

Shopify is one of the most popular eCommerce platforms available and with good reason. Its simplicity of setup and use is second to none. However, as always in SEO, there is always some room for improvement – particularly with crawling and URL management.
In this article, we run through some common Shopify crawling issues we regularly see and how to fix them.
1. Multiple product URLs
One of the most common issues we see on Shopify sites is the default way they link to product URLs. The same product can be linked to via several different “long” product URLs, based on the collections it’s part of, for example, the following URLs are linked to internally:
https://example.com/collections/coats-jackets/products/great-product-1
https://example.com/collections/coats-jackets/products/great-product-1
These then canonicalize to the “simple” version of the product URL:
https://example.com/products/great-product-1
Why does this matter?
While this isn’t necessarily a problem for indexing or duplication, as the URLs are canonicalized, it can make the site much larger for search engine crawlers to navigate through and reliant upon canonicals to pass value through the site, rather than direct internal linking.
When you have an entire eCommerce store of products, this can quickly increase the number of URLs that search engines need to crawl.
How to fix it?
Luckily, this is a fairly simple one to fix, although it does require editing the theme.liquid files. Paul Rogers has an excellent guide on how to change product URLs in Shopify to guide you through.
One thing to keep in mind is that depending on your theme, the liquid file you edit may be different from the example, or there may be several different liquid files you need to edit to remove the “within:collection” from to ensure “long” product URLs aren’t being linked to internally.
2. Tags introducing crawlable URLs
When filters are used based on product tags on collection pages, one of the consequences can be that additional URLs are introduced into the HTML. This appends the tag onto the end of the collection URL, for example:
https://example.com/collections/coats-jackets/leather
https://example.com/collections/coats-jackets/denim
This appears to break Shopify’s URL structure and create sub-collections, but in fact, it’s simply the tag appended to the end of the URL. The page itself has the same targeting as the collection (page titles, h1s, content do not change), with the exception of the products now being filtered.
Why does this matter?
As these tag URLs are linked to in the HTML, they can be crawled, which bloats the site with duplicate pages. If you have a larger number of collections, filter options, or both, this can quickly increase the number of URLs that are crawlable on your site.
In some cases, these filter tag URLs are also not canonicalized, therefore resulting in a large number of indexable pages.
You can check the source code of your collection pages for the filter tag URL to check if this is the case with your filters.
How to fix it?
Although this requires developer resource to fix in our experience, filters can be changed so that the filter tag URL is not included in the HTML (or rendered Domain Object Model (DOM)). This means that although a user can still access the URL when they click on the filter, they aren’t crawlable by search engines.
Another quick win is to make sure these URLs aren’t being linked to in place of actual collection pages (or mistaken for “subcollections” which aren’t currently available in Shopify). They lack the optimal optimizations so aren’t recommended to target keywords of interest.
3. Apps introducing additional URLs when rendered
Apps in Shopify can add a huge amount of functionality to your eCommerce store, if your website has a need for it, there’s a good chance there’s an app (or several) that fulfill your need.
However, not all apps are built with SEO as their primary concern.
This means that some apps introduce new URLs that are crawlable (and sometimes indexable) in search engines. Unlike the filter tag URLs, these are not present in the HTML, however, are present in the rendered DOM. This also makes them particularly easy to miss when reviewing a site.
When reviewing a site, make sure to crawl your site (or a section of your site) with JavaScript rendering enabled, to check if any URLs are being introduced when the site is rendered that aren’t present in the HTML.
An example of how to do this in Lumar can be seen below. You can also check this manually by using Developer Tools to see the URLs present in the DOM.
Why does this matter?
When apps introduce new URLs into the DOM, it makes them findable when search engines render the site. As rendering is a lot more resource-intensive than simply crawling the HTML, this means search engines could be spending a lot of time crawling new URLs when the page is rendered, for little or no benefit.
How to fix it?
The fix for this issue is really depending on which app is being used. Some apps have options to limit the number of URLs created (for example if pagination of the app is creating a large number), or remove the links from the DOM entirely.
If you can’t find this option in your app-of-choice, then reach out to their support to see if they can help.
4. Secondary domains
One of the great things about Shopify and the reason it’s so popular is it’s very easy to use. One of these areas is the ability to easily add secondary domains associated with your site.
However, if not properly configured, these can introduce additional low-value or duplicate URLs to your site.
Why does this matter?
Having secondary domains that aren’t properly configured can lead to a lot of additional URLs being crawled on your site. It can also create multiple versions of the same page, which could compete against one another.
