

Scheduled crawls are a great way to keep a pulse on wanted or unwanted changes that occur on your website.
However, a risk with this “set it and forget it mentality” is that you’re crawling a website with the same configuration each time. This means you are only analyzing your website from one perspective, which can leave it vulnerable to major issues evident to a different user agent or your users!
To uncover problems, we recommend completing parity audits of your website. These audits take back-to-back crawls and compare the differences to find issues that aren’t caught in most ongoing crawls. At DeepCrawl (now Lumar), our team uses two types of parity audits regularly: Desktop/Mobile Parity and JavaScript Parity.
Desktop/Mobile User-Agent Parity Crawl
The Desktop/Mobile parity audit gained popularity when mobile-first indexing was announced, with a goal of finding issues on websites that might prevent it from performing well when switched to a mobile-first approach.
So if your website has already switched over to mobile-first indexing, why should you care?
Just because you’ve switched to the mobile-first index, doesn’t mean that the desktop user-agent isn’t crawling your website.
Google still crawls with the desktop version of their crawler, and has been very clear that the content on the desktop and mobile versions of the website should match. If they don’t, that’s a problem.
One thing that tends to cause confusion when discussing the mobile-first index is the relationship between responsive websites and user agents.
Some websites change the invisible elements and visible content of the page based on screen size. This can be a problem (see link above) but is not what we’re looking at with this parity audit. What we’re attempting to uncover is not how content changes based on screen size, but instead how content changes based on user-agent.
How To Complete a User-Agent Parity Crawl
Now that we’ve established it’s important to know the differences between how Googlebot and Googlebot Smartphone see your website, how do you actually go about comparing?
To begin with, you’ll need two crawls that are configured the same way — except for the user agent. At DeepCrawl, we set up a new project for the audit and give it a descriptive name that incorporates the order of the crawls that will be run (DeepCrawl Desktop/Mobile Parity Crawl).

We usually crawl the website with the desktop user agent first, but it really doesn’t matter. Once the desktop crawl finalizes, we enter the project settings, change the user agent to Googlebot Smartphone, and crawl again. Once the second crawl has finalized, it’s time to analyze the data.
The next step is to look at the same reports in both crawls side by side and identify the differences. One of my favorite views in the DeepCrawl app is the Changes report because it lays out changes between crawls in a way that makes spotting differences easy.
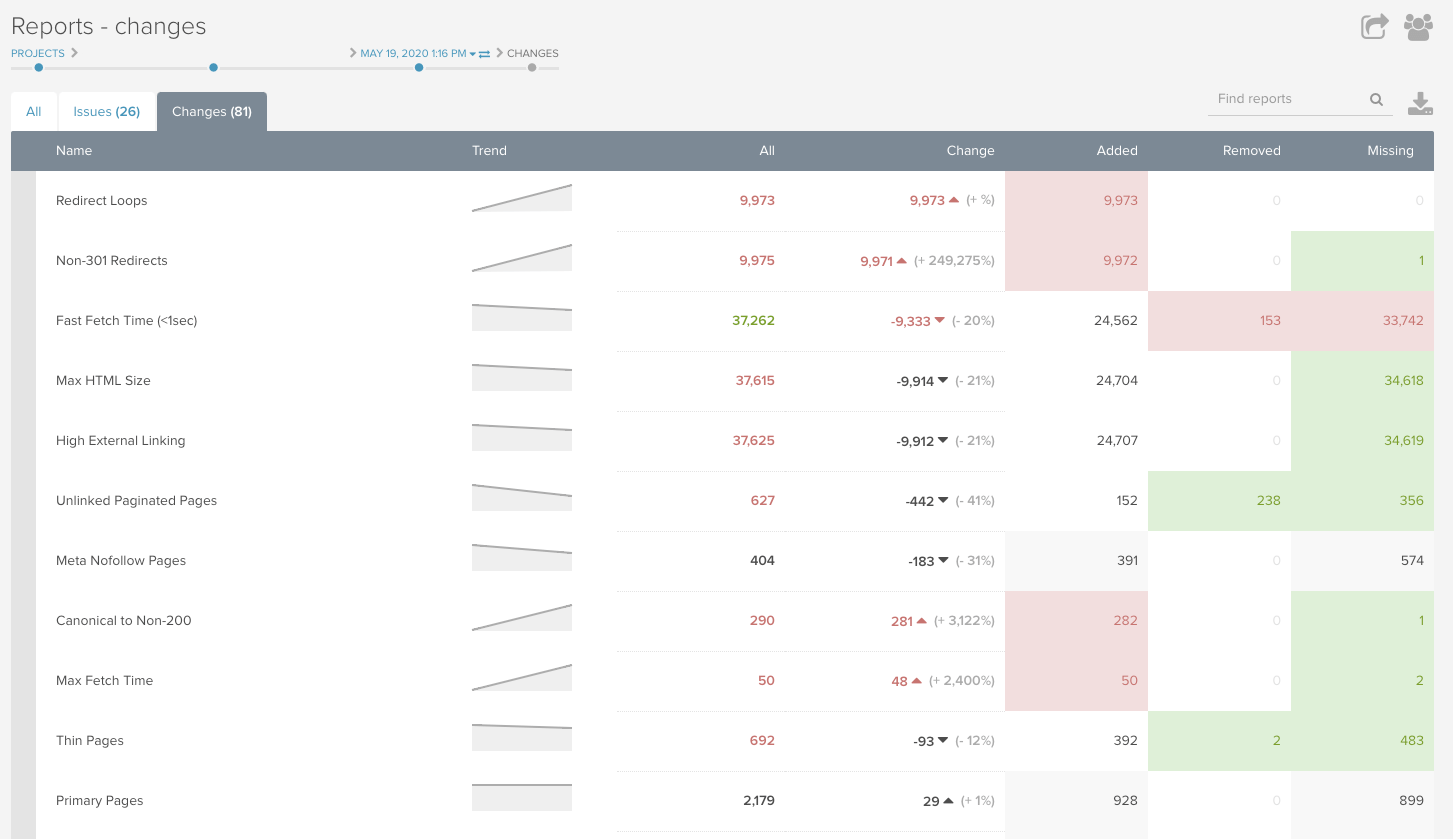
Where you go from here very much depends on what has changed. Let’s look at some examples.
