


When auditing websites that have experienced a drop in rankings and organic search traffic, it’s important to have a good feel for indexation changes. Checking the Index Status report in Google Search Console and performing a site commands on specific directories can help provide a top-level feel for indexation, but the devil is in the details.
For example, if you see 250K pages indexed via Index Status, but you know there should be more, what can you do to double-check that number, dig into the data, etc? Knowing the number is a good thing, but truly understanding why it’s that number is another story.
The reality is that many business owners feel as if something could be wrong indexation-wise, but don’t know where to check or what to look for. For situations like this, one important area to analyze would be a website’s robots.txt file. It’s a simple text file that sits at the root of your site, but it sure can cause serious problems if the wrong directives are added.
For example, you could easily be blocking important files or directories from being crawled. And in a worst-case scenario, you could even block your entire site from being crawled. Don’t laugh, I’ve seen this happen before. It’s not pretty.
When Robots.txt Directives Turn Into Gremlins – Examples
Beyond simply blocking your entire site, there are other ramifications to using the wrong directives in a robots.txt file. I once audited a site that was blocking an entire section of content on an eCommerce site due to a greedy directive (by using a wildcard character incorrectly). The business owner was wondering why those 400 pages weren’t ranking for anything… Well, the pages weren’t even being crawled or indexed. Once indexed, you could see organic search traffic build quickly (traffic they should have been receiving for a long time).
And on the flip side, you can spike indexation by including flawed directives. One company I was helping released a test robots.txt file to production by accident. Some of the directives were incorrectly added, which led to a surge in thin content being crawled and indexed. The problem was caught relatively quickly, but issues like that can cause serious problems SEO-wise. And that’s especially the case with Pandas and Phantoms roaming the web.
DeepCrawl to the Rescue Via The Disallowed Pages Report
DeepCrawl is a powerful and versatile tool that I’ve written about before in several blog posts. There are many issues you can solve with DeepCrawl, and finding the wrong disallowed urls is one of them. Once you crawl your site, you can hop into the Indexation reports and click on Disallowed Pages.
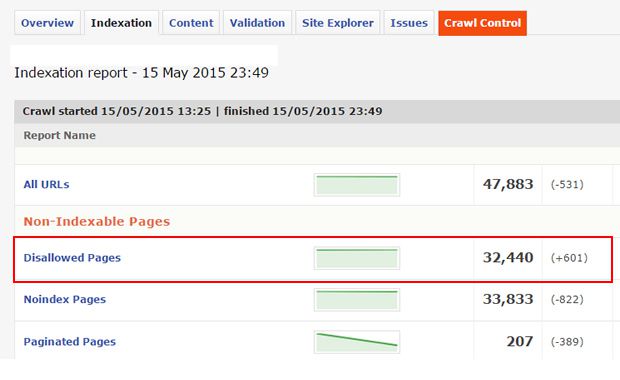
Important note: Make sure you have the correct settings checked in the “crawl restrictions” options in the advanced settings for the specific crawl. For example, make sure DeepCrawl can actually crawl disallowed pages (if you are looking to accurately understand which pages are being blocked.)
The report will show every url that was blocked by an instruction in your robots.txt file. You will also see where the url was linked to on the site (basically where DeepCrawl found the link to the url during the crawl).
As you scan the urls that were blocked, you will either feel very comfortable with your robots.txt file, or you might sink in your seat. For example, if you see thousands of urls blocked, and some shouldn’t be blocked, then you clearly have a problem with the directives in your robots.txt file. And by the way, it’s more common than you think to have the wrong instructions added to a robots.txt file. More about that soon.
