

Following on from our beginner’s guide to implementing noindex, disallow and nofollow directives, we’re now taking a look at some more advanced methods for controlling Disallow directives in robots.txt.

In this guide for intermediate and advanced SEOs, we’ll cover PageRank, JS/CSS files, indexation, parameters, pattern matching and how search engines will handle conflicting Allow/Disallow rules.
When and how to use Disallow
Disallowing a page means you’re telling search engines not to crawl it, which must be done in the robots.txt file of your site. It’s useful if you have lots of pages or files that are of no use to readers or search traffic, as it means search engines won’t waste time crawling those pages.
To add a disallow, simply add the following into your robots.txt file:
Disallow: /page-url/
When not to use Disallow
Don’t disallow pages that you want to pass PageRank
If a URL is disallowed in robots.txt, it won’t be crawled, and therefore can’t pass PageRank. So don’t disallow any pages which are likely to have external links, or are necessary for linking to other internal pages.
Don’t use Disallow for parameters
As mentioned by John Mueller in a recent Google Webmaster Hangout, blocking parameters using Disallow will mean that the authority signals will not be consolidated for the original URL, as Google will not be able to see the URLs with the parameters and therefore won’t know that the pages are duplicates of each other.
The best way to consolidate URLs with parameters is to use a clean URL structure, 301 redirects, canonical tags or Google’s URL Parameters tool. Find out more at our guide to parameter handling.
Don’t disallow JS and CSS files that allow Google to understand the site
Disallowed CSS and JS is only really an issue if it actually prevents Google from finding visible content, or rendering pages correctly.
Google updated their Webmaster Guidelines in 2014 to recommend allowing Googlebot to CSS and JavaScript files, so that they can render pages like a browser. They reiterate this for mobile pages on the Google Developers Mobile Guide so that they can check mobile pages for mobile-friendliness, and in the announcement about deprecation of the AJAX crawling scheme to allow them to render and understand pages that use JavaScript.
Other JS files don’t matter so much and there are no penalties for blocking a certain percentage or number of files if they don’t impact the content or layout.
Does Disallow prevent URLs being indexed?
Remember that Disallow does not prevent URLs being indexed; it only prevents Google from crawling them. So if the URL is linked to, either internally or externally, or linked in a canonical tag, the page may still end up in search results, but Google won’t be able show any information apart from the URL.
In this case (if a disallowed URL is showing in search results) the URL will show in place of a title and the description will say: “A description for this result is not available because of this site’s robots.txt.”
Combining Disallow with noindex
Combining a Disallow directive with a meta noindex isn’t possible, as the Disallow in the robots.txt will prevent the page being crawled, meaning search engines cannot see the noindex directive.
However, while the meta noindex is the most common noindex method (and the primary method that Google recommends), there is another noindex method available that gets around the issue above. This second method involves adding a noindex tag to your robots.txt file in a similar way to adding a Disallow directive. This means it’s possible to combine a robots.txt noindex with a Disallow directive to stop the page(s) appearing in search results at all.
However, John Mueller from Google has stated that ‘you shouldn’t rely on it’.
Disallowing in robots.txt: formatting
Pattern matching in URLs
Google and Bing both accept the following expressions, which can be used to exclude any URL that matches the pattern specified.
- *: wildcard. Can be used to signify any sequence of characters.
- $: matches the end of a URL that ends in a specific way (such as a file extension).
Both of the above can be used in a variety of different ways and combinations to control how Googlebot and other web crawlers crawl your site. Use one directive per line.
Note that directives in the robots.txt file are instructions only: malicious crawlers will just ignore your robots.txt file and crawl any part of your site that is not protected, so Disallow should not be used in place of robust security measures.
Disallow all web crawlers:
User-agent: *
Disallow a particular file type:
The following directive will block all PDF files from all user agents, using * to represent any PDF file name and $ to indicate that any URLs ending in this way should be excluded from crawling.
User-agent: *
Disallow: /*.pdf$
Disallow any directory containing a certain word:
The following example would block all subdirectories that begin with the word ‘example’:
User-agent: *
Disallow: /example*/
Disallow URLs with queries:
You can also use a question mark within your directive to block any URL that contains a question mark (ie. a URL with a parameter). The following example will disallow any URL that has a string in the subdirectory, followed by a question mark, and then another string:
User-agent: *
Disallow: /*?
Disallowing parameters in robots.txt will increase crawling efficiency (as search engine crawlers won’t try to crawl each parameter as a separate URL) but won’t consolidate authority signals in favour of the original URL, as search engines won’t be able to crawl the page to know that the signals should be consolidated.
Spaces between blocks of directives
Google ignores spaces between directives and blocks. In this first example, the second rule will be picked up, even though there is a space:
User-agent: *
Disallow: /disallowed/
Disallow: /test1/robots_excluded_blank_line
In this example, Googlebot-mobile would inherit the same rules as Bing:
User-agent: googlebot-mobile
User-agent: bing
Disallow: /test1/deepcrawl_excluded
Conflicting Allow/Disallow rules
If an Allow and Disallow rule both match a URL, the longest matching rule wins
When writing Allow and Disallow rules, the Allow is a bit shorter, so adding spaces lines up the characters making it easier to see which rule is longest.
