

Let me present an issue that, from my point of view, is crucial to SEO success. Of course, we can create thrilling content, stuffed with attractive graphics. We can optimize titles, alts and other stuff that every SEO expert does. But if we don’t optimize the crawl budget, the spiders may never find your awesome content.
Crawl budget – what it is and why it’s so important?
We can say that the crawl budget is the number of requests made by Googlebot to your website in a particular period of time. In simple terms, it’s the number of opportunities to present Google the fresh content on your website.
Gary Illyes from Google presented a very interesting approach to the crawl budget issue.
The crawl budget is connected to a scheduling of requests that spiders make to check content on a website. He said that Google creates a list of URLs and sorts it from the most important, to the least. Then, robots start crawling the website from the top of the list to the bottom. The ideal situation is that spiders manage to crawl the full list. Yet a common situation occurs when the list of URLs is so large that spiders can’t crawl the website without slowing down the server. Then… they stop crawling.
It’s worth mentioning how Google determines the order of URLs to crawl. It generally depends on the authority (PageRank) of the page. But other signals like XML sitemaps, links etc. also play a role. So, the task of optimizing the process of picking the URLs to subsequently be crawled by Google is in your hands…You may find yourself thinking, where do I start?
In Google Search Console, you can check how many pages Googlebots are crawling. Go to Crawl >> Crawl Stats. There, you’ll find information on how many pages, on average, are crawled by Google.
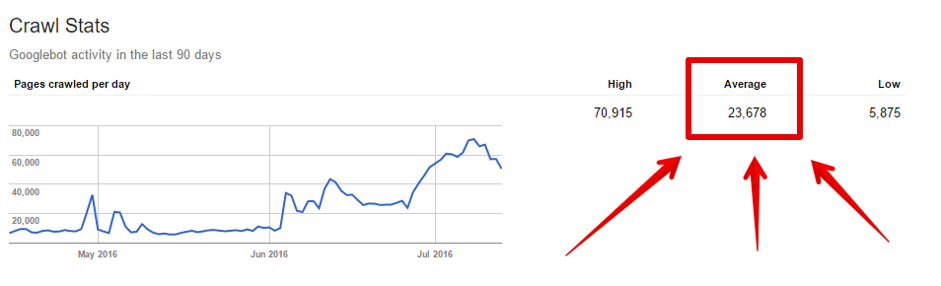
Yes it’s an average, but it can be a starting point in the crawl budget optimization process.
Why is it so important to optimize your crawl budget?
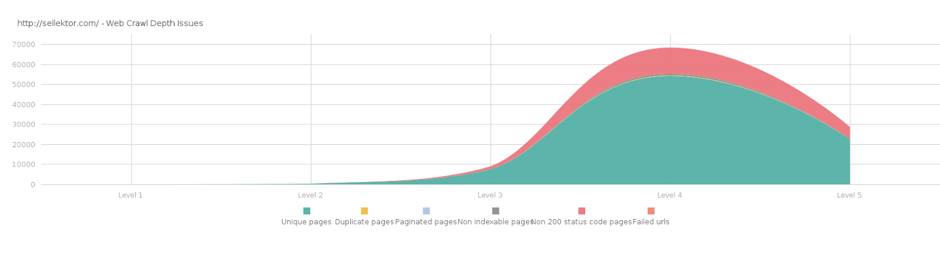
Google is crawling only a particular number of pages on your website, and may sort the URLs incorrectly (I mean differently than you wish). It happens, for example, that your “About us” page (that doesn’t drive sales) will gain more hits than the category listings with the new products. Your aim is to present to Google the most relevant and fresh content.
How to optimize your crawl budget
I appreciate that you have quite a broad set of methods to control crawling by Google. So, I’ll share what I think you should focus on to optimize your website and your crawl budget. There are three general steps to optimizing your crawl budget:
- clean up your website
- speed it up
- analyze server logs
Now let’s take a closer look at it.