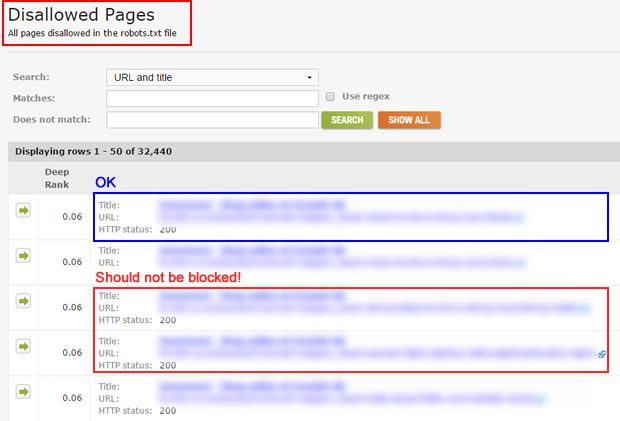
Auditing Disallowed Pages
There are a few ways to proceed at this point. First, you could start eyeballing the urls in the list to get a feel for what’s being blocked. This is a smart way to start your audit process. And you can search the urls as well by using the search functionality at the top of the report.
And if you’re comfortable with regular expressions, then feel free to use them as well. This can help you surface important pages that are being blocked. For example, if you’re an eCommerce retailer, you could find all urls containing the words “product”, “item”, and “sale” by using the following regular expression:
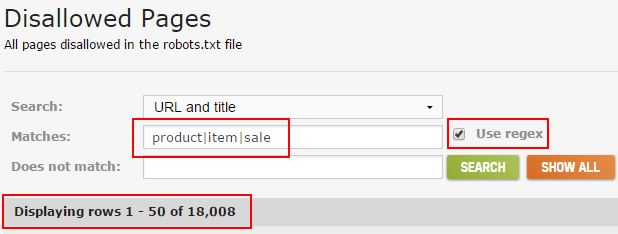
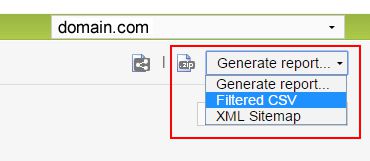
Once you dig into the urls being blocked, you can easily export that data via the “Downloaded CSV Zip” icon in the upper-right corner of the UI. And if you want to export the filtered list of URLs (based on using the search functionality I mentioned earlier), you can click “Generate Report” and then choose “Filtered CSV”. It’s a great way to isolate, and then export, specific urls for further analysis.
DeepCrawl + Google Search Console Testing
OK, now you have a list of urls being blocked by robots.txt and you want to dig deeper with the actual directives being used. Sometimes you can quickly see problems, like certain directories being blocked that shouldn’t be, but other times it’s not as easy to pick up the problems. That’s especially the case with more advanced robots.txt files that contain many directives.
A smart approach is to use the robots.txt Tester in Google Search Console. Google updated the tool last year, and it provides some great functionality. For example, you can see the latest version of your robots.txt file that was picked up by Googlebot, the header response code, you can view errors and warnings quickly in the interface, you can edit your robots.txt file for testing purposes, and you can easily test urls to see how they will be handled when crawled. That last piece of functionality is what we are looking for.
