

Following on from our beginner’s guide to implementing noindex, disallow and nofollow directives, we’re delving a bit further into the murky waters of noindexing. We’ll cover using noindex for thin pages, duplicate content and managing Sitelinks; error recovery; combining with disallow; PageRank and Sitemaps.

Noindexing can be a daunting process – especially when deciding whether to noindex large portions of your site – and recovering from an error is overwhelming. So let’s get started.
When to use noindex
You should noindex low-value content, or content that you don’t want users to find from a search result. A noindex leaves a page open for your audience to use on-site, but means your site’s authority won’t be affected by its content and users won’t be able to find the page through a search query.
Key noindexing situations can include (but are not limited to):
- Low-quality or ‘thin’ pages that you don’t want to delete.
- Pages created for other marketing purposes (eg. online versions of email marketing, landing pages for social media) that you don’t want search users to land on.
- Any page that you want to hide from the general public: for example, a page that you only want people with a specific link to be able to find.
- User-generated content like forum pages (see below for more detail).
Noindex for forums and other thin content
Make thin content non-indexable by noindexing and/or canonicalizing where appropriate.
In a Webmaster Hangout in April 2015 (18m 35secs in), John Mueller gave some advice for deciding which parts of your site might be considered ‘thin’, particularly when considering forums.
Here are the highlights from what John said:
- Noindex untrusted forum content. This could include posts by users who haven’t been in the forum before, threads that don’t have any answers and threads that don’t have any authoritative answers. You can noindex these by default.
- When deciding which pages could be considered thin and should therefore be noindexed, identify ‘which pages are high quality, which pages are lower quality, so that the pages that do get indexed are really the high quality ones’.
Should noindex be used for duplicate content?
In most situations, a canonical tag should be used instead of a noindex to deal with duplicate content. Canonicalizing content will consolidate ranking and social signals to the canonical page, as well as favouring the canonical page in search results, making it the best option for managing duplicate pages. Noindexing the canonicalized pages just removes them from the index, without consolidating all the signals that will make the main page stronger.
The only situation where noindex would be a useful option for duplicate content would be if you can’t use canonical tags: for example, if the content on the canonical page is different to the content on the canonicalized page(s).
Noindex for demoted or incorrect sitelinks
Sitelinks that don’t disappear after being demoted can be removed by adding a noindex: Google’s John Mueller discussed this in a recent Google Webmaster Hangout.
Recovering from page(s) noindexed in error
As a noindex tag is so easy to add and remove, it’s quite possible for it to be added to the wrong pages or for other members of the team to misunderstand its effect/purpose.
Obviously the first and most important step in recovering from a noindex error is to remove the noindex. After this, you should:
- Resubmit your Sitemap to Google via Search Console.
- Manually submit selected pages using the ‘Submit to Index’ feature.
- Add the noindexed URLs to the RSS feed, and submit this in Google Search Console as a Sitemap, ideally with PubSubHubbub. This should help speed up the reindexing of the content.
- Consider running additional marketing via email/social channels/guest posts to try to supplement the traffic impact while the site is out of the index.
Future-proofing
Future-proof the site against accidental noindexing by ensuring that all developers/site admins who have access to the back-end of the site understand the impact of a noindex.
You might also consider investing in additional marketing channels to limit the impact of search performance fluctuations in the future.
Spot noindex errors
Even if this nightmare hasn’t happened to you yet, it’s a good idea to use the tools you have available to check for noindex problems regularly, especially on high-traffic pages. Remember that a noindex error can take anything up to a month or longer to reflect in search results, depending on how regularly Google crawls your site.
Look out for sharp declines in organic traffic in Google Analytics and sharp changes in Search Analytics/Indexed Pages data in Search Console.
Combining with disallow
One of the disadvantages of using a meta noindex is that if you want to also disallow the page, the disallow directive in the robots.txt will prevent the page being crawled, therefore search engines cannot see the noindex directive.
While the meta noindex is the most common noindex method (and the method that Google supports), there is another noindex method available that gets around the issue above. This second method involves adding a noindex tag to your robots.txt file in a similar way to adding a disallow directive. This means it’s possible to combine a robots.txt noindex with a disallow directive to stop the page(s) appearing in search results at all.
However, Google advise against using this method: John Mueller has stated that ‘you shouldn’t rely on it’.
Do noindexed pages accumulate PageRank?
In 2012 Google stated that they do crawl noindexed pages (they have to in order to see the noindex meta tag), process the content and follow the links, but they just don’t show the page in the index. In 2007 Matt Cutts confirmed that noindexed pages can pass PageRank.
Sitemaps
Sitemaps should only include URLs that you want to be seen by Google and included in the search results, so don’t include any pages with a noindex tag in a Sitemap.
How much time/effort should you spend noindexing individual pages?
The bottom line for noindexing pages: if the content is useful for a reader, then leave it indexed. Generally, you should only noindex where the page has very little SEO value (ie. it is deemed thin by Google’s standards or is just low-value content) or where you don’t want the page to be accessed via search results.
DeepCrawl and noindex: useful reports
Allow DeepCrawl full access to your noindexed URLs in a Universal Crawl to get a complete view of your set-up. Ensure the user-agent is set as Googlebot in Advanced Settings to reflect how Googlebot will react:
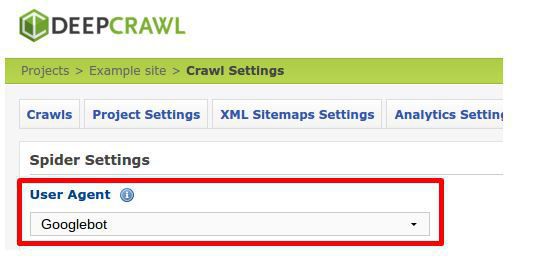
Scheduling regular crawls and setting each one to be compared to the last will highlight sharp increases in the number of noindexed pages; this could indicate a noindex error.
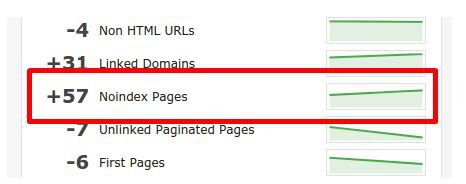
You can analyze individual URLs that are currently noindexed by going to Indexation > Non-Indexable Pages > Noindex Pages. You’ll see a list of URLs that have been noindexed, plus where they have been noindexed: robots, meta or header:

If you’d rather not see noindexed pages in your report, you can exclude them from the crawl in Advanced Settings.



