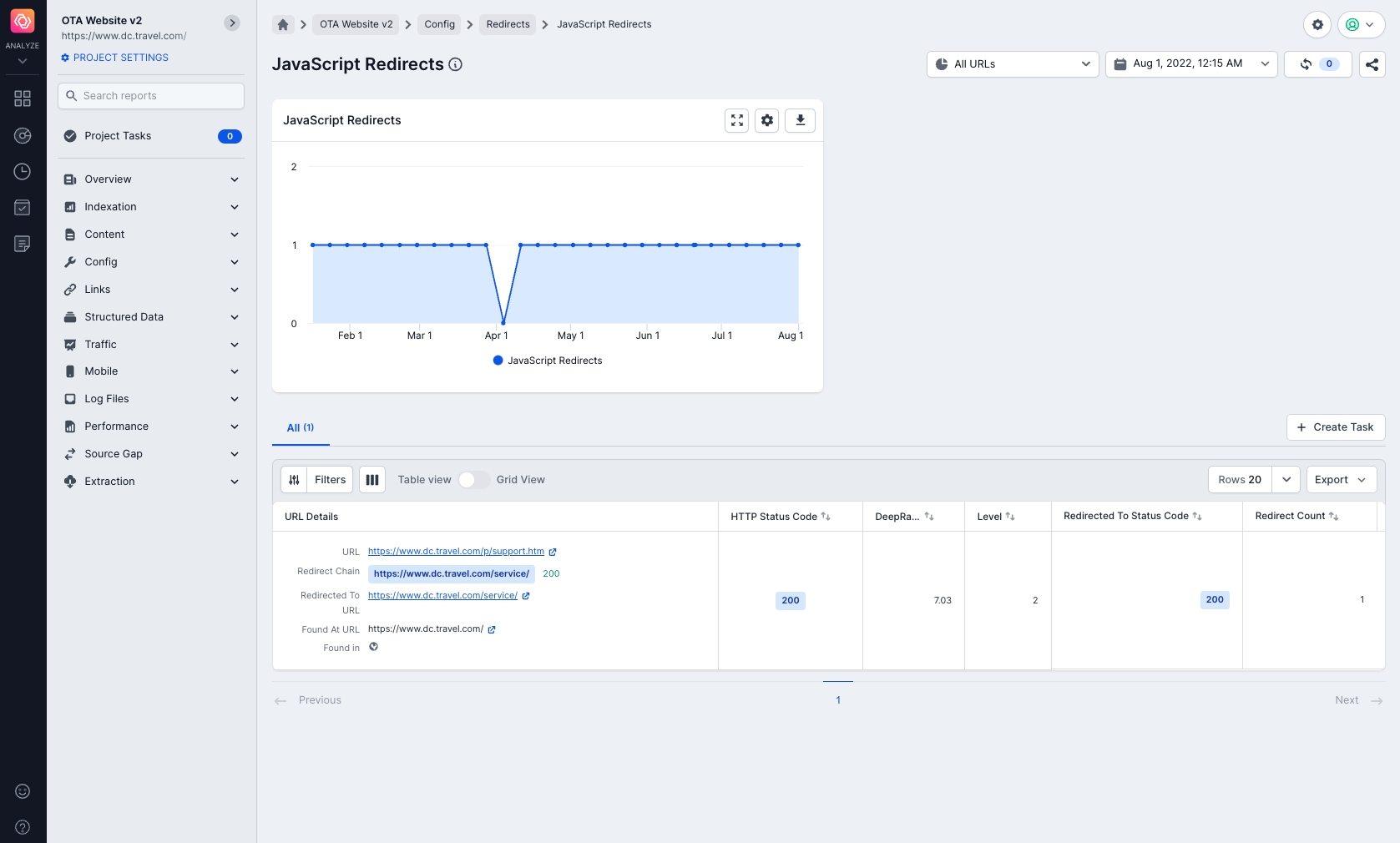
PRS follows JavaScript redirects
The PRS detects and follows JavaScript redirects. They are treated like normal redirects when being processed and are shown in the JavaScript Redirects Report in Config > Redirects > All Reports.
