

If you’ve had the pleasure of meeting any of the DeepCrawl team, you’ll know that we don’t do things by halves. As such, we’ve got a second serving of recaps from September’s BrightonSEO, so that you have the need-to-know information from some of the day’s stellar sessions.
If you haven’t done so already, you can find the first part of our event recap here and our recap of Rand Fishkin’s inspiring keynote is here. Without further ado, let’s dive into the talk recaps, which include slides and videos where available. Enjoy!

Michael King – Software Testing for SEO
Talk Summary
Mike’s insightful talk walked us through the world of software testing and how it can help avoid headaches when developers and SEOs don’t talk enough. We learnt so much, including: different types of tests and when they are applicable, how to generate test cases, how to get the right data into tests, how to set up testing as part of deployments and how to set up alerts.
Key Takeaways
SEO horror stories
Mike kicked off his talk by sharing some of the responses he received to the question:
People came back with some nightmare situations including: the noindexing of a live site, millions of pages deindexed due to bad JavaScript implementation and even threats of legal action by a client who had decided to disallow their whole site in robots.txt.
The root cause of the problem is that SEOs and developers don’t talk enough and, Mike believes, automated SEO testing is the solution to avoid further SEO horror stories.
But first a bit about modern web development
A lot of modern software frameworks follow a Model-View-Controller framework that separates concerns between data, logic and the front-end (as demonstrated below).
For example, you could use Laravel to define the data structure (Model) and control the logic (Controller), while using React to define the display (View).
When a request for a URL is sent they are pointed to controllers which return the right views with data from the right models. Mike pointed out that this is the reason why segmented crawls are important, in order that developers can implement recommendations.
Modern development workflows
The waterfall model of software development rarely makes sense anymore because it’s too slow. Everything is agile now, with teams tackling small pieces of functionality in short sprints.
Engineering teams now use continuous integration models that allow teams and individuals to push their code as and when they complete it. Some of Mike’s clients are deploying ~70 times per day.
What is automated testing?
Automated testing is used as a safeguard in deployment pipelines to ensure that there is a standardised process when code is deployed.
Testing which is deemed to be critical to the infrastructure of the website will cause the deployment to fail if certain criteria are not met, meaning developers will have to go back to the drawing board.
Types of automated tests:
- Unit testing – testing of individual functions or procedures to make sure that they work.
- Integration testing – testing how logic comes together to build the bigger system.
- UI testing – testing of the front-end interface.
Headless browsers were actually built for automated tests, rather than scraping JavaScript rendered content. Mike recommends reading why the Chrome DevTools team built Puppeteer.
How does automated testing apply to SEO?
Mike has previously talked about how you can use task runners and the Alderson-Anderson scale to help get developers to implement recommendations.
Let’s go back and see how automated testing could help avoid some of the horror stories Mike introduced at the beginning:
Unit testing could have caught the noindex tag on a live site.
A unit test failure condition could also have caught the client who disallowed their site.
A UI or integrated test would have caught the key body content missing from the HTML version.
What is an SEO’s role?
Conducting an SEO audit is similar to the work carried out by QA Engineers. Crawling the HTML version is a bit like integration testing because you’re seeing what the software spits out when all of the systems come together. Crawling the rendered version is a bit like UI testing because you’re looking at the results when the UI is rendered.
An SEO’s role is to help plan the tests that QA Engineers, Product Managers and Developers use to build into systems. Here are a few examples of tests SEOs can plan:
Tools for automated testing in SEO
Mike finished up by taking us through some tools that can help get you off the ground with automated testing:
- Jenkins – A tool used by many development teams who have adopted continuous integration. Jenkins allows you to get failure alerts in Slack, Jenkins’ logs or piped into MySQL.
- Crawlers – You’ll want a headless and text-based crawler to spin up pages and run tests on a fixed-list of pages that represent all public facing routes.
- Kantu Browser Automation tool – See how browser automation tests work with a browser automation tool.
- Codeception – Helpful for testing sites in a PHP related environment including WordPress.
Barry Adams – Information Architecture and SEO: Laying The Foundations of Success
Talk Summary
Barry’s swear-filled talk showed how applying good Information Architecture practices results in an incredibly SEO-friendly website. With good application of IA, a site’s structure, navigation and taxonomy will be optimised for visibility in organic search results.
