

BrightonSEO Event Recap – Part 3

It’s a credit to Kelvin Newman and Rough Agenda for not only attracting, but organising the best and brightest minds in Search at brightonSEO. We legitimately learned so much, that we had to split our notes into multiple recaps. In part 3, we cover talks by Alexis K Sanders, Fili Wiese, Tom Anthony, Stephen Kenwright, Emily Mace, and Tom Pool!
Rest assured it’s thorough, as I know many of you may have found it difficult to take robust notes, given the following temptations:
Afternoon working at #BrightonSEO is being powered by beers courtesy of @DeepCrawl. Thanks, guys! pic.twitter.com/iWJvNWNM6u
— Stacey MacNaught (@staceycav) April 27, 2018
Setting up the @DeepCrawl beer garden at #brightonSEO, & making sure the retro games and #SEO swag are all ready for you guys! pic.twitter.com/qMwSXMNnJQ
— DeepCrawl (@DeepCrawl) April 26, 2018
Alexis K Sanders: Advanced and Practical Structured Data with Schema.org
The Scoop
Structured Data is only becoming more and more important for SEOs to understand, and yet so many of us struggle when annotating information with Schema.org. This session gave us an overview what it can be used for from a basic to advanced sense, how to actually do it, and crucially; what happens if/when we mess it up!
The Knowledge Nuggets
First things first, were you unsure about any of the terms in this session?

I’m gonna go out on a limb here and assume some of you may have nodded yes…So I laid a brief glossary before diving deep into the learnings from this session 🙂
Structured Data: These are explicit clues that help search engines understand the context of a page. More specifically, it’s an organising system of pairing a word or a name with a value, that helps the categorisation and indexing of your content.
Schema.org: Most Structured Data uses Schema.org, which is a group of vocabulary tags (or microdata) that you can use to mark up pages (AKA add to your HTML) so that search engines can read, and ultimately rank your pages in SERPs better.
Markup: Putting this code on your site helps search engines return more informative results for users, a prime example would be googling that hot new restaurant on date night and finding its opening times and location in the rich snippet; pretty handy right?
Rich Snippet: When you’ve added structured data correctly to your site, Google can read it and present it in SERPs in what is called a rich/featured snippet/answer box, or what we call ranking for position zero.
JSON-LD: is based on a subset of JavaScript Programming Language, and is a linked data format that can organise and connect data on a page, is easier for machines to parse and is associated with creating a cleaner, better web.
Now that we’ve gone through the lingo, here’s what we learned!
KEY TAKEAWAYS
- Making mistakes with Schema is extremely easy and we all do it from time to time, use testing tools
- There’s a reason birds do it…nesting is good practice! Organise information in to layers, and add objects into objects
- Mind your commas with Syntax, and pay attention to those pesky red little Xs in SDTT
TL:DR
Understanding Structured Data & Examples:

Alexis mentioned SpeakableSpecification which indicates sections of a web page that are highlighted as particularly appropriate for text-to-speech conversion and is typically via xpath or cssSelector.
She also walked us through nesting or: organising information in layers; adding objects into objects. Which I basically took to mean Inception was inspired by SEO, until I saw this slide, and suddenly it all made sense!
What makes it so great?
Enhanced SERP results! Seeing stars/ratings on products can be a mahoosive incentive or detractor for customers to buy them, which is why CTR for rich results is higher. Alexis kindly compiled the list below of all the opportunities out there we could/should be chasing!
What’s the deal with Schema and Rankings, does the former yield positive results on the latter?
According to Gary Ilyes Google doesn’t use Schema as a quality ranking factor in terms of algorithms, but it is used in certain search features, hmm…
Alexis suspects Google Mini may pull web answers from featured snippets, as featured snippets appear when the big G has ‘high confidence’ in the usefulness of a response. For anyone who is/has tested that out, tell us what you find!