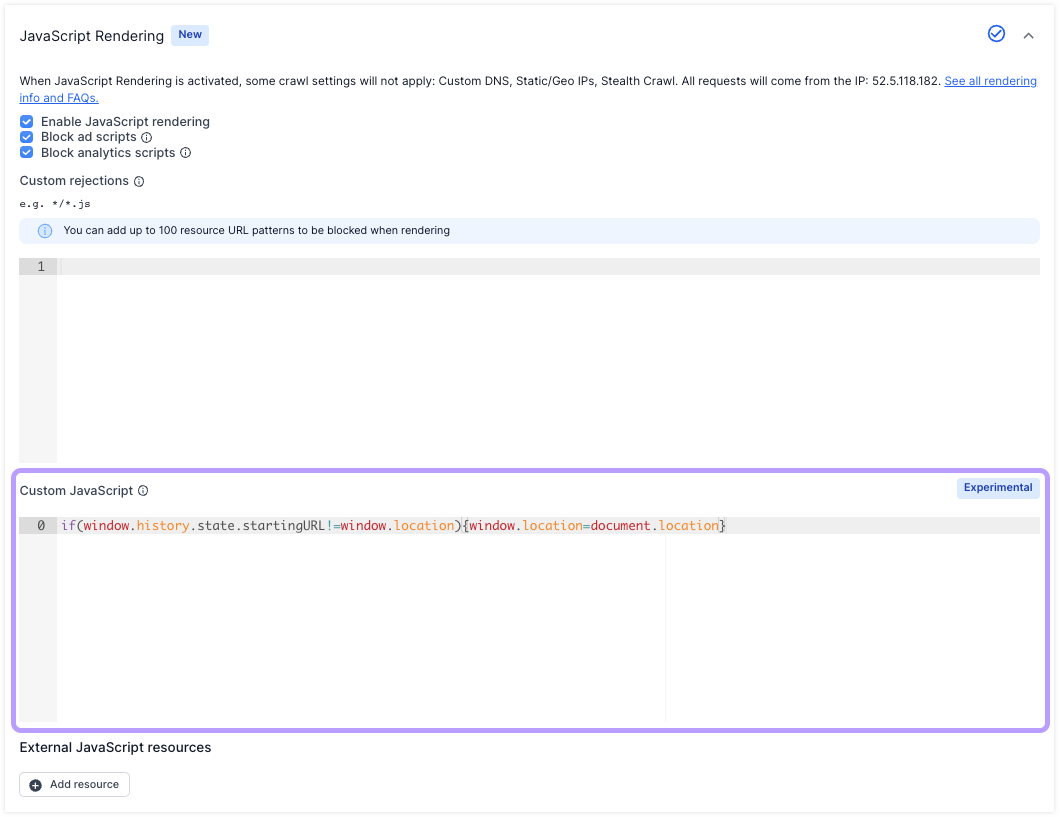
PRS not able to detect state changes
The PRS is unable to detect state changes by default.
If your website uses state changes, the PRS can detect them by turning them into a proper location change by adding the following script in the “Custom Script” field.
if(window.history.state.startingURL!=window.location){window.location=document.location}
PRS disables certain interfaces and capabilities
The PRS disables the following interfaces and capabilities in Google Chrome:
- IndexedDB and WebSQL interfaces
- Service Workers
- WebGL interface is disabled
This is in line with Google’s web rendering service specifications when handling certain interfaces and capabilities.
PRS block analytics and ad scripts
The PRS by default blocks common analytics and advertisement scripts. This is because the PRS uses an off-the-shelf version of Chrome, would execute many analytics, advertisement, and other tracking scripts during a crawl. To stop analytics data from being inflated while crawling with PRS we block these scripts by default.