Key Takeaways
What is technical SEO?
Technical SEO is about information retrieval. Barry recommends reading the Stanford Introduction to Information Retrieval which is freely available.
Web search engines are made up of crawlers, indexers and rankers and a simplified pipeline for how they work can be seen here:
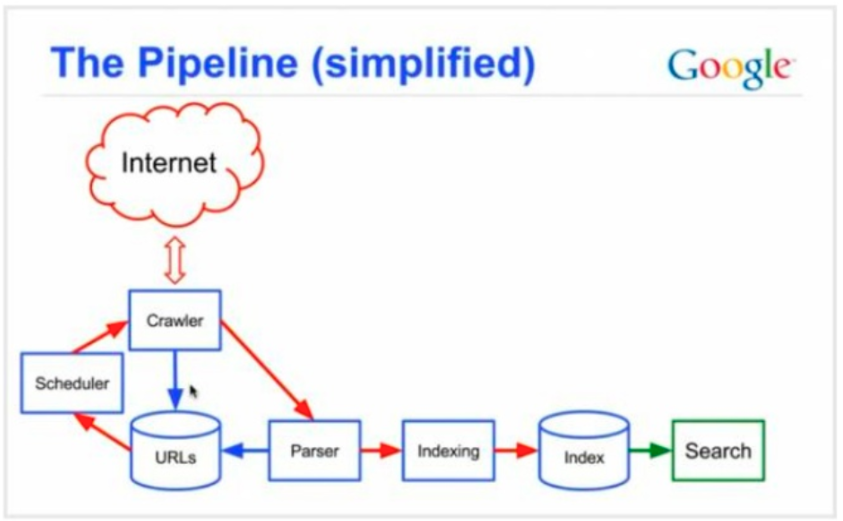
The three pillars of SEO are:
- Technology – This is related to crawling and is about load speed, crawl optimisation, mobile SEO, JavaScript and international SEO.
- Relevancy – This is related to indexing and is about keyword/topical focus, information architecture, page structure, content quality, structured data and accessibility.
- Authority – This is related to query engines, ranking and includes a focus on link building, internal linking and social signals.
Technical SEO issues and fixes
Barry then took us through some of the technical SEO issues he has encountered, how he fixed them and the lessons he’s learned.
Structured data & rich snippets
Everyone wants review snippets with star ratings for their pages in search. Barry made some for his site but Google eventually flagged them as spammy. In response, Barry wrote a post about how AMP can go to hell.
Barry saw that review markup in the footer was impeded by client-side JavaScript on a client’s site. This meant that the review snippet wasn’t able to appear in search. After moving the review markup to the head, the review snippets then appeared in search.
Lessons learned:
- JavaScript is evil.
- If you want rich snippets in Google, put schema.org markup in the head of the page’s HTML source code.
- JavaScript above schema.org markup may break Google’s processing of the structured data.
Hreflang
Hreflang is a pain in the ass, even John Mueller says so. It’s very difficult to get it right the first time around.
TBH hreflang is one of the most complex aspects of SEO (if not the most complex one). Feels as easy as a meta-tag, but it gets really hard quickly.
— John (@JohnMu) February 19, 2018
Google has a two-step indexing process where the HTML version is indexed first, followed by the rendered version of the page. Barry believes crawling and indexing of the HTML happens at the same time.
On a client’s site, an iframe was causing the head of the page to close prematurely, meaning Google wasn’t processing the hreflang below. As a result the iframe was moved below the hreflang to the bottom of the head. This change resulted in the hreflang being processed, which could be seen in the International Targeting report in Search Console.
Lessons learned:
- JavaScript is evil.
- Be very careful with JavaScript that inserts iframes into the head of a page’s rendered code. This is something that Google Tag Manager does.
Load speed
Very few sites are actually fast. You can use tools like GTmetrix and WebPagetest to check how fast a page is to load. Barry has found that if you look at the content breakdown by MIME type, a big chunk of the number and size of requests are from JavaScript files.