What We’ve Found From Desktop/Mobile Parity Audits
We have identified and fixed all kinds of shenanigans with Desktop/Mobile Parity audits. Here are a few places you may want to check when analyzing your crawls.
Word Count/Header Tag Changes
Many times we see a difference in word count between the desktop and mobile versions of the website. It makes sense — mobile has a smaller screen size, so some content may get removed. But it’s important to identify what content is being removed between versions. If it’s not available to the mobile user-agent, then that content isn’t being factored into ranking. Same thing with header tags.
Fetch Time and Custom Extractions
Page speed matters — especially for mobile users. The DeepCrawl app has buckets for fast, medium, and slow fetch times, which we use to look for differences in parity crawls. For more specific metrics, we can configure the advanced settings prior to crawling to pull Core Web Vitals as custom extractions.
Our team also frequently uses custom JavaScript and custom extractions to pull schema and specific on-page content.
For example, you could use custom extractions to pull the number of products on category pages to compare between desktop and mobile crawls. Or product pages that are “out of stock” but indexable. Or pages that have the word “cats” in the H1!
With custom extractions and custom JavaScript, the comparison opportunities are endless.
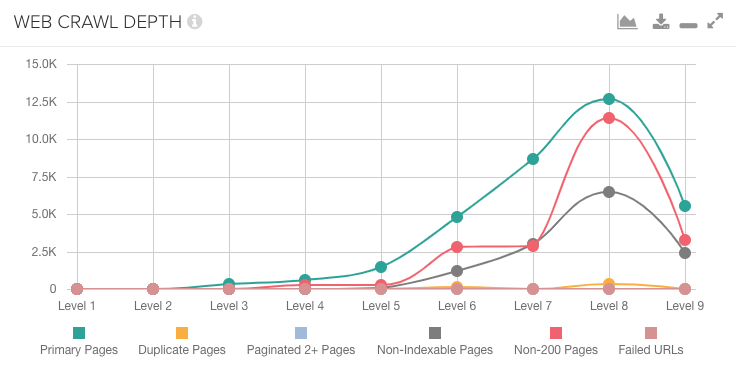
Web Crawl Depth Changes
Many times, desktop and mobile user agents will encounter vastly different page templates, including differing links in the navigation and footer.
What we find is that pages that are only a few clicks from the homepage on desktop are many more clicks away from the homepage on mobile — or the opposite.
Using the “web crawl depth” chart in the dashboard of DeepCrawl, we can see how the linking structure changed between the two crawls.
In this example, the largest percentage of primary pages is at level eight for the mobile crawl, but level five for the desktop crawl. This is a red flag that there’s a linking issue.
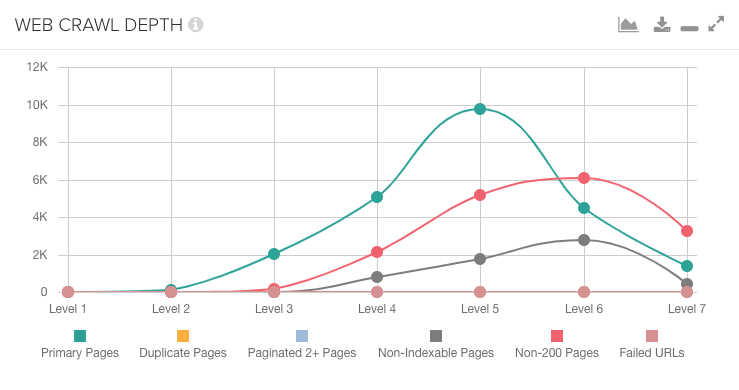
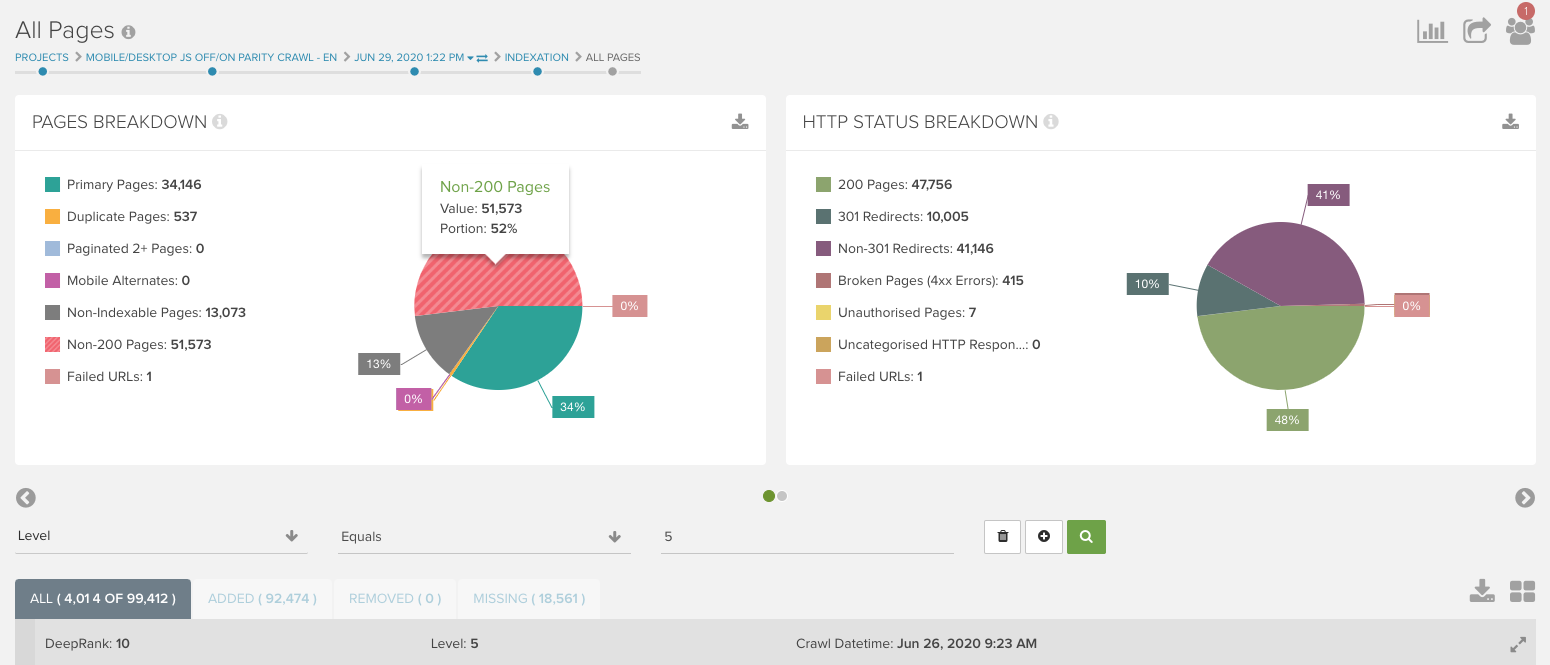
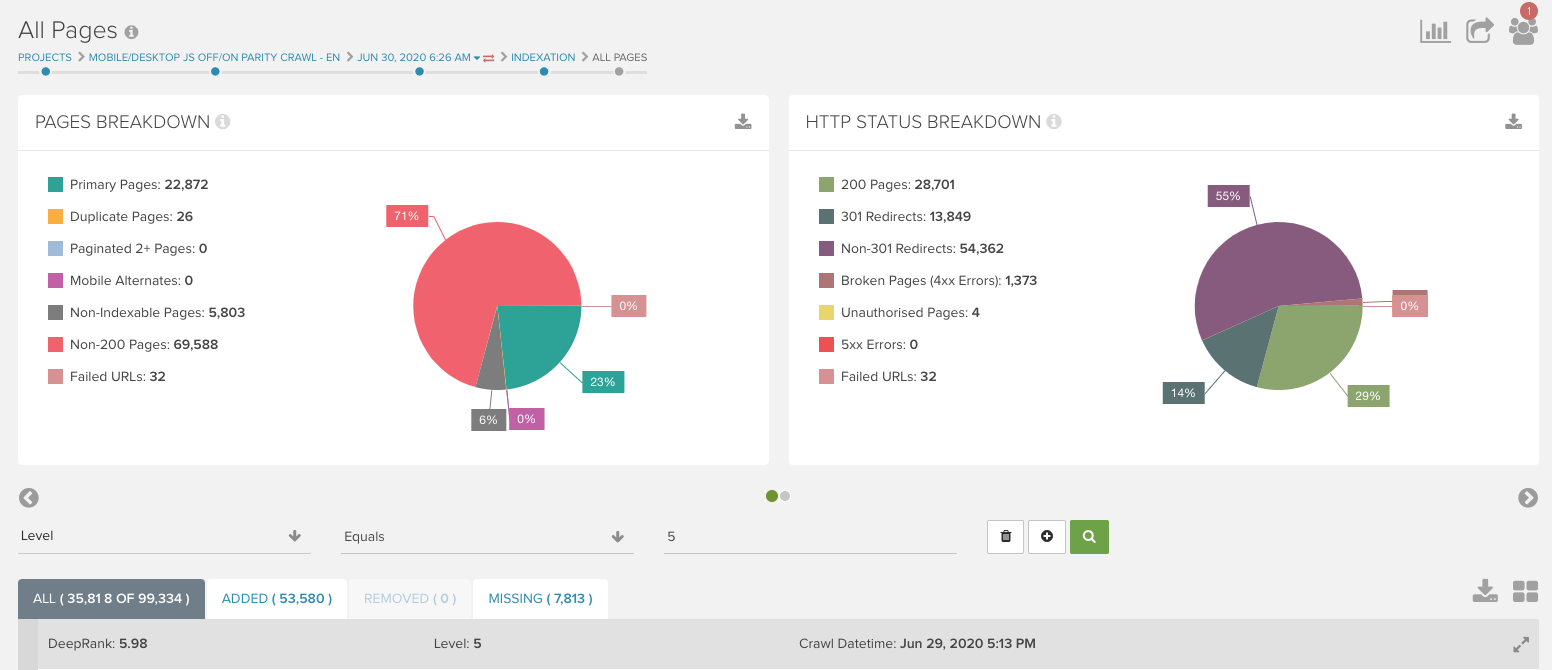
If you realize there’s a major difference in web crawl depth, you’ll want to check in the All Pages report for each crawl and apply a Level filter to identify what types of pages changed.