Analytics Scripts Blocked
A list of analytics tracking codes Lumar blocks by default:
- *//*.google-analytics.com/analytics.js
- *//*.google-analytics.com/ga.js
- *//*.google-analytics.com/urchin.js
- *//*stats.g.doubleclick.net/dc.js
- *//*connect.facebook.net/*/sdk.js
- *//platform.twitter.com/widgets.js
- *//*.coremetrics.com/*.js
- *//sb.scorecardresearch.com/beacon.js
- quantserve.com
- service.maxymiser.net
- cdn.mxpnl.com
- statse.webtrendslive.com
- *//s.webtrends.com/js/*
Advertisements Scripts Blocked
A list of advertisement tracking codes Lumar blocks by default:
- *//pagead2.googlesyndication.com/pagead/js/adsbygoogle.js
- *//*.2mdn.net/ads/*
- *//static.criteo.net/js/ld/*.js
- *//widgets.outbrain.com/outbrain.js
- *//*.g.doubleclick.net/*
- *//c.amazon-adsystem.com/aax2/apstag.js
- *//cdn.taboola.com/libtrc/dailymail-uk/loader.js
- *//ib.adnxs.com/*
- *://*.moatads.com/*/moatad.js
- track.adform.net
Block custom analytics or advertisement scripts
Any custom scripts which are not critical to rendering content should be blocked. To block scripts, use advanced settings > spider settings> JavaScript rendering > custom rejections.
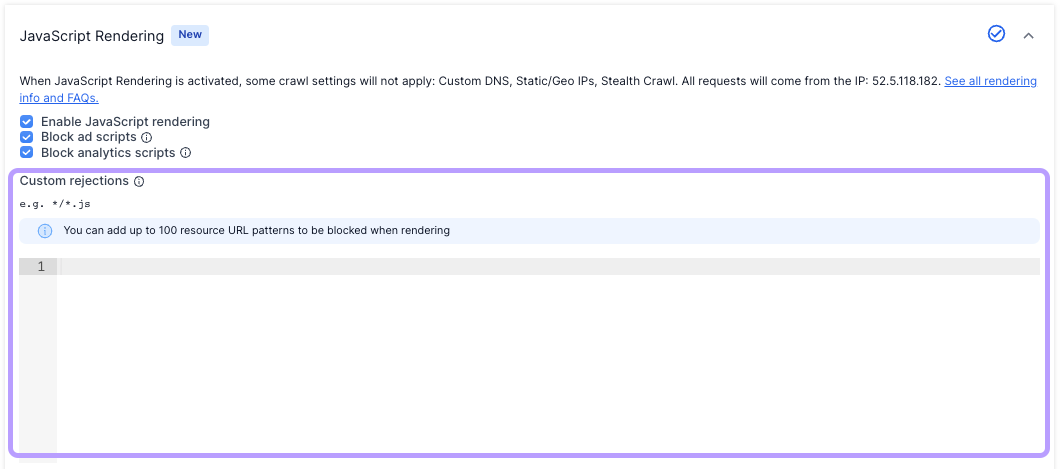
PRS custom script injection
The PRS allows custom scripts to be injected into a page while it is being rendered. This unique feature allows for additional analysis and web page manipulation.
The page rendering service allows custom scripts to be added by:
- Adding up to 10 JavaScript URLs to “External JavaScript resources“
- Adding a script to the “Custom JavaScript” input.
