
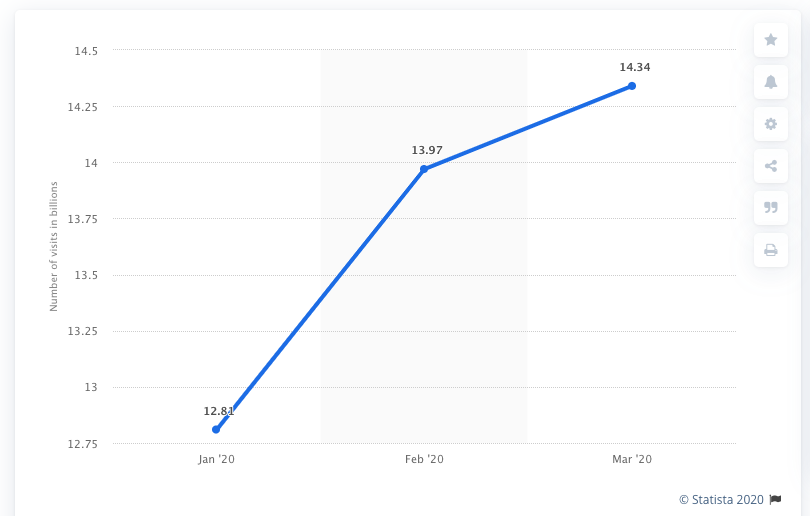
In 2019 alone, eCommerce sales accounted for 14% of all retail sales worldwide and this has continued to increase into 2020. The habits of consumers has also been forced to change over the last few months, and this is reflected in the large traffic increases eCommerce websites have experienced. In fact, the number of visitors to eCommerce sites rose by almost 2 billion between January and March 2020, from 12.81 billion visitors to 14.34 billion globally.
With this increasing demand for online stores likely to continue, the need for a well-performing eCommerce website has never been greater. However, we understand that due to their size and complexity, eCommerce websites are also some of the hardest to optimise and they face challenges unique to the typical SEO issues seen across the web.
In order to identify the common SEO issues faced by eCommerce sites, we have analysed a number of crawls from large eCommerce websites and used our technical SEO experience to highlight how to identify and fix these problems.
Expired products
Products naturally expire and the pages are typically removed, however, these product pages are often those which generate the most backlinks, more than product listing pages. Redirecting them to a relevant alternative product can be difficult to scale, and redirecting to a relevant category page can also be difficult to configure and maintain.
Often these pages will just be removed and return a 404 status, which will lead to them losing any backlinks gained, or they are redirected to a generic page such as the home page. This provides a poor user experience and may mean a potential customer ends up purchasing from a competitor’s site instead. These pages are also likely to lose any backlink authority gained, which could affect other internally linked pages, as well as the site as a whole.
How to identify expired products
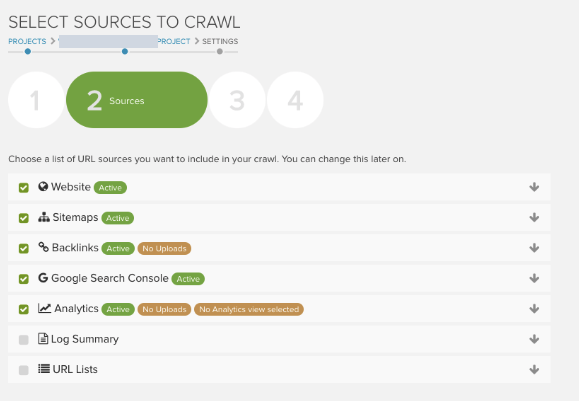
The best way to identify these pages is by crawling old product URLs, URLs with backlinks, or Google Search Console with a long date range, and see if they return a 404 or redirect. You can do this within DeepCrawl by configuring the additional crawl settings to include your Google Analytics and Google Search Console accounts, along with our Majestic integration. Once the crawl has completed you will be able to identify these pages within the indexation reports.
How to fix this issue
If you come across this issue within your crawl, the best approach to take is to redirect the pages to the most relevant alternative product or product listings page. It is best to prioritise the pages which have the most backlinks and are generating a large amount of traffic. You can also work with your development team to engineer the platform to ensure this happens immediately when products are no longer available.