For a client’s site, Barry has been able to reduce the number of JavaScript requests and the size of compressed and uncompressed JavaScript files to improve the load speed. These load speed optimisations also improved the number of pages Googlebot was crawling per day and reduced the time Googlebot spent downloading a page as well as dramatically increasing visibility in search.

Lessons learned:
- JavaScript is evil.
- Faster sites mean more pages crawled by Google in the same amount of time.
- Improving load speed has greater benefits than just improving user experience.
Redirects
Barry recommends reading Sergey Brin and Larry Page’s original research paper on a prototype version of Google. They talk about a damping factor which sees the dilution of PageRank the more links a page has. Google have confirmed that the damping factor still exists and that the amount of PageRank that dissipates through a redirect is the same as that which is lost through a link.
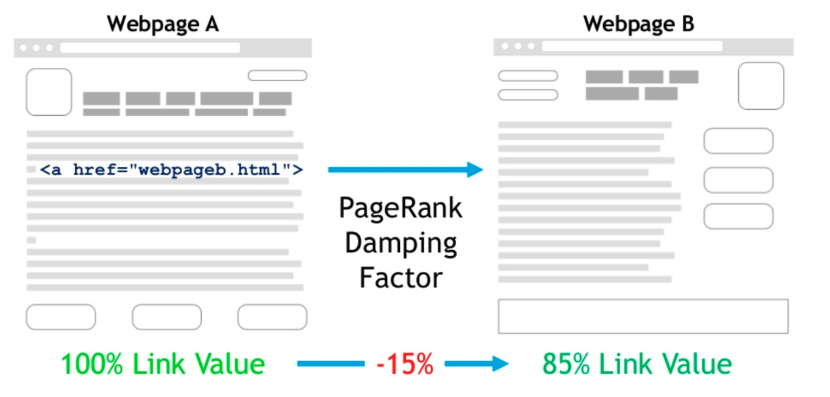
On a client’s site, Barry found a large volume of 302 redirects by crawling the site with DeepCrawl. Once the redirects were fixed, there was a much larger number of primary pages and the site saw an uplift in traffic.
Lessons learned:
Redirects bleed link value. Minimising internal redirects preserves link value and helps preserve traffic.
JP Sherman – Deliver Discovery & Revenue by Optimizing On-Site Search
Talk Summary
On-site search is a critical aspect of delivering the content that your users are looking for and the revenue your business relies on, yet most of the time, on-site search is only superficially addressed. JP spoke about how to optimize your site search, create feedback loops to measure content efficacy & search UI/UX to elicit good user behavior.
Key Takeaways
The importance of onsite search
JP enjoys connecting people to the information that they’re looking for and is responsible for optimising onsite search at Red Hat.
Only 18% of organisations devote resource to optimising onsite search, but 55% of users will abandon your site if they can’t find what they’re looking for. Google have set high standards and people remember when they don’t find what they’re looking for. Users expect to find what they want or something relevant and if they don’t, this will result in lost revenue.
Measuring onsite search
Site search can be broken down into the areas of findability, passive and active behaviors, features and result set quality. JP looked into each of these areas looking at how to measure and improve them.
Findability
Findability refers to the ease with which people can find pages on your site and impacts a lot of overlapping areas.
Measuring findability effectively involves looking at what people do, how they behave, how they react and how the content is presented.
Active behaviours
Active behaviours refer to when a searcher is actively seeking information to answer a specific query. These behaviours can be measured by looking at use of keywords, CTRs, conversions, no results, zero clicks and instances.
JP doesn’t see keywords as bags of words, but rather keywords are the vehicle through which user intent is expressed. Users are actively applying acceptance and rejection criteria to results as soon as they can see them, so the perception of value must be immediate to entice the searcher.
It’s important to split keywords into different buckets such as: high volume, low intent keywords (top of the funnel) and low volume, high intent keywords (middle of the funnel).
Passive behaviours
Passive behaviours refer to times where information hasn’t been actively requested. These can take a bit of development to be able to measure, with metrics like consumption, dwell time and time from query to conversion.
JP really likes using the time from query to conversion as a success metric and this is something he has been able to reduce drastically at Red Hat.
Search features
Search features are the different components of search and can include: autocomplete, autosuggest, keymatch, knowledge graph and natural results.