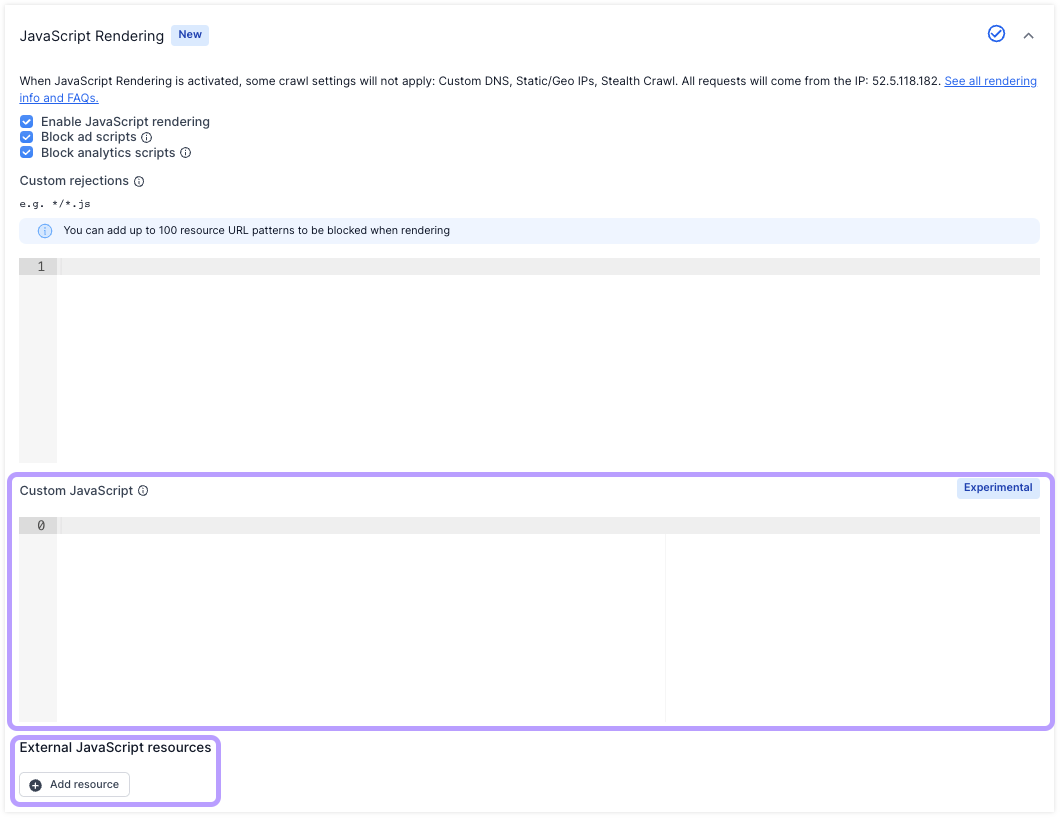
To pull data injected onto the page using custom injection, output needs to be added to the page and then extracted using the Custom Extraction feature.
This page rendering functionality allows users to:
- Manipulate elements to the Document Object Model (DOM) of a page
- Analyse and extract Chrome page load timings for each page
- Create virtual crawls and change behaviour of Example
Learn more about using Example custom script injection to collect Chrome page speed metrics.
Frequently Asked Questions
Why is JavaScript crawling not working?
Our team recommends reviewing the PRS technical specifications above and make sure your website follows JavaScript SEO best practices.
If your website is following JavaScript SEO best practices, then we’d also recommend reading our debugging blocked crawls and crawling issue guides.
If your website is still not able to be crawled then we’d recommend getting in touch with our support team.
How fast should I crawl my website with the PRS?
This will depend on your web server and technical stack on your website.
If the crawl speed is set too high, this could overload a website’s server as Lumar will be making a high number of requests. This is because as the PRS loads a page it requests multiple resources (JavaScript, CSS, Images, etc.).
Our team always recommends running a sample crawl first to test the speed settings, to make sure that your site’s server can handle the PRS.
If you are unsure of what speed to set the crawler, please contact our Customer Success team using the help portal in the Lumar app. Click on the question mark in the bottom left of the screen, and then choose ‘Get in Touch’ at the top of the pop-up window.
How do I crawl using the AJAX crawling scheme?