FYI @Merkle, @AlexisKSanders is killin it on stage at #brightonSEO, laying down the #structureddata law for #SEO best practices and making us laugh along the way!! pic.twitter.com/uWzstDpmQa
— DeepCrawl (@DeepCrawl) April 27, 2018
Schema Do’s
- Amongst the top occurring microdata for eCommerce with snippets are bread crumbs, ratings, and reviews, which you find using custom extractions in DeepCrawl
- Help yourself out by testing your Schema, for example using Max Prin’s SEO Tools for Markup, Google’s Structured Data Testing Tool, as well as their guidelines, rules and opportunities
- Remember, paying attention to expected type and how things are nested is important and don’t forget to add syntax!
Schema Don’ts
- Ignore required/allowed properties, or forget that Schema types/properties are case sensitive
- Violate policy by adding information that isn’t actually on the page
- When nesting: don’t attribute properties to the wrong item type
Ever missed a comma in your #structureddata? Chin up #SEO warrior, you’re not alone! This is a common pitfall says @AlexisKSanders at #brightonSEO ♀️ pic.twitter.com/i5CWOe3YQp
— DeepCrawl (@DeepCrawl) April 27, 2018
A bit about Alexis
Alexis is a keen traveller, has a brown belt in Judo, helps us avoid painful Search mistakes by sharing her own technical testing AND results on twitter, whilst being the Technical SEO Manager at Merkle. And makes time to share what she’s learned with the community at global conferences. NBD 🙂
Here are her slides:
Stephen Kenwright: How to Report on SEO in 2018
The Scoop
Stephen’s presentation was a beautiful playground of out-of-the-box tools and how to up your strategy game by making the most out of reporting on data.
The Knowledge Nuggets
KEY TAKEAWAYS
- Don’t rely on rankings alone; start reporting on predictive measures of success
- Improve your reporting by checking out these out-of-the-box tools
- Set up early warning alerts across the apps in your stack
- Like Lisa Myers, Stephen is also a fan of the book Grit!
TL:DR
Predictive v Performance
SEO metrics are split between predictive and performance, the latter is where we often spend most of our time. Stephen made the case for how important it is for us to not only asses ‘how are we doing’ (performance) but in fact, ‘what should we do next’ (predictive). This is in turn helps us assess value and analyse CTR.
For example if this is happening on your site:
You might want to look at what’s impacting your rankings:
Like bounce rate, time on site or page speed. Although page speed it isn’t directly a ranking factor, it does have long-term correlation with rankings.
Embrace La vie Low Touch
IT warnings and UX indicators can be automated; treat Yo Self!