Multiple URL routes/parameters
Product details pages can sometimes be reached through multiple URL formats, for example, parameters or values. If these pages are not correctly canonicalised, and linked internally it can result in duplication. Content duplication can lead to cannibalisation with pages in search results, where multiple pages from the same site are competing for the same keywords. This could lead to your key pages never being found by users, or may direct them to a less relevant page.
Allowing search engines to crawl multiple versions of the same page can have a big impact on a site’s crawl efficiency, while also diluting signals across the different versions of the page. This limits the performance of the whole site and can lead to confusion for both search engine bots and users. This could also impact and potentially waste your crawl budget, particularly if you have a large site, as search engines are crawling the same content multiple times.
Find out more about duplicate content, and how search engines deal with duplicate pages in our guide to duplicate content.
How to identify multiple URL routes
Identifying duplicate content can be a good starting point for finding issues that may arise due to multiple URL parameters, and there are several reports available within DeepCrawl to identify these such as Duplicate Content Sets, Duplicate Titles and Duplicate Descriptions. It is also important to understand the canonical structure of the site and ensure these are set up correctly, as well as included in the sitemap and internal linking across the site.
How to fix this issue
There are a couple of different solutions for this issue. The preferred version for both search engines and users is to ensure canonical tags are pointing to the preferred format and this preferred format is used within sitemaps, and in internal links.
You can also set a 301 redirect from the duplicate URL to the preferred page. This will prevent duplicate pages from competing with each other in the search results, as well as help to consolidate signals for search engines. However, as search engines will have to crawl each page in order to identify the redirect, this method will not solve crawl budget issues. You also want to ensure a redirect chain isn’t created as this can impact a page’s discoverability for search engine crawlers.
Multi-facet selection
Many sites allow users to select multiple facets at the same time, which usually produces a disproportionately large number of selection options. However, this can create pages which are not targeting any relevant search queries, rendering the pages unnecessary for SEO. Even if the pages are managed with noindex and nofollow tags, this may still result in wasted crawl budget.

How to identify multi-facet selection pages
The first step to finding these pages is to identify the URL pattern used for multiple facet selection. These URLs will typically include parameter handling characters such as ? or # and query strings, but may also sit at the folder level following a forward slash. Once these have been identified you can then look for these URLs in crawls and find the pages which are indexable with followed links, as well as those with search impressions from GSC.
How to fix this issue
In order to overcome this issue, ensure canonical tags are used to inform Google of the preferred version and make sure links to these multiple facet pages are nofollowed and the pages themselves are noindexed. This will prevent the pages from being included in Google’s index, as well as help search engines further understand the canonical URL.
You may also consider disallowing the URLs in the robots.txt completely to stop search engine crawlers from accessing, crawling and ultimately indexing them. This solution is useful for crawl budget issues, but you will need to ensure that other pages linked internally from the faceted pages are able to be accessed via other crawlable pages. Otherwise, the other pages will be inaccessible by search engines.
Ineffective link architecture
Product pages may be contained deep within a website, over 4 or 5 clicks from the homepage. If the website is a large eCommerce site, for example, these pages may never be found or crawled by Google and therefore never indexed. This means that your page will not be found when a user searches for a product you are offering, leading them to instead visit and potentially purchase from a competing site. The internal link authority for these pages is also considered to be lower, which can in turn affect other pages internally linked across the site.
How to identify ineffective link architecture
Within DeepCrawl you are able to identify the click depth of the website and review the pages which are buried deep within the site. Every page discovered within the crawl which is linked directly from the starting page is considered level 2, and so on, meaning the level of the pages identified is the shortest distance it can be reached through internal linking from the starting page.