A matching Allow directive beats a matching Disallow only if it contains more or equal number of characters in the path
Just to clarify, we’re talking about the number of characters in the matching directive path after the Allow: or Disallow: statement. This includes the * and $ characters, for example:
Disallow: /example* (9 characters)
Allow: /example.htm$ (13 characters)
Allow: /*htm$ (6 characters)
In the following example, the URL /example.htm will be disallowed because the Disallow directive contains more characters (7) than the Allow directive (6):
Allow: /exam*
Disallow: /examp*
However, if you add a single character to the Allow directive, the number of characters is equal and the Allow wins:
Allow: /examp*
Disallow: /examp*
This even applies to exact matches using $. In the example below, the URL /example.htm will be disallowed because the matching Disallow directive contains more characters:
Allow: /example.htm$
Disallow: */*example*htm
Broad matches are more powerful with a wildcard at the end
Another interesting side effect is that a broad match using a wildcard at the end becomes more powerful than one without, due to the additional character.
In the following example, the URL /example.htm will be disallowed because the Disallow directive contains more characters than the Allow directive (due to the additional * character):
Allow: /example
Disallow: /example*
If you use a wildcard for the matches, the outcome is undefined:
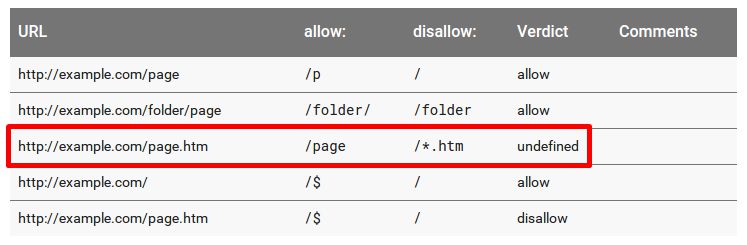
Google’s own robots.txt Testing tool reports these as allowed due to subtle differences in handling conflicting Allow/Disallow rules that are the same length.
However, Google’s John Mueller has stated that: “If the outcome is undefined, robots.txt evaluators may choose to either allow or disallow crawling. Because of that, it’s not recommended to rely on either outcome being used across the board.”
For more information, see the Google Developer guide to robots.txt specifications.
Disallowing and DeepCrawl: useful settings and reports
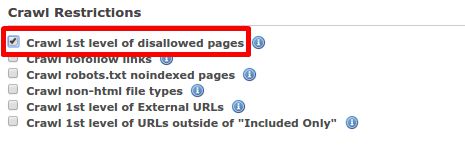
1. Crawl first level of disallowed pages (setting)
Check this option (under Advanced Settings > Crawl Restrictions) before running your report to crawl the first level of pages that are disallowed in your robots.txt file.
The pages will appear in the Disallowed Pages report instead of the Disallowed URLs report, with additional information on those pages, such as title tags.
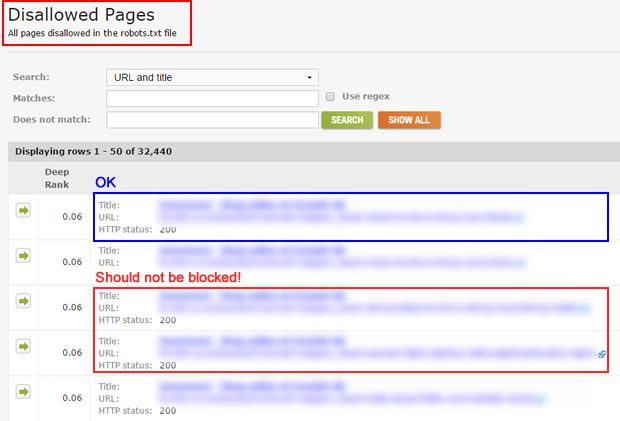
Leave this option unchecked to ensure no disallowed pages will be crawled or appear in any reports.
Find out how Glenn Gabe uses this feature in his guest post on Auditing URLs Being Blocked by robots.txt.
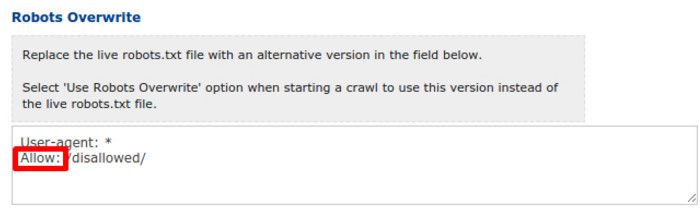
2. Robots.txt Overwrite feature (setting)
Crawl more than one level of disallowed URLs by pasting your robots.txt file directives into the Robots.txt Overwrite feature, and changing the Disallow directives for the URLs you want to crawl to Allow:
3. Disallowed URLs report
The Disallowed URLs report under Indexation > Uncrawled URLs contains all URLs that can’t be crawled because of a disallow rule in the robots.txt file.
Monitor robots.txt changes with Robotto
Use Robotto for free to monitor your robots.txt text files for changes and remind you to re-test a list of sample URLs in Search Console.
Controlling disallow directives in robots.txt: further reading
- Google Developers: Controlling Crawling and Indexing
- How to Audit URLs Being Blocked by robots.txt
- Managing robots.txt Changes with DeepCrawl and Search Console
- Noindex and Google: A Guide for Intermediate SEOs
- DeepCrawl technical SEO Library – Robots.txt
Don’t have a DeepCrawl account yet?
See our Disallowed Pages report in action along with our arsenal of other powerful features by requesting a live demo on a site you’re working on.