The idea is to consolidate all versions of a domain to your primary domain, to save on unnecessary URLs being crawled, and to ensure all internal link equity is being passed to the URLs you want to rank.
How to fix it?
Luckily, the fix for this is an easy one.
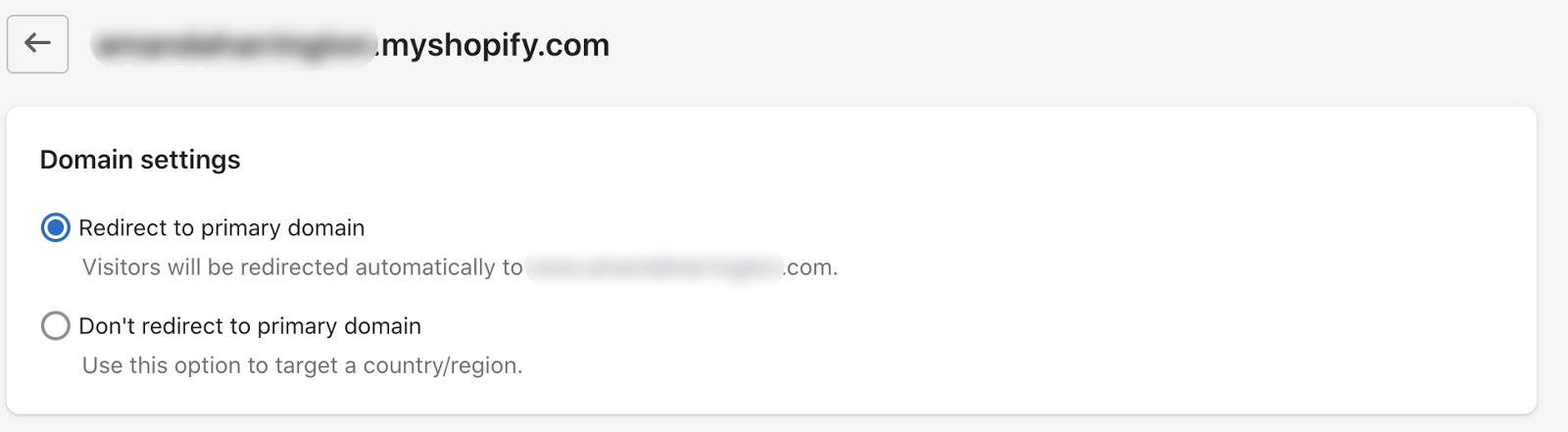
Just navigate to Online Store > Domains and click on your secondary domain. You should then ensure your secondary domain is set to “Redirect to primary domain”.
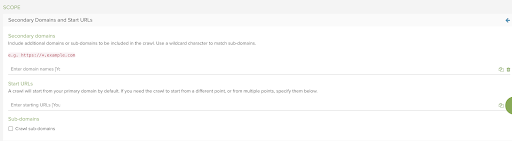
When using Lumar to crawl your Shopify site, you can enter Secondary Domains to crawl to ensure these are all suitably redirecting to your primary domain.
5. Automatic XML Sitemaps Limiting Crawling
Shopify XML sitemaps are automatically generated if a page is live, with different sitemaps for products, collections, pages, and Shopify blog posts. 99% of the time this is the easiest option to tell search engines which pages should be crawled and prioritized.
However, in certain cases, you may want to indicate to Google to crawl other URLs using an XML sitemap. By default, this is not possible on Shopify.
Why does this matter?
Although fairly infrequent, there may be situations in which it’s useful to specify to search engines URLs that aren’t automatically contained in the Shopify sitemaps.
For example:
Migrating to Shopify
Allowing search engines to crawl old URLs can help speed up how quickly redirects are processed, therefore it can be useful to host and include old sitemaps on Shopify for a short period of time.

Source – https://developers.google.com/search/docs/advanced/crawling/site-move-with-url-changes
Variants
There may be times in which you want Google to index pages that are outside of Shopify’s standard functionality and are thus not included in the sitemap by default, for example, variants or URLs created through the use of apps.
How to fix it?
Luckily, there is a workaround to this, which allows custom XML sitemaps to be created in Shopify.
This involves uploading the sitemap as a file to Shopify and then redirecting a URL to the file location, which can then be uploaded to Google Search Console for URLs to be discovered (this may work for other search engines, but has only been tested in Google Search Console currently).
6. Tag and category blog pages
Creating categories for your blog and tagging blogs can be useful for users and search engines to navigate through your site and understand the context of your blog posts in more detail. However, it’s always worth reviewing to ensure these are relevant and necessary.