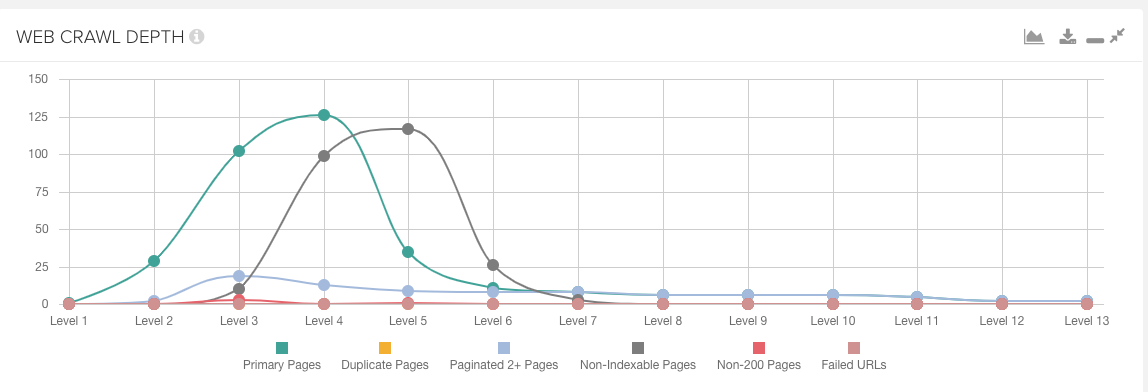
You can also review priority pages to find their depth, the number of internal links they currently have, and where these links are coming from.
How to fix link architecture issues
If there are key product pages beyond 4 clicks from the homepage, ensure relevant internal links are set up on more prominent pages in order to decrease the number of clicks required to reach them. For priority pages you can also review where on the site other relevant internal links can be added to ensure these pages are more prominent and clear for both users and search engines.
Ideas for internal linking may be; ‘related products’, ‘customers also like’, ‘complementing products’, as well as sections on the site for new releases and products on sale.

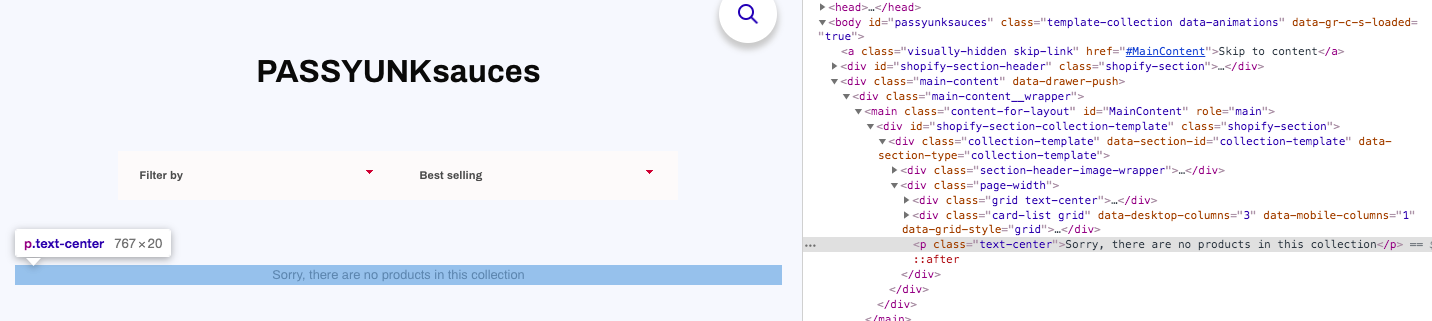
Product listing page churn
Listings pages may change frequently from having products to not having products, as the stock changes. If you have empty pages with no products, this could provide a poor user experience and may also be considered a soft 404, which could lead to a potential loss in rankings.
How to identify empty product listing pages
One way to identify product listing pages which are empty is by setting up a custom extraction for a product count/no products error message. Adding this to your monitoring crawl will allow you to be alerted each time an empty product listing page is discovered. You can also crawl these URLs with the GSC source to identify those with search impressions, as well as those linked internally.
Our guide to custom extraction further explains how to use a DeepCrawl custom extraction to identify these pages, using a simple regex pattern.
How to fix empty product listing pages issues
Consider noindexing pages with less than ‘n’ products automatically, and removing the noindex when above ‘n’ or more products is shown.
Indexing internal search pages
Internal search pages may be used deliberately to cover additional niches not included within the primary taxonomy, facets, and filters. However, this can result in a very large number of additional URLs, which are competing with other pages if not carefully curated. These pages may also bloat your site and affect your crawl budget, as Google is effectively crawling an infinite number of possible internal searches.
How to identify indexable internal search pages
In order to discover any indexable search result pages you may have, first you need to identify the URL format for internal search, these are typically using a query parameter such as ?q or ?s. You can then use a crawl to identify how many of these pages are indexable on your site, as well as GSC data to see how many are generating impressions.

