

In virtually every Google Analytics view, you’re bound to find landing pages in your Google-Organic report that just shouldn’t be there. Whether the pages don’t exist or have never been indexed, these entries are being credited with Google organic visits that are polluting our Analytics reports.
Most of the time it’s not a case of phantom visits, rather it’s usually about misattribution. In this post, we’re going to go over why this happens, and try our best to solve these issues.
Warning: this is an advanced post.
Reasons why non-indexable Landing pages get attributed as Google Organic
Quick clarification, I’m talking about Landing pages, ga:landingPagePath NOT pages, ga:pagePath.
1) Session timeout and last non direct referral
If a user enters a site via Google / Organic, allows the session to time out, and then navigates to a non-indexable page, that non-indexable page will be credited as Google / Organic Landing page.
I had been sceptical about this for a long time, even though experts like Mike Sullivan answered me on Quora, I had to test this many times to make sure this was actually the case – I also had a former colleague double check my test results (thanks Tom Capper).
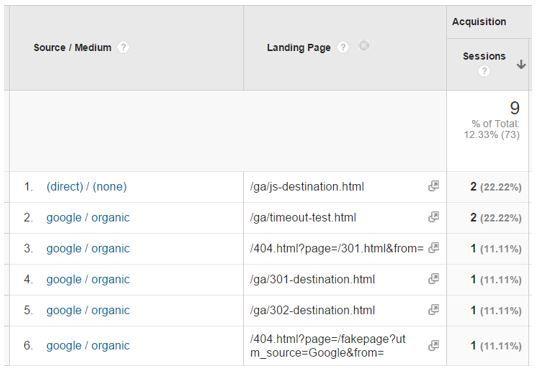
These test URLs are all marked with NOINDEX, and have never been in any search engine index, and yet, they are being tracked as Landing pages.
Here’s an example from nocowboys.co.nz where logged in pages are receiving Google Organic traffic because of sessions timing out and GA using last non direct attribution:
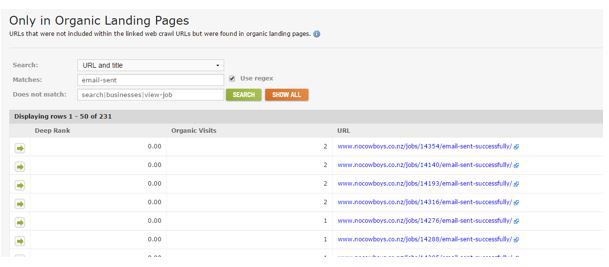
Here I’m using Deepcrawl’s ‘Only in Organic Landing Pages’ report to help me sift through pages that don’t have links (from the crawl). This is a good indicator to find pages that have been wrongly attributed as Google / Organic, but you still need to manually check these to be sure using the site: or info: commands like this:
info:www.nocowboys.co.nz/jobs/14140/email-sent-successfully/
site:www.nocowboys.co.nz/ inurl:email-sent-successfully/
Again, another example from huballin.com’s (Full disclosure: I work with Huballin) internal tool pages, here’s a screenshot from the GA query explorer showing tool pages receiving traffic:
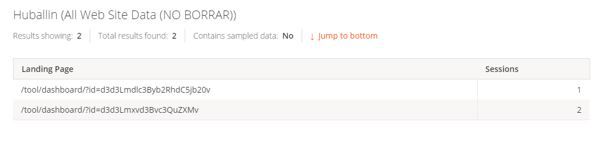
But these URLs were never working in the first place.

Solution to: Session timeout and last non direct referral
There are two ways of solving this problem, but these methods may not solve the problem entirely.