If the project has Segmentation for URL groupings, you could see which segments are changing levels between the two crawls. From there, you can narrow down exactly what changed and determine the fix.
JavaScript Parity Audit
Do you know how JavaScript impacts your website?
Several years ago, SEO advice centered about avoiding JavaScript because search engines couldn’t render it, but that’s no longer the case.
JavaScript is essential to the websites of most major brands and Google can now render it. Still, there are plenty of things that could go wrong. Here are three of the reasons you should run a JavaScript Parity Audit on your website.
Reason 1: Pre-Rendered HTML Still Matters
We encounter a lot of websites that use JavaScript to load elements like canonicals, hreflang, internal links, and noindex tags.
Since Google can now render JavaScript, many SEOs wonder why it matters if elements load in the pre-rendered HTML. Why is this a problem when Google and other search engines are able to render JavaScript?
For one, render budget is a thing! Just because Google can crawl and render content, doesn’t mean it always will.
If your page is crawled and not rendered with JavaScript, it’s important that the canonical, hreflang, links, and noindex tags are the same as the rendered version of the page. The same goes for all other elements on the page that you want to be indexed — if it can’t be seen without JavaScript, you can’t always expect search engines to see it.
Reason 2: Accessibility
Many accessibility devices (like screen readers) don’t render JavaScript, so anyone depending on these devices will be unable to access content that is dependent on JavaScript.
In addition to simply wanting these users to be able to access your content, there have been many more lawsuits in recent years centered on websites that are not compliant.
Avoid alienating users and lawsuits by ensuring content is visible both before and after JavaScript rendering.
Reason 3: Antiquated JavaScript may be doing things you don’t expect. Or nothing at all.
JavaScript has been an essential part of websites for quite some time.
In fact, the JavaScript on your website has been around long enough that there may be some ancient code hiding out on your website.
At best, this old code is just slowing your page down (if it’s on the page, it’s using resources). At worst, this code may be interfering with your page in unexpected ways. A deep dive into the JavaScript On/Off differences will often highlight some of these relics from the past, allowing you to remove the outdated code.
How To Complete a JavaScript Parity Crawl
Sure, you can manually check pages of your website pre- and post-render to figure out exactly what’s going on, but a JavaScript Parity Crawl will help you identify which areas of the website need that extra analysis.
Setting up a JavaScript Parity Crawl is pretty straightforward: run a crawl with JavaScript enabled and then run it again with JavaScript disabled.
In DeepCrawl, we set up a new project with a naming convention that reflects the order of the crawl (example: JS On/Off Parity Crawl). The only change between crawls is selecting the checkbox in step one.

Once both crawls have completed, you can begin analysis. Within the DeepCrawl platform, the change report is a helpful place to start to look for trends.