How to fix indexable internal search pages issues
There are several solutions to this issue, firstly you will want to check your GSC keywords to see if there is an overlap of rankings for the same keyword and identify if search results pages are contained within these. If there is high search demand for a query, you may also consider creating a specific page for these products, to prevent the need for indexable search pages.
One way to prevent these from being indexed is by adding noindex, nofollow tags to inform search engine crawlers that these pages should not be included within their index. You could also disallow these pages completely within the robots.txt file to prevent search engine crawlers from accessing or crawling them. This will help with any issues you may have with crawl budget.
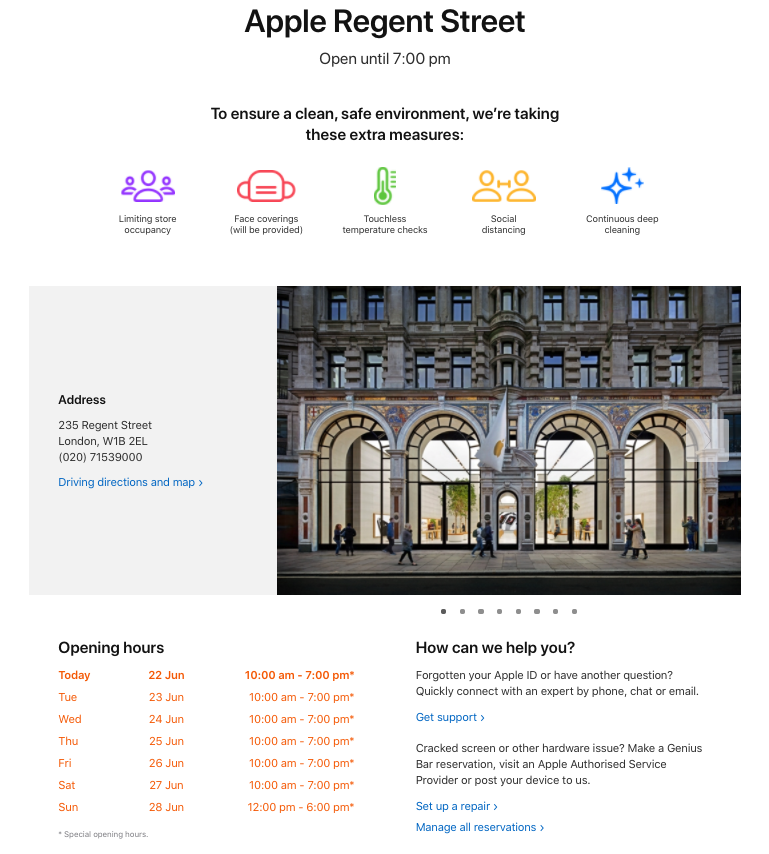
Ignoring location pages
Ecommerce websites with physical locations often ignore their location pages. Many times location pages aren’t found in crawls of eCommerce sites with locations because they are dynamically generated based on user input (zip code, for example) and aren’t in sitemaps. Alternatively, there may be one location page with a list of every single location. Other times, there are pages accessible, but they are not helpful to users, or they exist and have some helpful content, but internal linking opportunities are completely missed.
This means the business doesn’t rank as well in the local pack and misses out on in-store purchases.
How to identify location pages opportunities
The easiest way to review these pages is to check the location pages manually on the website. You can ask questions such as; does it need user input to populate with data? Are there internal links? Is the page actually helpful to users?
You can also run a crawl to check if location pages are able to be found and review your sitemaps to ensure they are contained within those, as well as GSC to identify if your location pages are being indexed.
Poor Example

Good Example
How to fix this issue
Create location pages with unique URLs that are linked to within the website – you should also include these location page URLs in your sitemap. These pages should contain important details for users such as an address, phone number, hours, services, etc. If you have reviews for the specific location you should also add these, along with LocalBusiness schema markup.
Poor content quality
A common challenge across eCommerce sites is making sure content is unique and useful for customers, particularly on product pages. Most eCommerce sites copy the product details from the manufacturer, which is not unique and provides no useful information. These pages can, therefore, be deemed as low quality, which can negatively impact their authority within search results. It can be hard to identify this at an enterprise level, due to the number of pages and the automated approach usually taken to create them.