Good idea… Setting up #SEO early warning systems from sources like crawls (@DeepCrawl in this example), pushing to @SlackHQ or #CRM like @Jira – @stekenwright at #BrightonSEO – alerts for things like deterioration in site health etc. pic.twitter.com/mh5bAyqvPl
— Mike Gracia (@MikeGracia_) April 27, 2018
Check out his killer examples:
- Creating custom email alerts in Google Analytics
- Pulling Searchmetrics & Moz into your Google Data Studio reports
- Monitoring what links are going live using Buzzsumo
- Using DeepCrawl to automate crawls and tasks/communications* and visualise SEO reports, all using your favourite tools thanks to our Zapier integration:
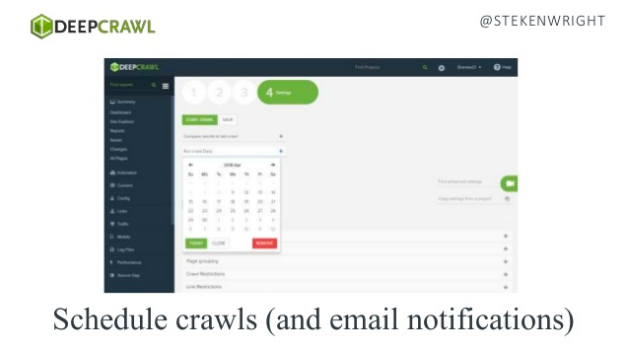
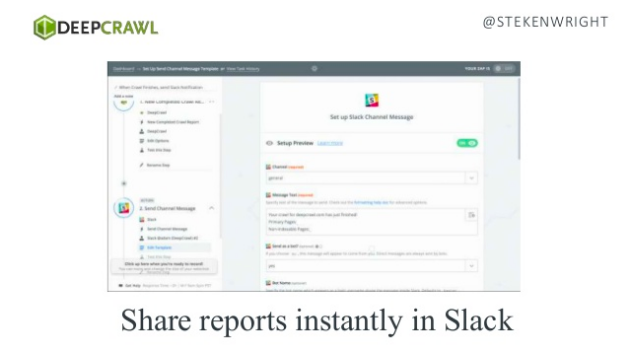
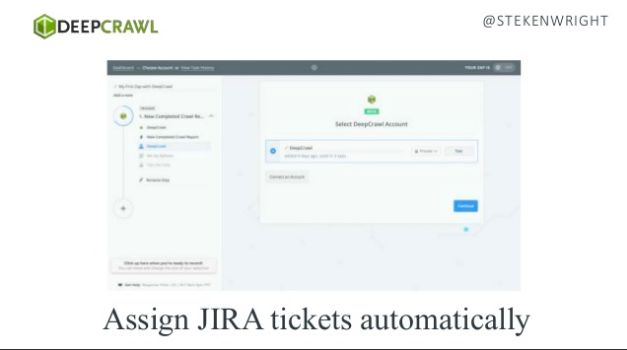
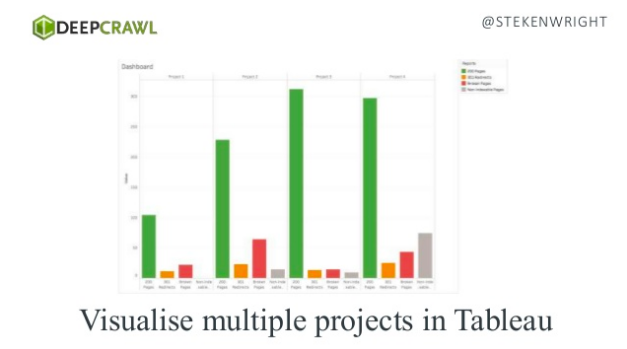
*Here’s how you connect DeepCrawl to your Slack or JIRA or even auto-populate columns in Google Sheets.
A bit about Stephen
Stephen Kenwright is the Director of Search at award-winning agency Branded3, and the founder of their kicka** event up north Search Leeds, which you can still grab tickies for here. Fun fact: he mentors students from the university he attended in his spare time.
Here are his slides:
Tom Anthony: Diving into HTTP/2 – a Guide for SEOs
The Scoop
Tom explained the changes that HTTP/2 brings, its positive impact on site speed, the changes in the way web pages are delivered and different approaches to deploying HTTP/2.
The Knowledge Nuggets
KEY TAKEAWAYS
- Imagine a HTTP request is a truck and it’s sent from your computer browser to a server, in order to collect a web page. TCP is the road, or the transport layer for the HTTP request. Trucks going outbound carry a HTTP request and trucks coming inbound carry a HTTP response
- HTTP lets people look into the trucks and take a cheeky look at all your secrets. Think about the HTTPs road as the same except we drive on it through a tunnel
- With HTTP/2 multiple trucks can drive on the same road at the same time, the content of the trucks is still the same but the road/traffic management system is new
- TA got really into the truck analogy, and it was AWESOME.
TL:DR
What even is HTTP/2 and…why should I care?
HTTP/2 is the 1st major revision to the HTTP protocol in 20 years, used by the World Wide Web. But the reason it’s got so many folks hot under the collar, is because it can provide big time benefits to site speed. This is especially important given that small requests/responses still take time, single pages are often made of many files, and mobile connections increase latency. It is a quick performance win, and CDNs can make deployment ‘easy’.
Plus, trucks make it even better!