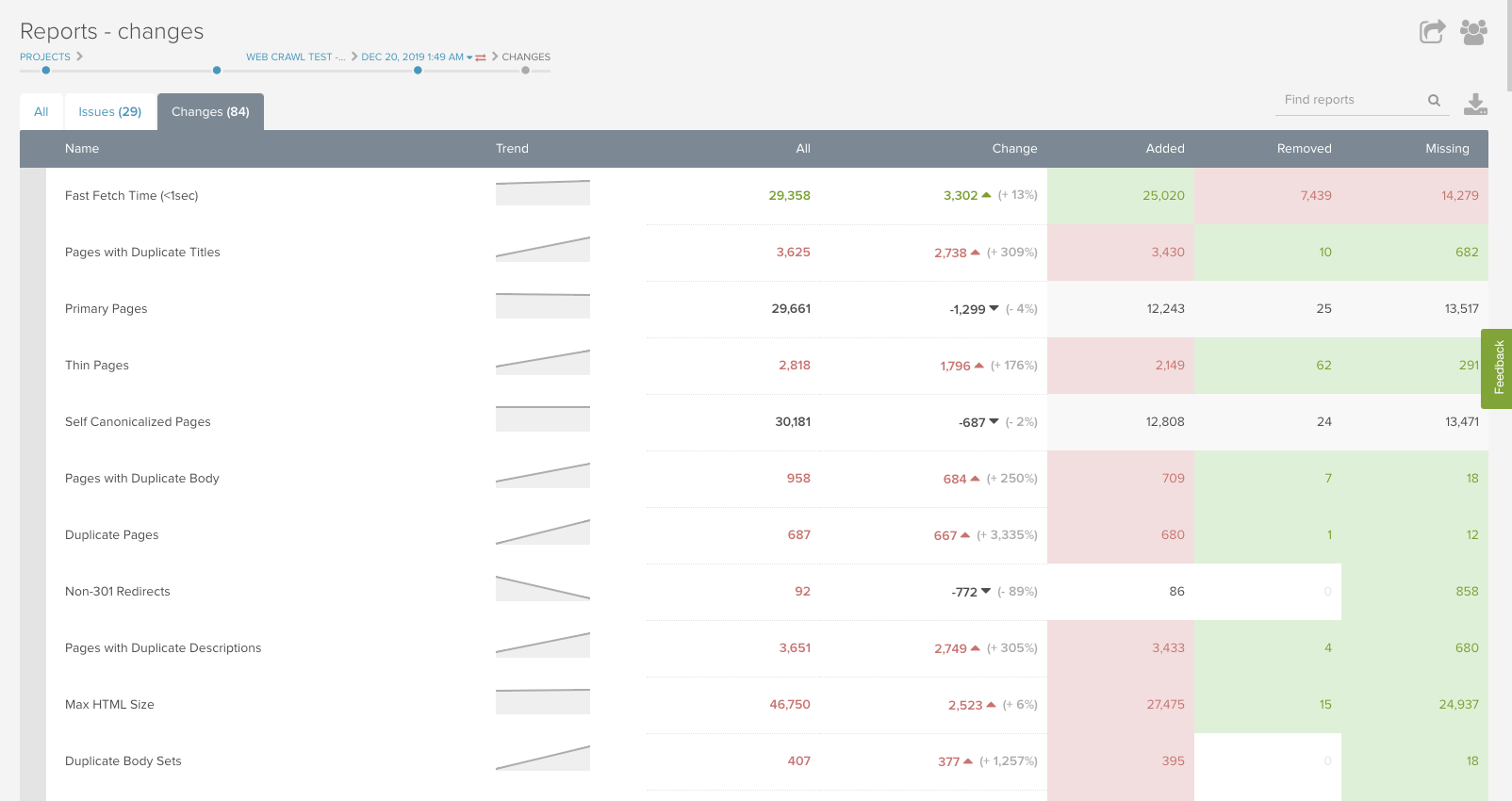
What We’ve Found From JavaScript Parity Audits
Our team uses JavaScript Parity Audits frequently to analyze websites. In addition to the changes outlined above in the desktop/mobile parity audit, here are a few changes we recommend checking in a JavaScript parity audit.
Changing Canonicals
One of the most common and alarming finds in JavaScript parity audits are canonical changes. Changes to self-referring canonicals, missing canonicals, and canonicalized pages should be investigated.
Within the DeepCrawl app, you can see crawl trends in the “reports” section or by entering specific canonical reports.
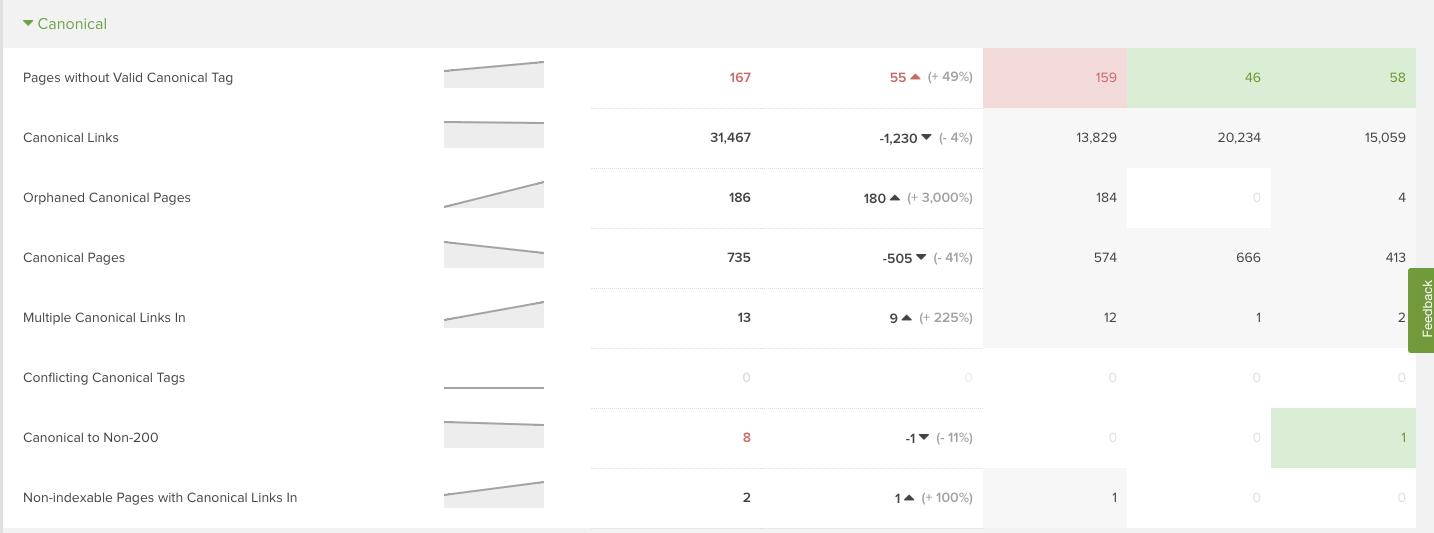
In one case, a major shoe brand had subcategory pages that were canonicalized to category pages in the JavaScript on crawl, but when those subcategory pages were accessed with JavaScript off, they 301 redirected to the category pages from the JavaScript on crawl.