Cleaning

E-commerce websites are the polygon for fighting with duplications. Very often, the same content (or almost the same) is available on different URLs. Just think about the sorting, filtering, internal searching options etc. All of them often result in extremely broad duplication. In short: always keep only 1 version of a URL.
Here are some common problems:
- sometimes you can find a product on different URLs. For example, the product URL contains categories like the former instead of the latter:
www.domain.com/category-1/category-2/name-of-the-product
www.domain.com/name-of-the-product
- It’s very common that products belong to two or more categories and may be available on each category path, like this:
www.domain.com/shoes/high-heels/product-name and
www.domain.com/woman/high-heels/product-name
We often see the same problem on category pages.
- variants of the products (color/size etc.) – sometimes each color/size of the product has its own, unique URL. It’s not recommended because, often times, the color/size/volume are the only difference in the product description. Here’s an example:
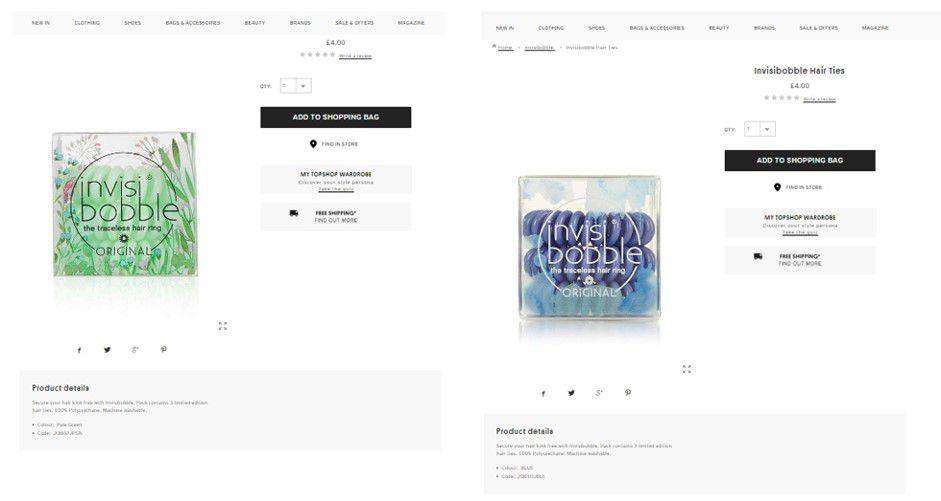
The problems described above are often ‘solved’ with rel=”canonical” or noindex tags. Perfect – duplication problems solved! However, those URLs are still crawled. Google admits that they crawl such pages less often than normal pages (only to check if noindex or canonical is still there), but the budget is wasted.
How do I remove duplication?
First of all, identify where duplicated content is. You can find duplicated pages in DeepCrawl reports:
- Indexable Pages → Duplicate Pages
- Body Content → Duplicate Content
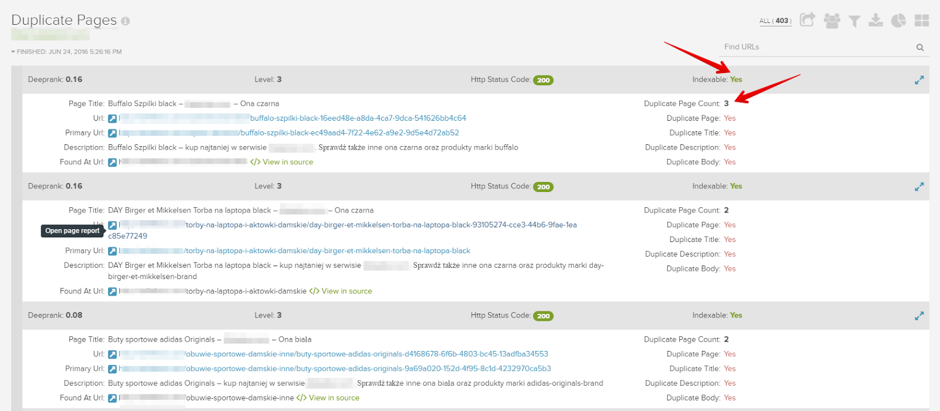
There’s no one way to remove duplication. But, the best solution is to remove the source of the duplication (eg. variants of the same product). Sometimes, you have to deindex some parts of your website. To do this, check if it’s already in Google index. If yes, add a noindex tag in the header to remove those rubbish URLs from Google’s index. To make deindexation as fast as possible, create a temporary XML sitemap. It should contain URLs that you want to remove from the index and then add it to Google Search Console. When this mission is accomplished, you can remove the temporary sitemap and block the URLs in robots.txt.