The easiest way of fixing this, is to increase the default session timeout from 30 minutes to the maximum of 4 hours:
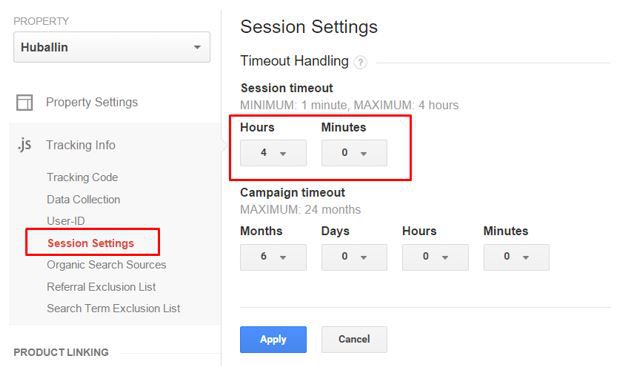
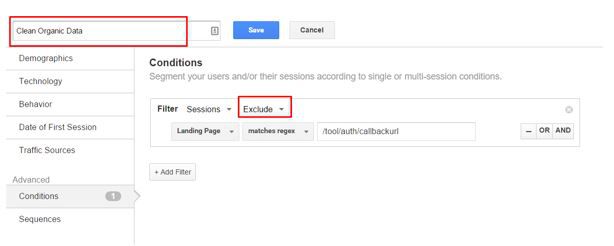
The other option is to segment out the pages you know aren’t valid, and apply it to any view without incurring any loss of data. You could also filter out known ‘bug’ pages, but please create a new view and do not filter your default view, example of segment here:
2) Not all Redirects pass http referer
When a visitor enters a site via Google / Organic and that page redirects via 301,302 or meta refresh to a non-indexable page the final destination page is credited with the Google Organic visit (which is correct). This does not apply to JS redirects for some reason, the original source is lost.
JavaScript redirects don’t always lose the referer, it can depend on the JS used (window.location.href ), or even the browser. For example, my JS script below didn’t pass the referer in Chrome, IE, or Firefox:
<script type=”text/javascript”>
window.location.replace(“https://www.davidsottimano.com/ga/js-destination.html”);
</script>
Test methodology for all redirects: The way the tests were executed was fairly simple, I used one page that ranked in Google’s index to perform the different types of redirects (one after another) and created 4 destination pages with GA code on them as the trackers. For example, to check if 301’s passed the source, I created a server side redirect for the ranked blog post to the 301-destination.html page and then used incognito mode to create a new browser session, searched for a query that result in my page and clicked on it from a SERP.
Again, the results of my tests (repeated twice)
- 301 test – referer carried
- 302 referer carried
- Refresh – carried
- JS test – referer lost (but it can be passed depending on code + browser)
Solution to: Not all Redirects pass referer
Either use server side redirects, avoid JS redirects altogether, or try modifying / testing the JavaScript so that the referer isn’t dropped.
3) What shouldn’t be indexed turns out to be indexed
Code changes often, errors happen all the time. It’s possible that Google has rejected your canonical declaration, or potentially you didn’t realize portions of your logged in area didn’t require authentication and got crawled.
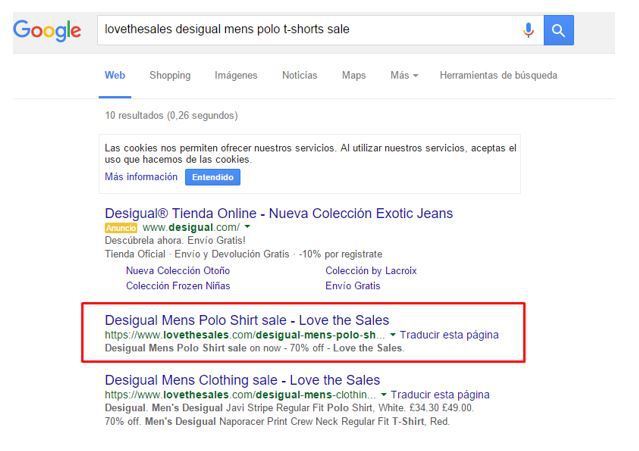
Here’s an example from lovethesales.com where DeepCrawl reported this particular page (https://www.lovethesales.com/desigual-mens-polo-shirts-sale) as 404, yet it’s still alive in Google’s index:
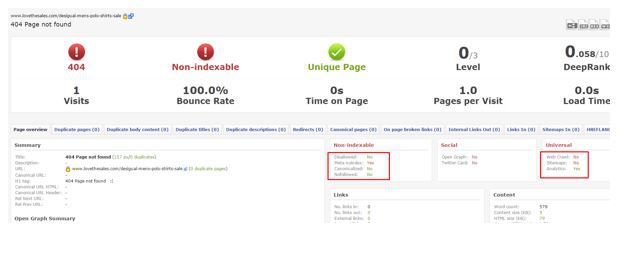
DeepCrawl URL report:
Lots of weird things can happen:
- Google ignores directives or keeps deleted pages around in the index
- Code changes happen without your knowledge
- Etc..
