

Last week I got an offer to dropship approximately 7,300 products from a supplier. The supplier said, he had a data feed I could use to build my store from. Sounds good right? Well, the naked truth was that the data feed was nothing more than a Magento product export. Sometimes that’s just fine, but this export was missing one quite important detail: all product images!
To import or not to import
I began to doubt whether to set up a store based on only these details. I mean, what kind of self-respecting webshop doesn’t have any product images? When I contacted the supplier, he promised he would send the missing images. Problem solved right? Not exactly. I received a WeTransfer link of 136MB. Unfortunately, the file that was draining my bandwidth, was in fact one big PDF. It was their offline catalogue, scanned and saved as PDF, sigh.
Ready, set, scrape!
So, what was I supposed to do with a potentially nice opportunity to set up a webshop in a great niche? Well, scrape it, of course! If they won’t give me the images, I’ll take them myself since I already had permission to use them anyway.
Before I began, I considered what I already knew:
- The supplier already has their own, working Magento shop;
- All products on their site contain images;
- The product image can be easily identified in the source code;
- All product URL’s contain the SKU at the end (how convenient).
I decided I had enough anchors to get going. Let the scraping commence!
Back to DeepCrawl
Last time I described (in Dutch) how I identified the taxonomy on certain pages, using DeepCrawl (now Lumar). Since I was in need (again) for some serious crawling, what other choice than to use DeepCrawl again.
My SEO buddy, Monchito, mentioned why I preferred DeepCrawl over other SEO tools. Simple, DeepCrawl can actually extract data, whereas most others cannot.
I used the following settings in DeepCrawl:
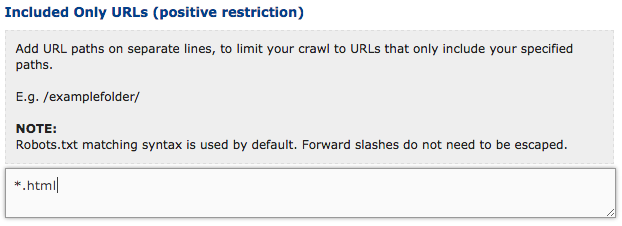
- Only crawl product pages. Using positive restriction to only crawl the product pages and not all categories, filters, etc. Fortunately all product pages end with .html, whereas all categories end with a trailing slash. The positive restriction saved me a lot of time and valuable crawl credits. Only crawl product pages like this:
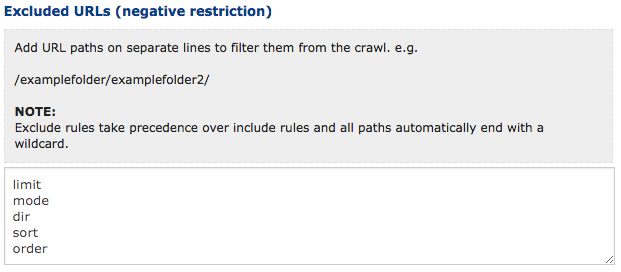
- Don’t crawl any filters. If I allowed all filters available to be crawled on the pages, I would run out of DeepCrawl credits. So, all Magento filters would have to go. Webshop owner, please be aware of these filters. Apply robot restrictions.
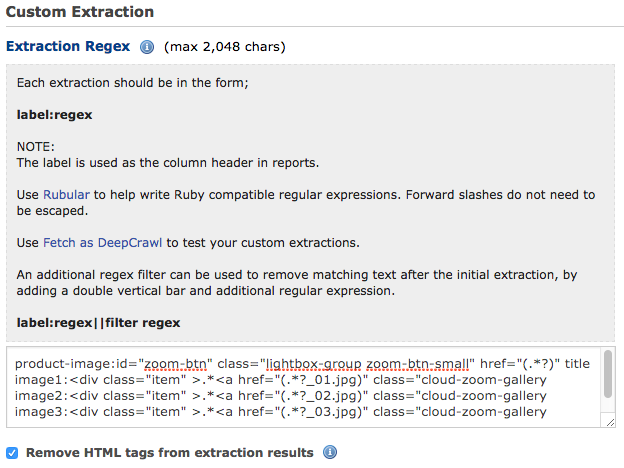
- Get the product image URL’s. First I fiddled with Rubular to get my Regex right. It’s important to collect the URL of the image. On every page there is a link to the main product image, which is triggers a fancy lightbox. The class and ID are the same on every product page, which makes it easy to extract the image URL. We just have to match the syntax and extract the direct link to the image.
Wrapping it up
Overnight DeepCrawl did what it does best – an excellent crawling job. The next morning I was greeted with an email telling me the “Crawl has finished”. Opening the extract report, I saw a number I was quite pleased with: 7,762. A tad more than I expected, but a quick look showed me that all static pages have the .html extension too. No problem, since I can look up only URL’s containing an SKU. That left me with 7,321 URL’s. Spot on with the amount of products in my Excel sheet.

With the URL’s of the product pages along with the extracted image URL’s, I could match them to complete my own Excel sheet. Using some vertical lookups, I was able to pair the SKU’s supplied with the extracted product URL’s that conveniently contained the SKU (e.g. /product-name-129482.html). This enabled me to look up and match the right URL’s containing the images. Splendid!
I then had a complete data sheet to import in a fresh new environment. From there I was able to experiment with some SEO and SEA stuff, try out some wicked CRO ideas, work on my link acquisition techniques and hopefully make some sales along the way. That makes me one happy robot.
Closing up while my store is open for business
So, I now have a fully operational shop (by now you must all be aware that I can’t disclose the website) following some quick and easy crawling. All thanks to DeepCrawl. Sure, I missed extracting the breadcrumbs, which resulted in me categorizing all the products by hand after all. I later found out that it was next to impossible since Magento don’t have actual breadcrumbs on product pages, but more something like click paths. But hey, maybe next time 🙂


