

While Google and other search engines are getting better at finding pages on their own, Sitemaps can help by giving them extra information about your pages and help them to crawl more efficiently.
In this post we’ll cover general Sitemap rules and advanced configuration. For a full guide to Sitemap implementation, please see Google Webmaster support.
Who needs Sitemaps?
Large sites
If you have a large number of pages that constantly churn, with old pages expiring and new ones being created every day, search engines might have to crawl through thousands of existing pages to find the few hundred new pages created. Sitemaps can help them find the new content quickly.
Publishing sites
If your site is set up to be indexed in Google News, an XML Sitemap containing content less than 48 hours old with additional meta data can significantly improve the indexing of content, even if the web crawler has problems.
Uncrawlable Sites
In the early days of the web, many websites were built with content accessible through forms, which search engines could not crawl. Sitemaps were a way to help work around this problem. However, most websites have been completely rebuilt since this problem was understood so it’s been solved in most cases with good internal linking.
Everyone?
A Sitemap might not be required if you have a small or optimized site, but they do mean you’ll get extra Webmaster Tools reports that give great feedback on indexing problems. Consider implementing one as a way to get more information on how your site is performing.
Creating Sitemaps: A Quick Guide
What to Include
- Do not include pages that return a non-200 status code (you can see and export a list of these pages using Lumar’s Non-200 Status Code report).
- While not desirable, including disallowed pages is OK as they will be ignored.
- Including redirecting URLs is OK as a one-off exercise to show Google the redirects. However, they should not be left in Sitemaps as a general rule as their inclusion causes unnecessary crawling or can result in Sitemaps being rejected.
- Do not include any non-indexable pages, including those with a noindex tag or those that are canonicalised to another URL.
- Do not mix URLs from different domains.
- A last modified date (<lastmod>) is optional; if used, it should match any date/time in the HTML to avoid confusion.
- Tags for <changefreq> and <priority> are also optional but can be left out.
Formatting
- Sitemaps don’t need to be XML format: text files are fine if you don’t want to use the additional attributes required for XML.
- Google require Sitemaps to be UTF-8 encoded; you can use entity escape codes for ampersands, single quotes, double quotes and greater than/less than symbols.
- Always use absolute URLs.
- Do not include URLs with any additional tracking parameters.
Thresholds
- Max number of items > 50,000
- Max Sitemaps per Index > 50,000
- Max file size > 50MB
- Max load time > 60 seconds (Google will time out after two minutes)
Internal Linking & Sitemaps: Identifying Gaps
Pages can exist in the Sitemaps but not linked internally, or they can be linked internally but not included in Sitemaps. Whether accidental or deliberate, both scenarios are a problem and should be fixed. Either improve your internal linking structure to include all pages in the Sitemap, or update your Sitemap(s) to include all pages that are linked within the site.
If you have linked URLs or URLs in Sitemaps that don’t generate traffic or are no longer required, disallow or delete them to minimize your crawl space.
Other Considerations
- If you have multi-language/country websites, you should be using hreflang. Sitemaps are the best way to implement hreflang because the information is only required by search engines, so including it in the HTML of pages adds unnecessary weight to the page.
- Having content duplicated in sitemaps is OK, but it makes the site data you get from your Sitemaps unreliable.
- If you have separate sub-domains for mobile and desktop versions of your site, you should also use a rel=”alternate” tag to help Google identify each version. This can also be done in the Sitemap. For more information, see Google’s mobile configuration guide.
For more information on creating Sitemaps, please visit Google Webmaster support.
- If you have multi-language/country websites, you should be using hreflang. Sitemaps are the best way to implement hreflang because the information is only required by search engines, so including it in the HTML of pages adds unnecessary weight to the page.
- Having content duplicated in sitemaps is OK, but it makes the site data you get from your Sitemaps unreliable.
- If you have separate sub-domains for mobile and desktop versions of your site, you should also use a rel=”alternate” tag to help Google identify each version. This can also be done in the Sitemap. For more information, see Google’s mobile configuration guide.
For more information on creating Sitemaps, please visit Google Webmaster support.
Naming Your Sitemaps
How you name your Sitemaps depends on how public you want them to be: some sites choose to keep them private so that competitors can’t access data about their site’s structure.
Public
If you want to make your Sitemap or index Sitemap accessible to everyone, name it sitemap.xml. Include all of your Sitemap index URLs, or individual Sitemaps, in your robots.txt file so that Google can find them.
Private to Anyone Without a Link
To hide your Sitemaps from competitors, consider naming them something that could not be guessed. Remove the Sitemap URL from the Robots.txt and submit your Sitemap(s) manually so that Google can find it.
Only Accessible By Search Engines (Advanced)
Do a reverse DNS lookup on the request IP address to confirm the identity of the user and block access. Submit your Sitemap(s) manually.
Multiple Sitemaps for the Same Site
Using one Sitemap for a very large site might be unwieldy and unmanageable, putting your site at risk of errors and meaning you’ll waste time by sifting through a large amount of data. Splitting it into multiple Sitemaps can help.