Adding in new search features can see some great results. Red Hat have added in their own knowledge graph to onsite search which has seen CTRs increase from 12% to 72%. Generally when it comes to CTRs, JP uses 75% as the benchmark CTR he works towards (Google have a CTR of 68%).
Result set quality
Result set quality quite simply refers to the quality of the results you are returning in onsite search. This can be measured by looking at: average rank, content impressions, keyword CTR, consumption and conversion from keyword.
How to improve SERPs
The SERP is the first thing users see after searching so it’s critical what is returned is relevant. Look at how you can improve: SERP design, snippet design, contextual bias, search features, respecting users’ time.
Try adding features like auto-suggest which helps by recommending queries that search engines might be looking for and auto-complete which reduces the steps between query and discovery.
No matter how refined onsite search is, there will always be times when it fails. To counter this, make sure to implement easily recognisable alternative paths that users can go down e.g. tips to search again or a way to submit feedback.
Use geo-context to recognise where a user is from and personalise their results accordingly, because the same keyword can have different intent based on the user’s location.
Red Hat have developed their own Knowledge Graph to help users searching with high volume, low intent keywords.This allows the user to immediately focus their intent when the query intent isn’t clear.
How to improve onsite search results
Optimise things like: content, metadata, markup, internal linking etc.
Don’t forget about keyword meta tags. They aren’t useful for search engines any longer, but are really useful for optimising onsite search.
Measure content efficacy by starting with the end result and tracing it back.
Testing is crucial, so always have A/B tests on the go. 1 in 4 of JP’s tests won’t work but you’re learning things when they don’t work as well as when they are successful.
Make sure you disambiguate searches, where the same words have different meanings.
Design with mobile in mind and consider that more visual search results might be preferable depending on what the user is expecting.
Ross Tavendale – Data Journalism: A Practical Guide to Winning Big Links
Talk Summary
Ross taught us how to use data journalism as a tactic to win links from the biggest publications in the world. From pulling data, to creating assets, to pitching to journalists, Ross took us through the complete life cycle with Type A Media’s complete methodology and documentation that they use with their clients every day.
Key Takeaways
Expensive flops
Back in 2012, Ross had won an airline as a client. They were migrating the airline to a new domain and wanted to build them some new links with their £50k per month retainer.
With lots of money to spare, Ross went to the creative department for an ideation session to see how they could spend this money. Some ambitious ideas came out of the session but the net result was an infographic which ended up receiving no links.
The problem was that the ideation was coming through the lens of the people in the room, some different perspectives were needed.
RAPTOR methodology for gaining big links
Ross and his team use the RAPTOR methodology for building links and Ross took us through the first three letters of this acronym: Research, Angles, Pitches.
A RAP sheet helps to summarise all of the data that will be pulled in (Research), how many stories can be built (Angles), and who will care about it (Pitches). If you execute on three angles and three headlines, that’s 9 pitches and you’d only need to be successful 11% of the time rather than relying on a 100% success rate, as in the airline infographic example.
Start with the audience
Facebook Insights is your starting point for knowing your audience. If you have first-party data on your customers then you can upload this to help enrich the data on your audience. Look for the outliers.
Looking at the people who like casino games, Ross found through Facebook Insights that this audience is 93% more likely to be engaged and 58% less likely to be married. With people who like investment banking, they unsurprisingly like money but also a cheeky nandos.
From these types of insights you can start to make assumptive statements about what these people are and what they are not. These are then put into an ideation framework looking at:
- Identity – Content that expresses who someone is better than they can express themselves e.g. don’t mess with gingers.
- Utility – Making something useful for the audience e.g. what does 2,000 calories look like?
- Social information – Reinforcing pre-existing ideas or seeking to break preconceived biases e.g. Londoners are the most miserable people in the UK.
In this methodology the content finds the audience rather than making the thing and then finding the audience.
Types of data
You can mine private data sources from platforms like Google Analytics, public data from government data sources and potential data from surveys and professional commentary. Consider mashing up different data sources to produce novel statistics and insights.
You can use public data to your advantage by making it easier to use. Ross’ team took a data dump of Ryanair flight information and made it into a tool so it was easier to use for less tech-savvy people and sold it into journalists.