Faulty redirect
Redirects are the gifts from heaven in SEO. They help in migrations, redesigns and/or updating incorrect URLs. But, incorrectly implemented, they can be the nail in the coffin.
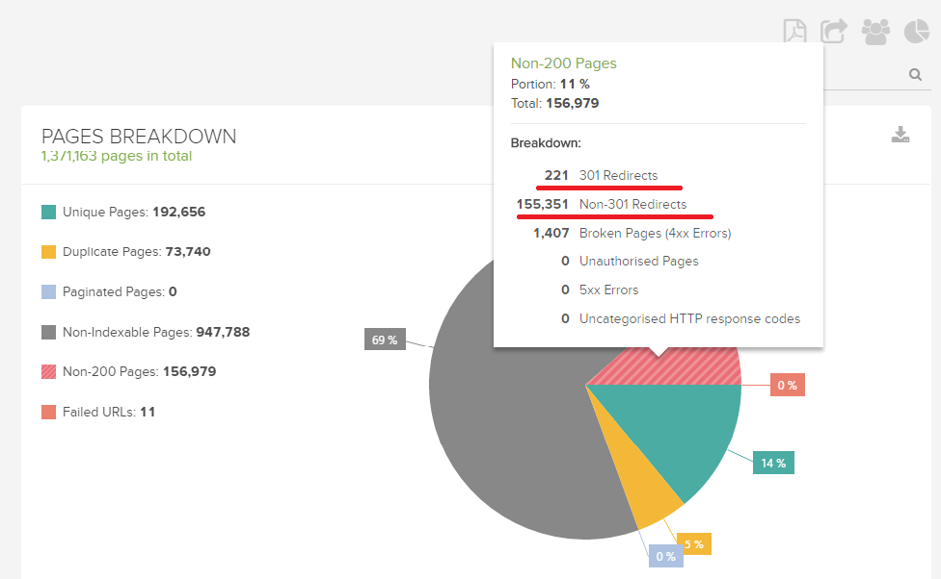
Redirect chains
A Redirect chain is when there’s more than one redirect between initial and final URLs. Here’s an example:

You can diagnose redirect chains with a Redirect Path plugin or check in your DeepCrawl reports: Non-200 Status → 301 Redirects.
Google bots can handle multiple redirects. However, they not only hamper PageRank (as they pass through each chain) but also your precious crawling budget (as each chain is crawled).
Redirects to 404 Errors or non-canonical URLs
The second popular issue is pointing redirects to 404 Errors or non-canonical pages. Here, we are inviting GoogleBot to crawl pages that should be ignored by Google.
How do I remove incorrect redirects?
The bigger the website is, the more complicated redirects are. But it’s worth taking a closer look and monitoring them from time to time.The easiest way to check redirects is to crawl your whole website. DeepCrawl will give you all the necessary information to identify bottleneck areas. With this knowledge you can prepare new and correct redirects.
Clean up URLs returning 404 Errors
I’d like to make it clear – 404 Errors are totally correct. It’s natural that the website (especially expanded ones) may have some 404 Errors. But you should have in mind that those pages are crawlable and can accumulate PageRank as any other page does. Is it profitable for you to spend your crawling budget on pages with errors rather than pages with valuable content? You guessed it: nope!