Why does this matter?
Although unlikely to be an issue at the same scale as some of the other crawl considerations discussed above, in an SEO world where everything counts, the number of URLs you create is always worth keeping an eye on.
A blog post with hundreds of different categories and tags can significantly bloat a site with URLs that aren’t optimized for search engines. These usually follow the following format:
https://www.example.com/blogs/tagged/first-blog-tag
How to fix it?
The best fix is the preventative measure of only creating blog categories that are directly related to your content and help your users to navigate and understand your blog with more clarity.
If you’ve already created a lot of categories or tags, it’s never too late to audit these. Removing them from blog posts and deleting them in the backend of Shopify (redirecting to a relevant page if necessary, although not strictly required) will prevent them from being crawled.
How to identify crawling issues
With any crawling issue on a site, your first step is to understand what you’re dealing with. The best way to do this is to mimic what search engines are seeing by crawling the site using Lumar to see which URLs are crawled.
Any non-indexable URLs are an immediate flag to further review as these are available to search engines to crawl, however, not valid for indexing suggesting a possible optimization. The Non-Indexable Pages report in Lumar is a great place to identify the types of crawling issues on your site and identify specific URLs that are causing the issues.
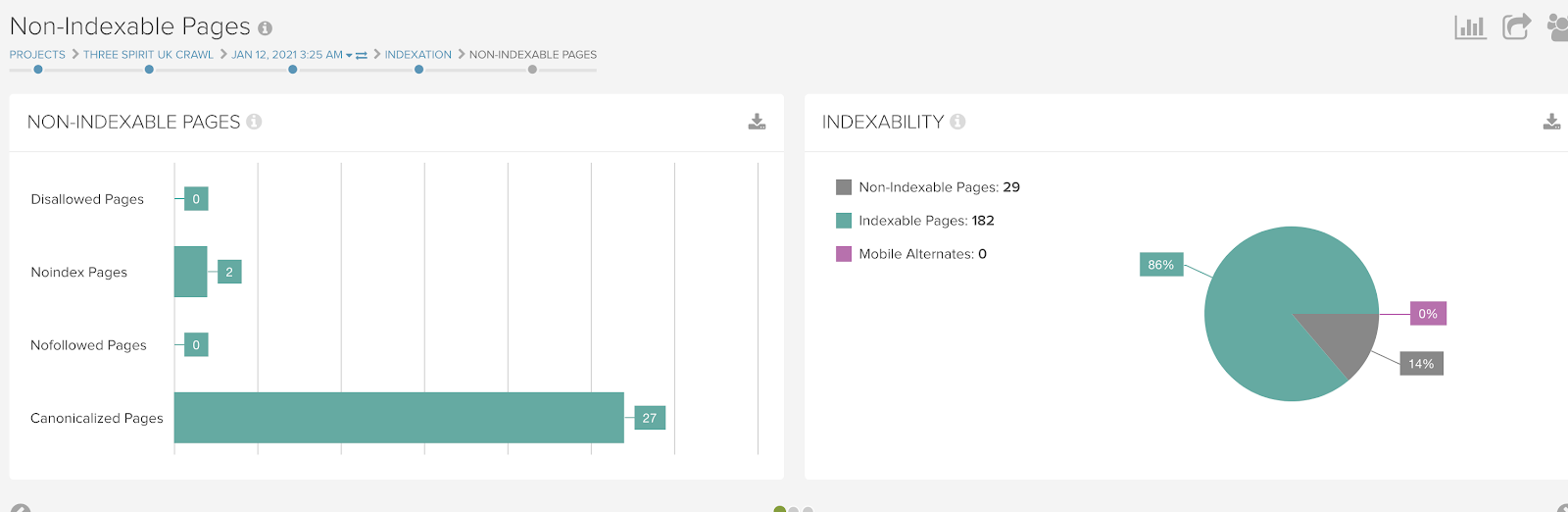
The specific URLs listed in this report can be checked against some of the common issues we’ve discussed above to see if there are any areas to be optimized.
But it’s not just non-indexable URLs that may be an issue, so make sure to check your Primary Page report also as this can suggest not just issues with crawling but also URLs that are available to be indexed.
The “Found at URL” details from these reports also help to understand where these internal links are originating from, so you know where to focus your attention on identifying and fixing the issues.
If you want to only crawl a specific section of your site which you know to be an issue or your eCom site is particularly large, crawls can be limited using the Included & Excluded functionality when setting up the crawl.