Slice and serve data differently by taking existing data sets and making it relevant to a specific audience. For example, when gender pay differences data was released in the UK, Ross decided to take a subset of that and look at pay differences in the medical community and create content targeted at nurses.
Google have made searching for data sources really easy with Google Data Search. You can get information from Freedom of Information requests submitted to public bodies. By using these data sources you can get some repeatable and defensible data-led campaigns.
Christoph C. Cemper – 20 Free SEO Tools You Should be Using
Talk Summary
Christoph’s fast-fire talk gave us 20 free SEO tools we should be using as part of our regular work routine. Christoph’s one minute per tool talk meant that there was a guaranteed takeaway for everyone.
Key Takeaways
The obvious ones
Google Search Console – Search Console allows you to see manual actions, real rankings and CTRs, some link data (plus a bit more if you set up multiple properties and compile the sample reports).
Google Analytics – Some of Christoph’s clients still resist using Analytics because they don’t want Google to have their data. However, you can combine Analytics and Search Console data now, you can collect historical data and there are many paid tools that support the discovery of “not provided” data.
Google Tag Manager – Tag Manager allows you to add tracking scripts, page scripts and others without the need for a developer. Learning some regex might be helpful to get the most of out of Tag Manager.
Web-based SEO tools
Keywordtool.io – A comprehensive tool for keyword research, as it finds “hidden” keywords using autocomplete in any number of search engines including YouTube, Amazon and eBay.
Keywordtracker.io – A simple keyword tracking tool that allows you to track 50 keywords on 5 domains. Consider using SEOmonitor if you want something a bit fancier.
Free desktop crawlers
- Xenu – The longstanding mother of all desktop crawlers which can help you to detect broken links, rel canonical issues etc.
Screaming Frog – They are making moves to become more commercially-focused but the free version allows you to crawl up to 500 URLs, including the canonical versions of pages.
Sitebulb is another good desktop crawler with a lot of functionality and a free trial. Other crawlers are also available.
SEO plugins
Yoast SEO – A must-have plugin for every WordPress site and has been for 10+ years. Yoast includes great functionality and hints but redirect management costs extra now.
Chrome extensions
- JSON-LD Tester – This extension is a convenient way to test that the structured data on a page is valid.
- Open Multiple URLs – An extension which allows you to open a list of URLs and extracts a list of URLs from text. Word of warning: make sure your machine has lot of memory before using this.
- Structured data testing tool – This is a really useful Google tool that allows you to test a URL’s structured data to see if it is valid.
- Hreflang checker – This extension enables you to check the hreflang URLs on a page-by-page basis, which is useful for spot checks.
- JSS and CSS Beautifier – This provides a simple way to format CSS and JavaScript so that it is much easier to read.
- Linkclump – This gives you the ability to drag a selection box around links using your mouse to quickly open as new tabs, open in new window, save as bookmarks, or copy to clipboard.
- User-agent Switcher – This enables you to easily switch your browser so that it looks like it is another user-agent.
- Keywords Everywhere – Conveniently shows search volume, CPC, competition in a variety of places, including under Google searches.
SEO extensions
- Link Redirect Trace – Allows you to perform advanced, comprehensive analysis of links, redirects and rel canonicals.
- LRT Link Checker Extension – Check the links on a page to reveal the number of links on a page, find which ones are working, which ones are broken etc.
- LRT SEO toolbar – Provides SERP numbers, SERP sorting, domain metrics, page metrics, ranking keywords and referring links for results in search.
- LRT Power*Trust – This extension helps you assess the quality of a page or domain in no time.
- Spaghetti Code – Not a tool as such, but Christoph has a book about detangling life and work with programmer wisdom.
Prabhat Shah – Amazon SEO tools that I wouldn’t avoid
Talk Summary
Amazon SEO is becoming increasingly important to any sellers experiencing increased competition. To make this work easier, Prabhat introduced us to the Amazon SEO tools that are here to help. These tools can help you find high ranking keywords, spy on competitors and improve your organic ranking.
Key Takeaways
Google dominates conversations within SEO, but the spotlight is rarely on optimising the rankings for products in ecommerce search engines such as Amazon.