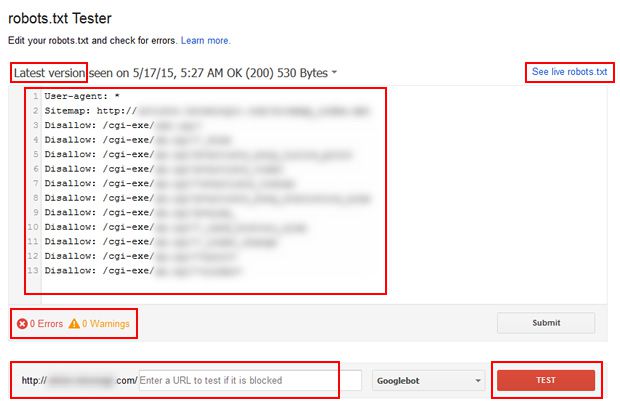
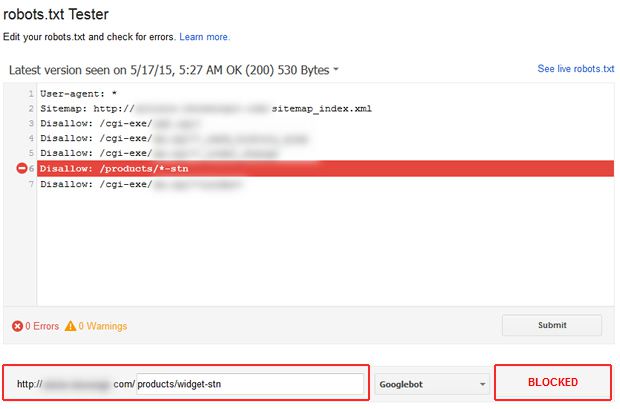
Access the urls that you exported from DeepCrawl and start picking urls to test in Google Search Console. Access the robots.txt Tester and enter the url in the text field. Then click “Test” to see if it will be allowed or disallowed. The tool will show a green “allowed” or a red “blocked” depending on the directives in your robots.txt file. In addition, the tool will highlight the directive that is blocking the url so you can dig deeper to ensure that directive is structured properly.
Greedy Wildcard Characters
One problem I’ve seen with urls being disallowed is the use of wildcard characters in robots.txt, and how they can be greedy. For example, you can use an asterisk (*) and dollar sign ($) to create advanced directives. An asterisk will match any set of characters and a dollar sign will signify the end of a url.
So, an instruction like the one below will match any urls that contain “_widget”.
Disallow: *_widget
While the following instruction will only match urls in the /apps/ directory that contain “_widget”:
Disallow: /apps/*_widget
Where the following instruction will only match urls in the /apps/ directory that end with “_widget”. The $ signifies the end of the url.
Disallow: /apps/*_widget$
As you can see, using wildcards can be both powerful and risky (if you aren’t comfortable with how they work and match urls). If you are using wildcards, you could be disallowing urls that shouldn’t be blocked. Using the robots.txt Tester in GWT is a great way to test urls, play around with directives, and ensure the proper directives are being used.
Tip: You can edit (or add) any instruction to your robots.txt file in the Tester tool to see which urls will be blocked versus allowed. The edits will not impact your actual robots.txt file. It’s essentially a sandbox for testing robots.txt directives. So edit away!
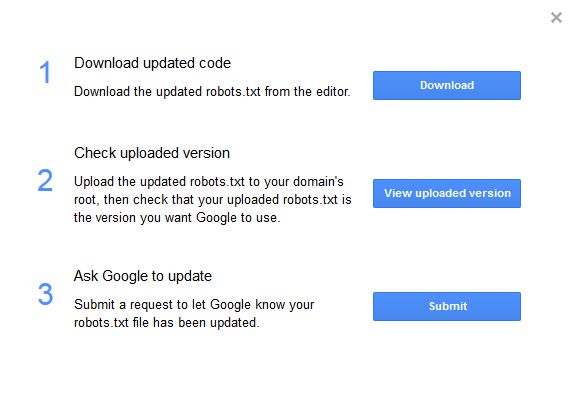
And when you are done editing and getting all of the directives working well, you can click the “Submit” button to download the new version of your robots.txt file. Then you can upload the new file to your site, and submit the file to Google (all through the robots.txt Tester tool in Google Search Console). Awesome.
Summary: Continuous Crawls Can Nip SEO Problems in the Bud
After going through this post, my hope is that you can see how important it is to audit and analyze your robots.txt file. Again, it’s simple, yet can be dangerous if not structured properly. So if you are questioning whether some urls are being blocked by robots.txt, then I would use the process I listed above to double-check your own directives.
By crawling your site via DeepCrawl and then using the robots.txt Tester in Google Search Console to audit your directives, you can rest assured that everything is working as expected. And if you find problems, you can quickly fix them, and upload your new robots.txt file. So crawl away. 🙂
Glenn Gabe is a member of the DeepCrawl Customer Advisory Board