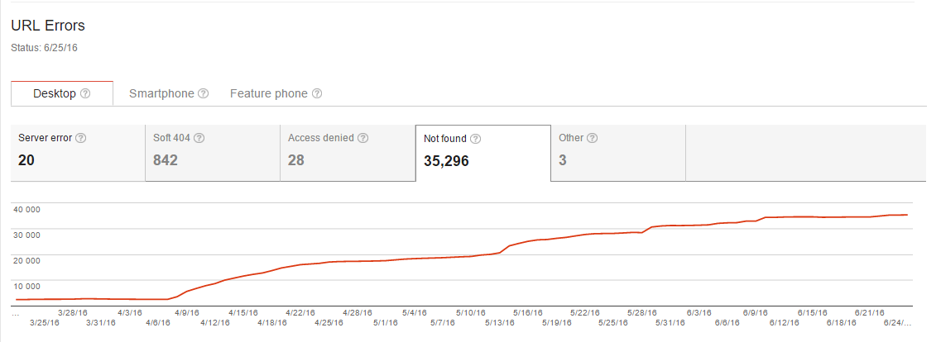
You can see if Google detected any 404 Errors within your website in the Crawl Errors report in Google Search Console. You can download the list (unfortunately only 1000 records) and analyze to see if any of them should be redirected. Check if the Error 404 URL has an actual equivalent or similar page that can be useful to users. If yes, redirect the broken URL to the new one. To have a full view of 404 Error pages you can find them with Deepcrawl – just check the status code of the URLs.
Optimize the robots.txt file
The robots.txt file is the most powerful method while optimizing crawl budget. This robots.txt file is an instruction for robots regarding what URLs or directories shouldn’t be crawled. So it’s crucial that this file is correct.
How to optimize your crawling budget with robots.txt
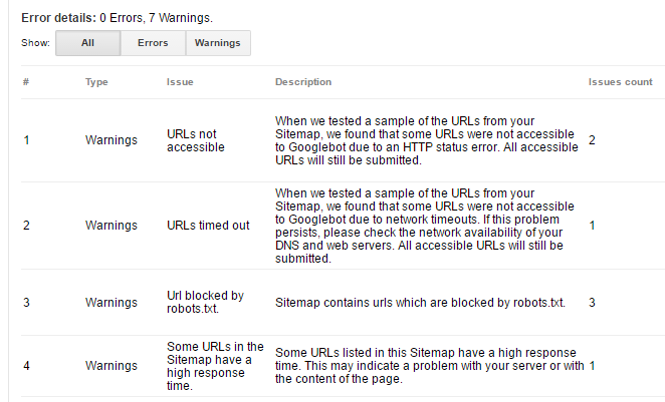
Add to the robots.txt file all directories and URLs that you decide not to crawl. Make sure you don’t block important pages by mistake (yes, it happens). You can easily check what’s blocked in robots.txt with the testing tool in Google Search Console.
Bear in mind that robots.txt is the SUGGESTION to robots (not directive). So, if GoogleBots find many signals pointing to the page blocked in robots.txt, they may interpret it as a mistakenly modified file. As a result, they will still crawl that page. So you should:
- remove blocked in robots.txt pages from XML sitemaps,
- never link from the navigation to such pages,
- avoid linking internally and externally to them
Clean up the XML sitemap
XML sitemaps should contain only the most important URLs that should be visited the most frequently by GoogleBots. Google admits that the XML sitemap is used in the process of creating a list of URLs to crawl. So, it’s worth keeping the XML sitemap updated, free from errors and redirects.
Create a flat website structure
Deep, complex website structures are not just unfriendly to users that have to click deeper and deeper to find the content they want, but are also difficult to crawl for robots (especially if the navigation is ineffective). Always try to keep the most important pages as close to the homepage as possible. A good method is to organize content horizontally in the site’s structure, rather than vertically.
How to improve your website structure
First of all, you should prepare actual website structure. You may be unaware how deep and messy your website is if you don’t visualize it. Then, try to logically reorganize pages – link them thematically, remove unnecessary levels etc.