This meant that when JavaScript was disabled, users and crawlers could only see the main category pages. Yikes!
In another case, an eCommerce site had canonicals that only existed post-render on some templates, so without JavaScript rendering, there were missing canonicals.
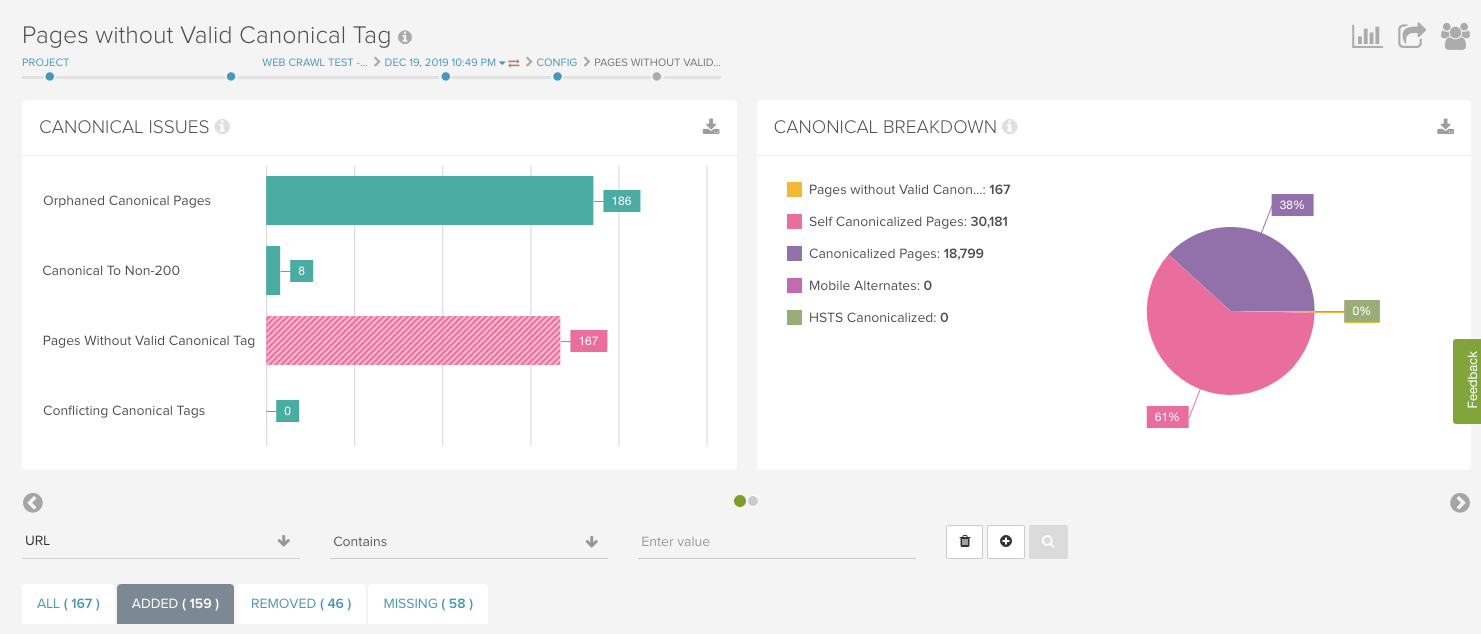
After identifying an issue in the “reports” page, we used the “added” tab within the “Pages Without a Valid Canonical Tag” to identify which pages lost canonical tags when crawled without JavaScript rendering.