This has to be my fav explanation of http2 to date. #trucks #BrightonSEO #DCNerds @TomAnthonySEO pic.twitter.com/ne828eZHWT
— Jenny Farnfield (@JenFarny) April 27, 2018
How we can benefit from speeding things up:
- Even though browsers can handle multiple requests, those connections take time to actually open
- Browsers typically open about 6 connections max, and this means that requests have to wait
Here’s how HTTP/2 can help:
- Multiplexing allows for multiple requests per connection
- ‘Server push’ predicts files needed on pages like images
- It stops blocking/queuing up nonsense, AKA waterfalls
- It’s better than other available hacks
- Googlebot doesn’t benefit but Google notices; so it does play into rankings

What changes/stays the same?
-
- The requests are still the same as is the format
- The response codes are unchanged (200, 301, 404s etc)
- HTTP/2 requires HTTPs (so once you’ve migrated to HTTPs you can move – not migrate – to HTTP/2)

A bit about Tom
Tom Anthony is the Head of R&D at Distilled, where he’s leading the team building the first publicly available platform for SEO split-testing. He’s built multiple tools to help practitioners with backlink analysis, social media metrics and beyond, which you can check out here.
Known as something of a genius in techSEO circles, he also recently won the Google Bug Bounty for a security exploit that influences search results using XML Sitemaps.
Here are his slides:
Fili Wiese: Optimising for Search Bots
The Scoop
Fili walked us through everything from website bot behaviour to mobile crawling and indexing to maximising your server logs!
The Knowledge Nuggets
KEY TAKEAWAYS
- The path Google takes to crawl your site isn’t always the same, think beyond the top down approach
- If you have access to server logs, use them well!
- Optimise your site for mobile indexing and help bots crawl your site efficiently, i.e. optimise your crawl budget!
- Google isn’t that good at crawling JS yet
- Tip: choose a preferred domain in Google Search Console
TL:DR
How does Google Crawl your Site?
The first time google crawls your site, they crawl top down but this isn’t their path each time they hit your site. Very quickly it becomes a random crawl with their URL scheduler. This is why checking your log files is very important, so you can actually see where and when the big G is hitting your site. Fili recommends using DeepCrawl, as seen below.
The first time #google crawls your site it’s top down, but their path very quickly becomes random with their URL scheduler. To understand your crawl budget, crawl your #logfiles with @DeepCrawl advises @filiwiese at #brightonSEO pic.twitter.com/Fs5HHY0NEi
— DeepCrawl (@DeepCrawl) April 27, 2018
Google Search Console
If you haven’t chosen preferred domain in GSC already, do it now.
Getting along with Google
Avoid conflicting signals towards Google like a soft 404, which DeepCrawl can help you find.
HTTPs
Fili recommends migrating over to HTTPs due to its many benefits, but warns you need to match up your protocols lest you have un-secure pages. That said, before you migrate your site you should improve your SEO signals as this will help massively overall.
Mobile-first
Fili walked us through the early stages of mobile first and Google’s mobile user agent, and how HTML and AMP involves having a second code base. But, did you know you can go canonical AMP? Whatever you decide to do in this area, make sure you’re serving content well, as content parity is really important for mobile.
In short, we should have been optimised for mobile already!
A bit about Fili
Fili Wiese is an ex-Googler and SEO Expert at Search Brothers, a Consultancy he founded with Kaspar Szymanski. Fili spends a lot of time giving back to the Search community, by speaking at global events, and giving in-depth technical trainings (which he also does at brightonSEO).
On a personal note, we’re very proud to count Fili as one of the founding members of the DeepCrawl Customer Advisory Board.
Feel free to reach out to Fili for his slides.
Emily Mace: Diagnosing Issues with Hreflang Tags in sitemaps and on page
The Scoop
Emily walked us through the do’s and don’ts of tagging hreflang in your sitemaps.
The Knowledge Nuggets
KEY TAKEAWAYS
- Make sure you’re serving the right content to the right person, in the right place
- Always check your country codes, don’t assume they’re the same as the language codes!