At the time of writing, Lumar still supports the AJAX crawling scheme. For more information, please read our 60-second Example AJAX crawling guide on how to set this up.
Please be aware, even though Lumar supports the AJAX crawling scheme, Google officially announced they depreciated support for this crawling scheme.
Both Google and Bing have both recently recommended dynamic rendering to help JavaScript-generated content to be crawled and indexed. If a site still relies on the AJAX crawling scheme, then this new solution by Google can help your JavaScript-powered website to be crawled and indexed.
What is the maximum timeout for the PRS?
The maximum render timeout period is 15 seconds per page. This is broken down into two steps:
- PRS has a maximum timeout period of 10 seconds for a page to respond and for content to load, then
- It will wait for a maximum of 5 seconds for any custom scripts added to the settings to load.
If the page does not complete rendering within the 15 second timeout period, then the PRS will take whatever content has been loaded on the page at that point for processing.
The page rendering service will always evaluate custom scripts as long as the server responds within 10 seconds (i.e. time to first byte).
This means that if your page takes 20 seconds to render, we will use whatever content is rendered at the 15 second point, but anything after that will be ignored.
If the server takes 14 seconds to respond to our initial request, then we will only allow it to render for one second before taking a snapshot of the page for processing.
Does JavaScript performance affect PRS crawl rate?
Yes. If website’s web performance is slow then the PRS will crawl at a slower rate.
To identify if pages are slow we recommend using the Google Lighthouse or PageSpeed Insights tools to identify slow pages on your website.
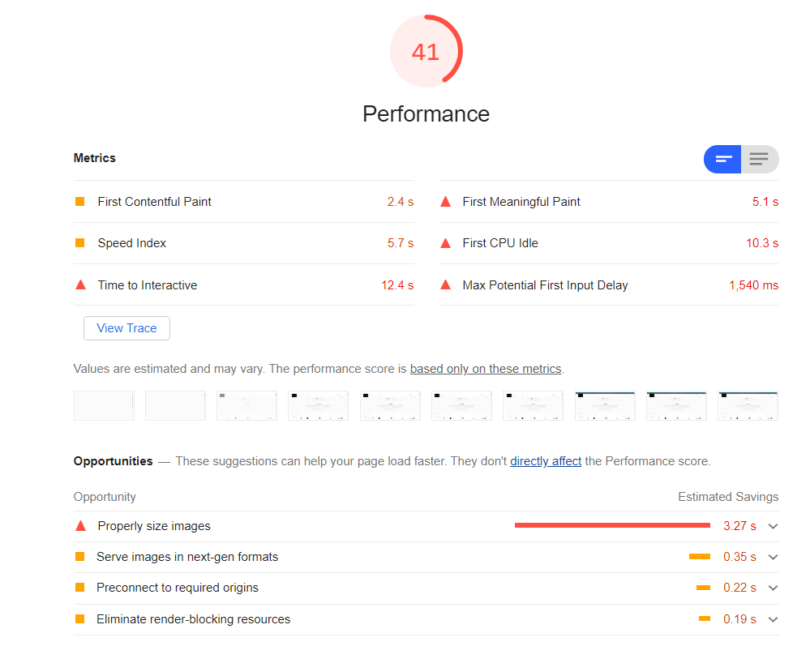
What is the “render_timed_out” error?
If you receive a “render_timed_out” error, this means that when we tried to render the page, the server did not respond at all within the max timeout of 15 seconds.
This error is only used when we had no HTTP response headers and no body HTML at all.
If you are seeing this error message consistently throughout a crawl, it is likely that your server stopped responding to our crawler during the crawl – it may have been overwhelmed by requests (in which case, reducing the crawl rate can help).
Page Rendering Service Feedback
Our team sees the page rendering service as being a flagship feature in Lumar which will give us the ability to add new features like Chrome page load timings. If you have any requests or ideas about what we should be doing, then please get in touch.