Missing Noindex Tags
Another common issue is noindex tags that are dependent upon JavaScript to function. Or, noindex tags on the pre-rendered pages with JavaScript that removes them. These issues are simple to identify in the “Noindex Pages” report.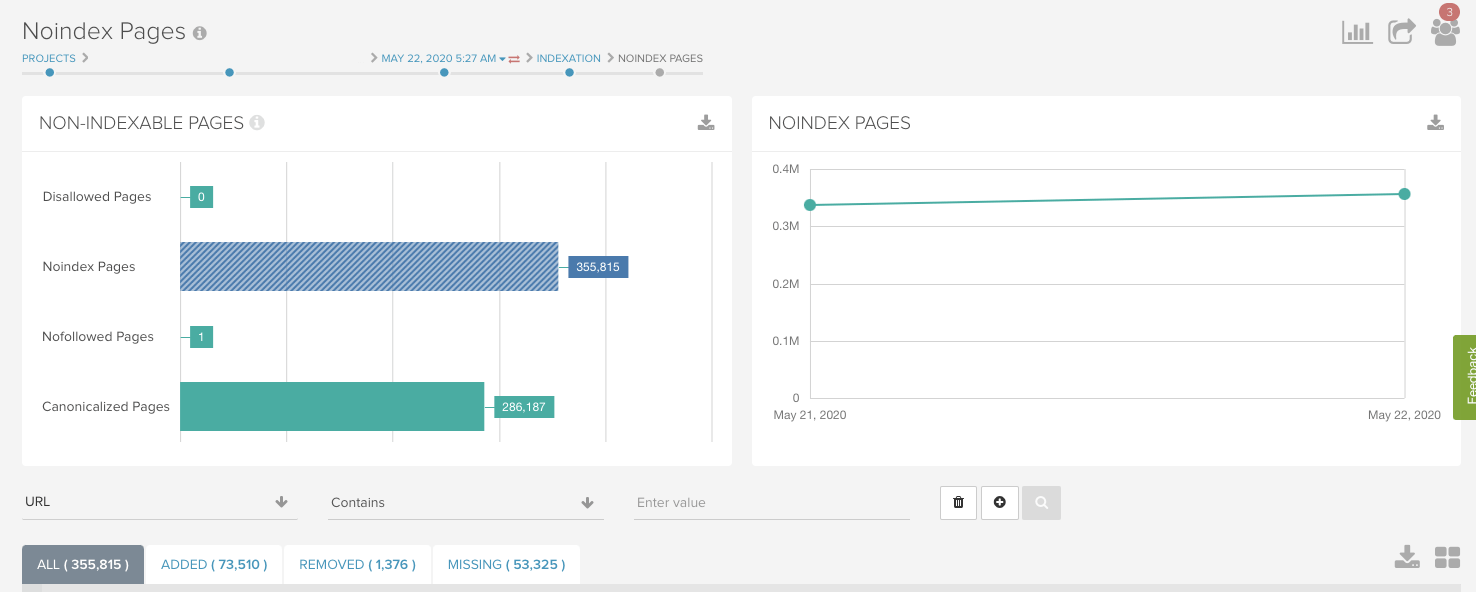
The same shoe brand from the previous example had noindex tags that were dependent on JavaScript rendering. So, with JavaScript rendering, the pages had a noindex tag, but without JavaScript, the pages were indexable.
Content changes
Content changes such as differing word count, headers, titles, and meta descriptions are also common finds in JavaScript Parity Crawls. We recommend checking the missing content reports: Missing Titles, Missing Descriptions, Empty Pages.
Next, check the duplicates.
Many times with JavaScript rendering off, you’ll see a spike in duplicate titles and descriptions because there’s a “fall back” for an entire template type. For example, all the product pages may have unique page titles with JavaScript rendering but may fall back to the brand name only without.
This would then be flagged as a duplicate title in DeepCrawl.
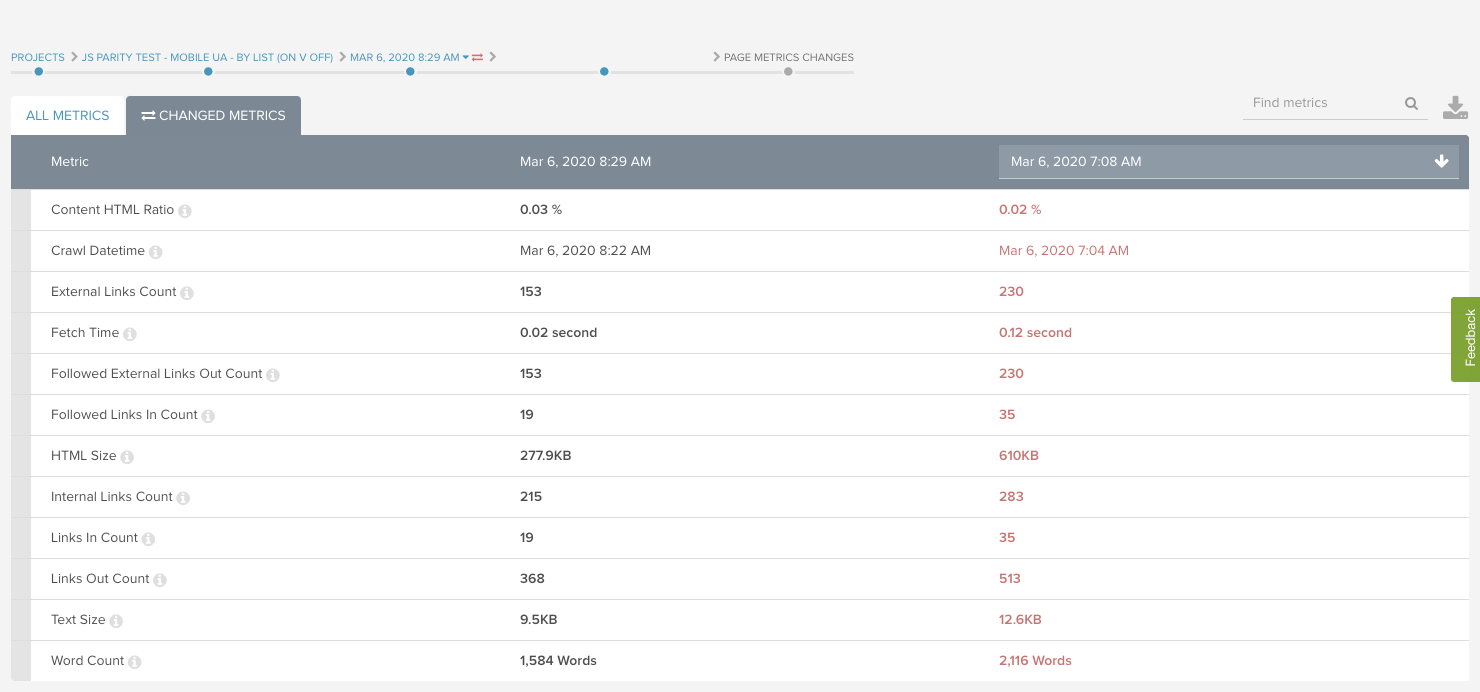
Word count changes are a little more difficult to analyze. One technique is to take a sample of pages from each template and use the page change feature to compare the individual URLs between crawls. To access this feature, click into an individual URL report and select “See All Changes.”