- Use tools to check Hreflang tags and canonicalisation
TL:DR
Internationalising your Content
Emily advises targeting content by country so people get the right currency/content for where they are and their language. Country codes and their language codes aren’t always the same, as is the case for Japan the country and Japanese the language. Moral of the story? Don’t make up the codes! Make sure you’re using the right ones! Check!
Working on your #internationalSEO game? Remember to only target one language and country per URL, great advice @IAmTheLaserHawk! #brightonSEO pic.twitter.com/elhSf4048Z
— DeepCrawl (@DeepCrawl) April 27, 2018
Thinking of cheating? Think again:
- Each individual URL can only be targeted to one language and country, multiple targets for the same page LOOK FAKE
- Don’t IP serve – Google lives in america big mistake!
- There’s no silver bullet
- Make sure your code is configured correctly i.e. for language/country codes
- Some hreflang tag errors Google corrects for you
- Use tools like ahrefs for using ranking information to see which site is competing against which, to check domains in each country and find issues
- Look for traffic from the wrong country in analytics
Emily’s Top Tips:
- Spot check code to see if it contains a self referencing tag, does the link agree with the canonical tag? These are important things to find out as well as if the Hreflang tags are even in the right place, are they in the sitemaps or in one or all of the sitemaps for example.
- Crawl your sitemaps and check your canonicals and language tags and add in data from Search Console
- See if all pages have a Hreflang tag, find out what may be missing, different or incorrect
A bit about Emily
Emily Mace is the Head of International SEO at Oban International and can be found speaking and training at search marketing events worldwide.
Here are her slides:
Tom Pool: Command Line Hacks for SEO
The Scoop
Tom explored some seriously funky things that we can get command lines to do for us, from setting off crawls to making sense of large server log data sets!
The Knowledge Nuggets
KEY TAKEAWAYS
- You can use command lines: to schedule crawls
- Perform keyword gap analysis
- Extracting specific data points from server log files
- There’s a command line called CAT.
TL:DR
What’s a Command Line Hack?
It’s a basic interface between you and the computer.
What Command Line Hacks does Tom recommend for Mac OS & How do you Use Them?

CURL: A tool to transfer data from or to a server, you can use this to check response codes, HTTP headers or follow redirects!
SORT: A tool to ‘sort’ things from A-Z, by volume, navigate a folder to make sure all the data (like keywords) is there.
HEAD/TAIL: Head views the first 10 rows and Tail views the last 10 rows, you can even use this to sort the top 100 and save those to a file.

CAT or concatenate: Is used to display, combine and create files, like the top organic keywords.
SED or stream editor: Allows you to filter and transform text, like adding text to rows.
AWK: Is a state of mind, or in this case a programming language used to process text. You could use it to extract the following from a large data set.
Combining CAT and AWK is a great shout for Log file analysis. Tom had a client that gave years worth of daily log file data (say what!?), and using those commands he populated a folder with every instance of 404 pages found in the data set and modified the command for Bingbot versus Googlebot, as well as CSS resources, JPEGs and other image files*.
I caught up with Tom and asked him a few questions after brightonSEO, and here’s what I learned…
Out of all the tips ‘n tricks you shared in your session, what is the ONE thing you hope folks try out & why?
The one thing that I hope folks try out would be ‘awk’. The usage that I highlighted was a small application, and there are so many potential applications of this one command.
Which command line hack do you use the most and what do you use it for?
The command that I personally use the most would probably be ‘cat’ – For combining log files, keyword data and other third party exports, nothing is quicker!
*If you want to find ALT image tags, or other specific information like ratings or product reviews, you can use custom extractions in DeepCrawl. We have preset functions, but you/we can always write unique RegEx too 😉
A bit about Tom
Tom Pool is the Technical SEO Manager at Blue Array, where he can be found doing keyword analysis, website auditing, and gaming…in his spare time 😉
Here are his slides:
l
Weren’t able to make the keynote with Aleyda Solis and John Mueller, or want to revisit it? Stay tuned for our next recap!