Use a Different Sitemap for Different Types of Content
Generally it’s useful to include as many Sitemaps as possible, broken down into different types. For example, one for product pages, one for new product pages and one for category pages.
You can also use an extra Sitemap for different purposes, such as:
- Unlinked content
- New content (anything less than a couple of days old)
- Indexing stats
- Redirected content, only to show Google the redirects
Index Sitemaps
Index Sitemaps allow you to build multiple Sitemaps and submit them to Google together. The structure of index Sitemaps should be two levels deep: don’t nest index Sitemaps within other index Sitemaps.
Multi-Dimensional Sitemaps (Advanced)
Multi-dimensional Sitemaps allow you to include the same URL in multiple Sitemaps. For example, for an ecommerce site, you could use a set with your products broken down into main categories. With multi-dimensional Sitemaps, you could also include additional Sitemaps with the products grouped by those in stock, and those out of stock.
Using this method, you might be able to identify a pattern of pages out of stock that are not being indexed, which you wouldn’t necessarily spot from the category Sitemaps.
Sitemap Audits with Lumar (formerly Deepcrawl)
Crawl Type
Lumar gives you the ability to run crawl your website, XML Sitemaps and organic landing pages (as well as other sources like Google Analytics) at the same time. This gives you a fuller picture from a single crawl, with an understanding of the gaps. In step 2 of your crawl setup, make sure you have the website and sitemaps crawl sources included in the crawl.
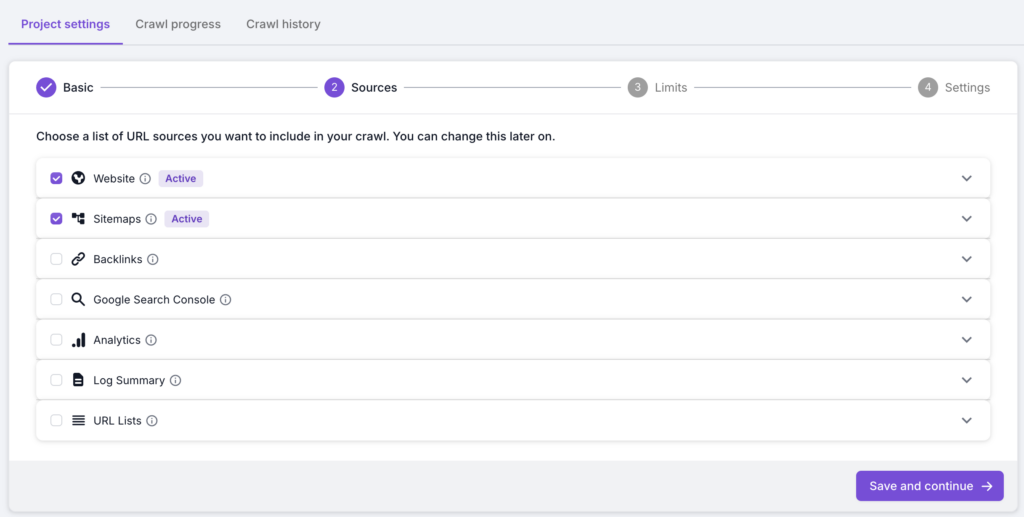
Run the crawl to check all the URLs in your Sitemaps and compare them to the rest of your site. Once the crawl has finished, you will be able to drill down to each URL to see which sitemaps the page is included in:
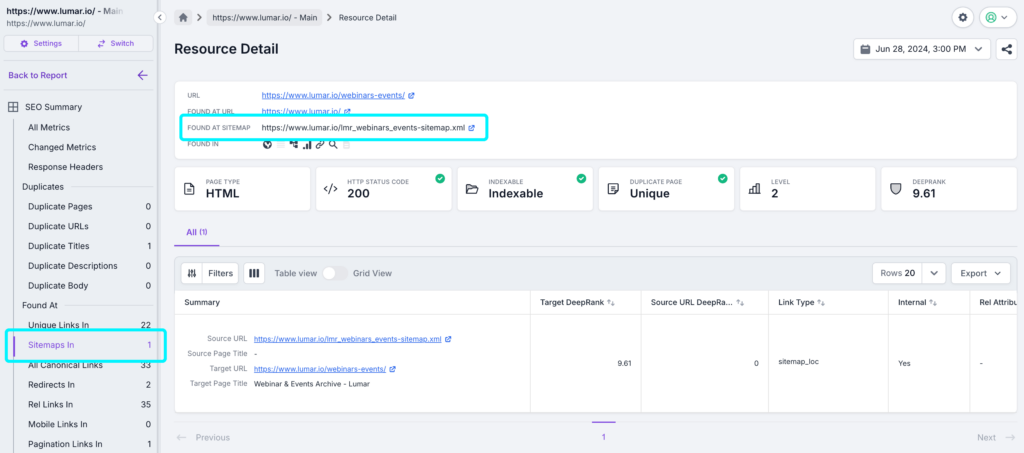
A crawl that includes a web crawl and sitemaps will also reveal gaps in the Sitemap or internal linking structure by showing you where they don’t match. You can see which URLs are in the Sitemap but not linked, and those that are linked but not contained in your Sitemap.