Google may penalise the pages or even the whole site if it deems it to be low quality. In addition, there is a lot of competition in search results for eCommerce sites who sell the same products. Ensuring your pages provide more information than your competitors could be the difference between the position it gains in SERPs, and the number of sales achieved. You also need to think of the user first and the action you would like them to take – if they do not feel the page is engaging and it doesn’t tell them much about the product and why they should buy it, they probably won’t convert.
How to identify content quality issues
In order to identify pages which may be deemed as low quality, you can review the duplicate and thin content reports within DeepCrawl. These reports will display the URLs which may have some content quality issues and allow you to find similar pages across the site.
How to fix content quality issues
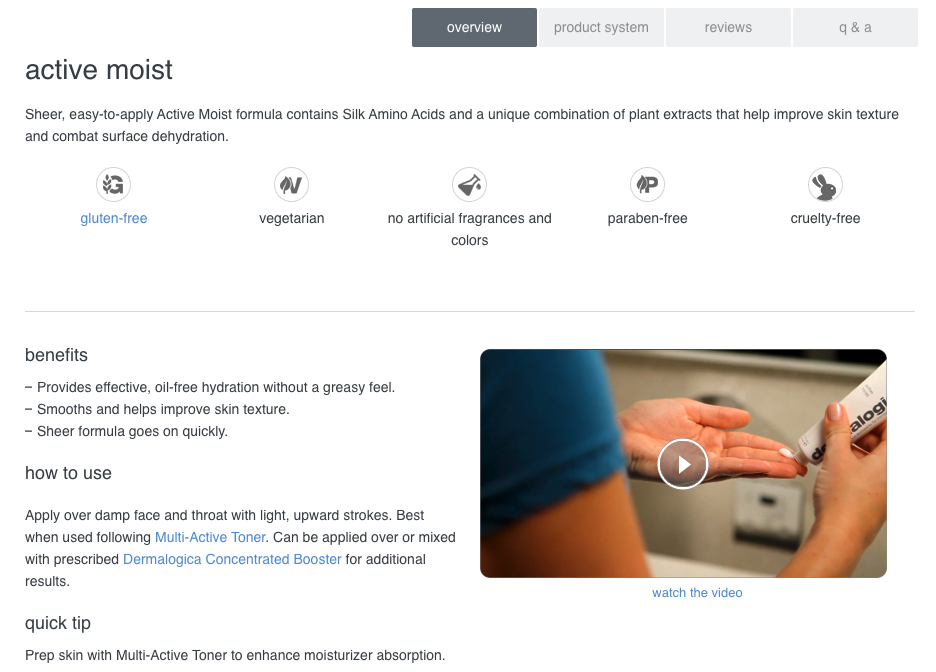
It is common SEO best practice to ensure every page on a website has useful content, such as ‘benefits of the product’ and ‘how to use the product’, together with supporting images and videos if available.
These are just a handful of common SEO issues we see affecting eCommerce websites, particularly as their traffic level, product demand and competition increases. In order to achieve success in search results, as well as gain and retain loyal customers, it is imperative to ensure your website is easily accessible, provides a good user experience and a clear journey to complete the desired goal.
In addition, if your competitors are regularly monitoring their website, fixing issues that arise and continually optimising their site, they could not only be outranking you in search results, but also driving a higher amount of traffic and ultimately conversions, potentially taking customers away from your website.
Identifying issues that will have the biggest impact on both search engines and users, while also positively impacting the overall business KPIs is essential for success. We hope this post has provided you with a starting point to identifying these issues, along with some ways to solve them, but please do not hesitate to get in touch if you have any specific questions on this topic.
How Does DeepCrawl Help eCommerce SEOs?
We work with many of the world’s largest eCommerce and retail brands to understand the issues that these sites often run into when being optimized for organic search. DeepCrawl is the perfect companion to assist you in overcoming the issues mentioned in this post, together with the unique issues your website may face.
To find out more about how DeepCrawl can help make your job easier, as well as access the reports we mentioned within the post, submit a request for a bespoke package and one of our team will be happy to discuss a plan with you that will meet your specific needs.