In this example, a forum website had major changes in the words on page when JavaScript wasn’t rendered. Without JavaScript, the page was missing 25% of words on the page!
If there are similar changes in word count across pages from the same template, you can analyze additional pages from that template in the browser. Chrome Extensions like Web Developer and View Rendered Source are my go-to’s for this detailed analysis.
Linking Changes
Internal and external link counts can also change dramatically before and after rendering. While analyzing for word count (as outlined above), also check for linking changes.
In the example from the forum website, notice that there are about 29% more links out with JavaScript than without. This says to me that some links are likely not following best practices for crawlable links.
Iframe in the <head>
A weird case we’ve encountered with JavaScript parity crawls goes like this:
- We crawl the website with JavaScript off and there’s a canonical tag, title, and meta description.
- We crawl the website with JavaScript on and the canonical, title, and meta description are labeled as missing.
- But then, when we do a manual review of the page with JavaScript enabled or disabled the canonical, title, and meta description all exist.
So what is happening?
The problem is that there’s an iframe in the <head>.
Iframes are seen by Google as <body> elements, so when they are found in the <head>, Google assumes the <head> is over and interprets everything after that point as the <body>.
Since canonicals, titles, and meta descriptions all belong in the <head>, they don’t function correctly in the <body>. DeepCrawl interprets iframes in the <head> similarly, so any <head> items after the iframe are ignored.
If you’re fascinated by this and want more information, check out this webinar with Martin Splitt from 2019.
The solution to this problem is to remove iframes from the <head>. For crawling purposes, DeepCrawl also has a JavaScript snippet that you can use in the app to rearrange all items in the <head> to come before the iframe.
This, of course, doesn’t solve the technical problem but will allow you to get a good crawl to analyze other issues with the data in the meantime.
Additional Parity Analysis
Detailed Parity Crawls
When we crawl large websites (greater than 50,000 URLs), a few additional crawls may be necessary for a complete audit.
Though we are able to identify some high-impact issues in initial crawls, there are sometimes additional anomalies that are difficult to investigate with such a large amount of data.
In these cases, we’ll take a subset of URLs, set up a new project, and run additional parity crawls to pin down exactly what’s going on. Some subsets of URLs may include page types (category/product/blog), pages missing from one parity crawl, or a sample of pages from all the duplicate reports.
For example, when crawling the shoe brand’s website, there were strange things happening on some category pages and custom pages in the JavaScript Parity crawl. We took 400 of these URLs, created a new project, and completed four additional crawls: Mobile JavaScript Off, Desktop JavaScript Off, Mobile JavaScript On, Desktop JavaScript On.
Once the crawls are complete, the process of analysis is the same, but the scale is much smaller so it’s easier to identify the cause of the changes.
In the case of the shoe brand, I was able to identify a few issues that weren’t immediately clear to be in the JavaScript Parity Crawl:
- The iframe issue mentioned above was identified as the cause of some parity differences. The iframe was only found in the <head> in crawls with JavaScript rendering, something this smaller crawl made apparent.
- One important page was canonicalized to the non-secure version. This was difficult to find in the large crawl because a 1 page change in a 700,000 page crawl didn’t stand out.
- Some category pages had faceted navigation links that changed based on JavaScript rendering. This only applied to a small subset of category pages, which were easier to identify with a smaller crawl.
Depending on the website size and the type of issues, you may not need additional parity crawls, but it’s great in cases where something seems off but it’s hard to identify exactly what.
Excel/Python Parity Magic
In cases where you need to identify differences in content and links for many URLs, you may want to export a filtered list of URLs and complete additional change analysis in Excel.
For this, you’d download the same report or segment for both crawls (Desktop/Mobile or Javascript On/Off), add them to an Excel spreadsheet, and use a VLOOKUP on the URL for each metric.
Similar to the “See All Changes” report, you will be able to see differences in the crawls, with the added benefit of comparing many URLs at once. For even larger crawls, you could do the same analysis using Python. In most cases though, we’re able to identify trends in the DeepCrawl app without having to export data for additional analysis.
Time to Audit
The great news is that Desktop/Mobile Parity Audits and JavaScript Parity Audits are easy to set up and complete. In fact, if you analyze your web crawls for changes, you’re already familiar with the technique! Simply run some parity crawls in a new project and set aside a few hours for analysis.
While you won’t always find life-changing differences, you will sleep better knowing that differences in how search engines are accessing your pages aren’t keeping you from success in search results.