Optimize the performance of your website
Nowadays repeated as a mantra: the faster the page loads, the better for your users and you of course! That’s right, the reason is not only because it keeps user on the website, it also ensures robots are keen to crawl your website. You can find many resources on how to speed the website up and you shouldn’t hesitate to read and use them. You can diagnose the problem with the performance in Deepcrawl report:
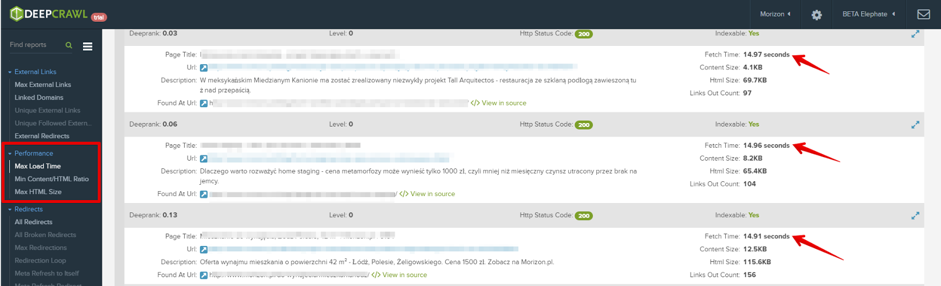
Detecting pages with performance issues it the first step. You’ll find detailed information on what exactly should be changed in free tools like: Gtmetrix or PageSpeed Insight.
Now, I’d like to focus on another extremely helpful component when optimizing your crawling budget – using GZIP Compression. It makes files on the server smaller, so responses from the server to the website browser are much faster. You can GZIP html, css, javascript files, but do not use it to compress images.
Here’s how it works, and the results of speeding up a website:
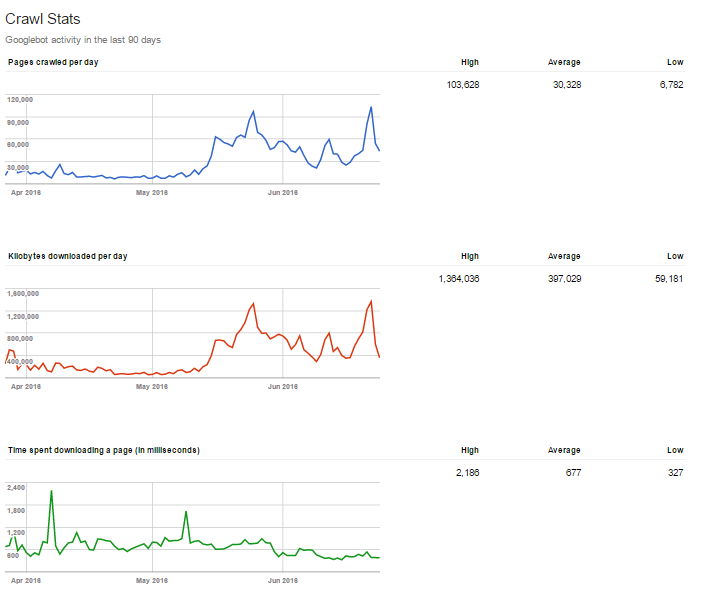
It confirms the earlier statement from Gary – GoogleBots keep crawling the website until the server slows down. So, if the website weighs less and loads faster, the longer spiders will crawl it.
Server logs analysis
Now it’s time to check the effects of your crawling budget optimization. To do so, you need server logs and a software that will help you to analyze data. A server logs file contains data about all requests made to the server. You gain information about a host, date, requested path, a weight of the file etc. As you may think, such files can be huge. The more frequently the website is visited, the more records there are in the file. You can use Excel, but I’d recommend dedicated software for the server log file analysis (eg. Splunk). Digging into server logs will give you information on:
- How often GoogleBots are crawling the website
- What pages are visited the most often
- How much do the crawled files weight
Etc.
Equipped with this knowledge, you can determine if robots are correctly navigating through your website. It will help you to check if the crawling budget is reasonably distributed among pages. If not, go back to the top of this article and optimize it again…
Summary
I hope that crawl budget optimization will become a habit while doing SEO. Bear in mind that all changes made are not only beneficial to robots, as making your website faster, its navigation easier, and/or removing rubbish URLs will make your users happy!