Prabhat revealed that Amazon’s conversion rate is 74% among Prime members, but only 12% for non-Prime members.
Tools to make life easier optimising when for Amazon
- Sonar – A tool developed in Germany that helps users find the keywords that people are searching for on Amazon. The tool looks at real search queries, identifying the most frequently used search terms and your competing products.
- Xsellco are an ecommerce toolkit which includes the Amazon Repricer feature. This allows you to automatically reprice on Amazon to ensure maximum sales for minimum effort.
- Amzscout is perfect for researching what sells well before you starts selling a particular product or line.
- Splitly allows you to A/B test various parts of your product listings, including titles, features, images etc.
- Magnet by Helium 10 is a group of SEO tools that helps you find popular keywords across seven Amazon domains. You can also find additional relevant and high volume keywords.
- Keywordtool.io was mentioned in Christoph’s talk but it is useful for Amazon as well as Google.
- AMZDataStudio allows you to find hidden search terms and see what keywords your products are indexed for.
- Jungle Scout is another Amazon research tool but it is particularly useful in helping you get bid estimation right.
Grant Simmons – The Batman SEO toolbelt to vanquish Google’s SERP
Talk Summary
Grant’s entertaining and practical talk took us on a walk through Gotham City’s underworld to uncover both the processes and tools you need to win worthy search visibility and traffic.
Key Takeaways
Like SEO tools, Batman’s utility belt has evolved over time. The utility belt was originally made out of sponges in the early Batman films and we need to make sure that as SEOs we upgrade the tools in our utility belts. What do we need in our belt as SEOs in order to vanquish the SERPs and win prime ranking spots?
Optimising for answer engines
Google is now an answer engine and SEOs are the question engineers. So, how do we get featured snippets?
Start with the low-hanging fruit by optimising pages that are already ranking to get shown as featured snippets. You can do this by finding the questions you’re ranking for in Search Console. This involves filtering queries down to prepositions, finding terms that can easily be reduced to a dictionary definition and long tail queries. Ahrefs and SEMrush can also help with this process.
Then grab 10-20 queries with search potential, ensuring they are aligned with your business, have a high enough search volume, the snippet has 3+ lines of text and the ranking target page on your site is appropriate. You then want to search for those terms and see where you’re ranking before conducting the search minus the domain in the featured snippet to see if your site then ranks.
At this point you’re going to want to compare and contrast the page in the featured snippet with the page ranking from your site. Look at optimising the title tag, image, lists and the numbers displayed in the title.
Finding questions you may not rank for
SEMrush’s Keyword Magic tool is great because you can hide/filter and build lists, select queries that already have snippets and find long tail queries with a focus on search volume.
Twin word ideas is a great tool for helping you to find good keywords faster. Their user intent filter is useful and their Pattern functionality can help identify prepositions and comparisons.
Keywordtool.io was mentioned in the previous two talks, but it is good for finding questions and prepositions and not just from Google.
Ahrefs is another one of Grant’s tool recommendations. They have evolved from being a link analysis tool and now have “Questions” and “Also ranks for” reports. Buzzsumo also gets a hat tip from Grant for it’s Reddit mining capability.
Finding feasible targets
Once you’ve got your list of 20 opportunites, you need to focus on the ones where it is feasible you can appear as the featured snippet. Building queries from queries can help with this. Grant has a formula for taking queries and transforming them into Google search result URLs, which you can then go on to crawl.
Crawling with JavaScript enabled will allow you to see the rendered version of the page and explore the featured snippet for opportunities.
Summary
Grant rounded off his talk by giving some key questions you need to ask to help you claim featured snippets:
- Can you provide a better answer than what is already displayed as a featured snippet?
- Is there a simple fix on your target page that is preventing it from being shown as the featured snippet? Markup, content formatting, summary addition, images, video, alt text, size (5×4) should all be taken into consideration.
- Are internal links providing strong signals that the target page is high value?
- Is your target page even being considered as an option?
The never ending recap
Well done if you’ve read this far down into the post, you’re a real SEO trooper! If you haven’t already, make sure to read the first part of our recap and our summary of the BrightonSEO keynote with Rand Fishkin is here.