Lumar (formerly Deepcrawl) will automatically detect your Sitemaps. If you need to manually identify the Sitemaps for Lumar, then the same is probably true for Google.
Sitemap Reports
Lumar contains a number of reports for Sitemaps, as well as various visualizations on dashboards. Let’s take a look at the reports, which you can find by using the search reports function at the top of the left-hand navigation.
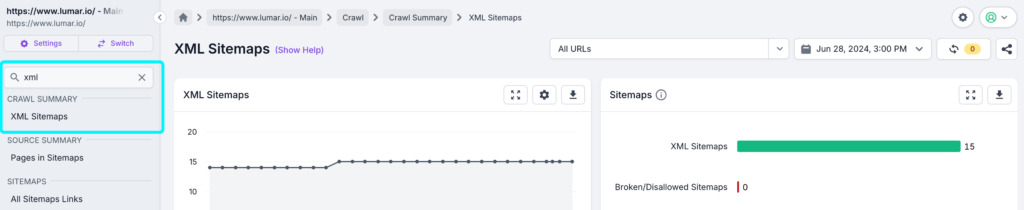
| Section | Report | Description |
| Crawl Summary | XML Sitemaps | All XML sitemaps included in the crawl. These can be reviewed to find broken sitemaps, and the number of items in each Sitemap. |
| Source Summary | Pages in Sitemaps | URLs found linked in the sitemaps included in the crawl. These will be crawled by search engines, so should be reviewed to ensure URLs included are appropriate. Sometimes you may want to include non-indexable, and non-200 URLs in your sitemaps, so these need to be reviewed manually. |
| Pages Not in Sitemaps | Pages not included in sitemaps that may have been omitted deliberately or accidentally. These should be reviewed to ensure any important pages are included in Sitemaps. | |
| Mobile Indexability | Mobile Alternates in Sitemaps | URLs that were found within the mobile/AMP rel alt tag of another page. Separate mobile should be included as a link attribute under the desktop URL entry, rather than a separate entry. |
| Crawl Budget | Pages without Bot Hits in Sitemaps | Pages that appeared in a sitemap, but did not have any requests in the Log Summary files included in the crawl. These pages may be uncrawlable, or may indicate that search engines are not aware of these sitemaps, or not crawling them. |
| Internal Linking | Orphaned Sitemaps Pages | Pages included in Sitemaps, but not linked to internally. These pages may be low value and potentially removed from sitemaps, or might be valuable pages which should be linked to from other pages. |
| Sitemaps | Primary Pages Not in SERPs Not in Sitemaps | These pages are unique and indexable but did not generate any impressions in Google’s search results. Adding these pages to Sitemaps might increase the chances of these pages to get indexed and start ranking in SERP. |
| All Sitemaps Links | All links in sitemaps to pages. These can be reviewed to see their response codes, and check the combinations of source sitemaps and target URLs. | |
| Primary Pages Not in Sitemaps | Primary (non-duplicates, or the primary page of a duplicate set), indexable pages which were not found in any Sitemap included in the crawl. These may have been omitted deliberately or accidentally so should be reviewed to ensure all important pages are discoverable via your sitemaps. | |
| Broken Sitemap Links | Pages found in the Sitemaps included in the crawl that return a 400, 404, 410, 500, or 501 HTTP response code. These should be fixed or removed from the sitemap. | |
| Redirecting Pages in Sitemaps | These pages are redirecting, but are included in your sitemaps, so should be investigated to check that they have been included intentionally, and removed from sitemaps if not. | |
| Non-Indexable URLs in Sitemaps | Non-indexable pages that were found in the sitemaps included in the crawl. These should be reviewed and either removed from sitemaps or make them indexable if appropriate. | |
| Disallowed/Malformed URLs in Sitemaps | URLs found in sitemaps which could not be crawled because they were disallowed in robots.txt, or malformed. The robots.txt rules should be reviewed to ensure URLs have been disallowed correctly, or removed if not. Malformed URLs should also be reviewed to either remove or update them. | |
| Sitemaps with >50,000 URLs | Sitemaps included in the crawl which contain more than 50,000 URLs. Consider splitting these into smaller sitemaps with less than 50K URLs in each. | |
| Broken/Disallowed Sitemaps | Sitemaps included in the crawl which return a broken status code such as 404 or 501, or are disallowed by the robots.txt file. These should be reviewed and fixed/removed as appropriate. | |
| Empty Sitemaps | Sitemaps that return a valid 200 status code but don’t contain any valid URLs. The sitemap generation process should be checked to understand if it has failed, and either fixed or removed. | |
| Primary Pages in Sitemaps | URLs found linked in the sitemaps included in the crawl that are indexable, and unique or the primary page within a set of duplicates. | |
| Duplicate Pages in Sitemaps | Indexable pages found in sitemaps and share an identical title, description and near identical content with other pages found in the same crawl, excluding the primary page from each duplicate set. These should be reviewed and the duplicates removed. | |
| Error Pages in Sitemaps | Pages in sitemaps that responded with an error HTTP status code such as 404 or 501. These should be reviewed and broken pages fixed or removed from the sitemap. |