You must check manually to be sure – or automate your Google scraping, whichever you prefer.
Solution to: What shouldn’t be indexed turns out to be indexed
When you have your Analytics data side by side with SEO specific crawl data, you can create warning flags based on certain conditions, but you will still have to check if these pages are indexed manually.
I marry two reports from DeepCrawl to get this done quickly, one being the All URLs report in the Indexation section, and the All Organic Landing Pages in the Universal section:
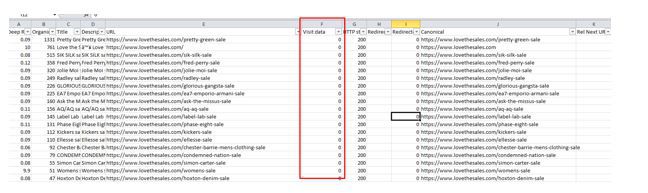
Here are the conditions that may cause a page not to be indexed:
- Pages contain NOINDEX directives in head, http header or txt
- Status code = 3xx, 4xx, 5xx
- Canonical target does not match URL
- From Search Console: Parameter exclusion, removal requests.
- Fringe cases: check the Search Console (WMT) for any messages regarding removal of pages because of a right to be forgotten request, manual actions or DMCA requests, or you’ve flagged for being hacked.
- Currently not identifiable: Penguin or Panda can rip a page out of the index, but Google does not officially tell webmasters in any way.
How should you check manually?
Use the info: and/or site: search operators to check – this is the only way to do this properly.
Once you’ve created your flags and double-checked in the SERPs, you can repeat the solutions in the first point of this post: either create an advanced segment or create a new view and filter the bad pages out.
4) Analytics are manipulated / spammed
This is the most unfortunate reason, and I don’t know how to stop it. Simply building a URL with the right parameters in the URL builder and executing on someone’s site will skew Google Organic stats.
I’m not going to detail how to do it, because I’d rather no one did it. It’s really not a nice thing to do and we shouldn’t do it.
Solution to: Analytics are manipulated / spammed
Unfortunately, I don’t know of a solution. If anyone can help out, I’ll happily give credit in the article.
5) GA code customization: Rewriting default landing page URLs
This is rare but I’ve seen analytics profiles where the Google Analytics default pageview tracking URLs are rewritten into custom URLs, like so:
_gaq.push([‘_trackPageview’, ‘/category-a’]);
In my opinion, you should never rewrite page URLs – there are content grouping categories, custom variables, segments and even events you can send to identify page types without overwriting your default page URL.
This particular site had been reporting on bad data, this is why:
Example.com/boats & Example.com/boats?sort=2 are both sending pageviews to:
_gaq.push([‘_trackPageview’, ‘/boats]);
Problem is in this case that example.com/boats had a NOINDEX directive on it, where Example.com/boats?sort=2 was indexed and routing the Google Organic traffic to the NOINDEX page.
This was a fringe case, but the message is still the same – don’t rewrite the default landing page.
Solution to: GA code customization: Rewriting default landing page URLs
Don’t touch the default page tracker, instead, use content grouping, custom variables or even advanced segments.
If I’ve missed anything, please get in touch via Twitter (@dsottimano) and I’ll happily update the post with credit.



