

Before we start, please note that if you are very familiar with DeepCrawl, then this article may be too basic for you. I wrote this article for people who have just started to use DeepCrawl and for those who want to use it for different issues.

Let’s begin. As digital marketers, we love technical analysis, right? It makes us intrinsically happy to see the rise of organic traffic in Google after locating the source of problems and solving them like a puzzle. DeepCrawl is an essential tool for that technical analysis. It helps us to better understand the sources of problems in our websites by analyzing hundreds of thousands of pages for us. DeepCrawl’s comprehensive capability has made it one of the most essential tools in digital marketing.
While there are a variety of tools and methods available for solving website issues, DeepCrawl is the quickest and easiest way to strategize and solve common problems on a daily basis. Here I’ll address 14 common SEO issues that you can easily overcome using DeepCrawl:
1. Moving to a new website / URL structure
Moving a website is one of the most tedious things to do. I know a lot of brands that have lost their organic traffic because they did not manage the transition correctly. Whether you are moving your site to a new infrastructure or changing your URL structure, DeepCrawl will make the transition easier.
There are several ways to employ DeepCrawl when moving a website:
- List your old URLs in your website and import them into DeepCrawl with the List Crawl option. Make sure they are directed to the new URL structure correctly. Before making the transition, use DeepCrawl to detect any problems in your old pages.
- If all of your URLs are in your Sitemap file, you can use the Sitemap Crawl option to import your sitemap files and get information about your old URLs. If your new URLs are closed to Google, you can use Test Site Basic Authentication in advanced settings to find any errors before publishing. You can solve critical problems – like ensuring all URLs are 301 directed correctly, synchronizing any duplicate content and making sure no pages give a 4xx error – before publishing.
- Do not forget to export the pages that receive the most organic traffic. Export the pages with the most impressions and clicks via Google Search Console and upload this list to DeepCrawl using the List Crawl option to correct any errors before or after transition.
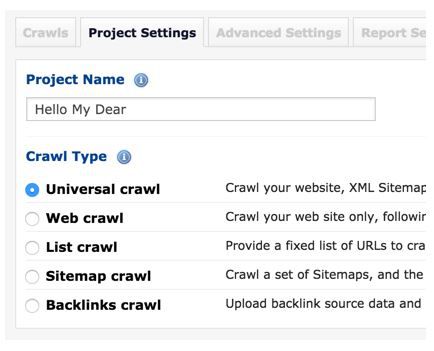
By entering the URL of your staging site in the Test Site Domain field in Advanced Settings, you will be able to clearly see any errors in your report.
2. When organic traffic is low
Sometimes organic traffic begins to drop and we cannot seem to fix it, no matter what we do. Sometimes a decline in traffic is out of our control. But if a dip in organic traffic is due to a technical issue, DeepCrawl can easily detect and solve the problem.
Ok, but how?
Using Google Analytics, or the analytics tool of your choice, choose the dates before traffic began to drop. Export and then upload that information to DeepCrawl using the List Crawl option. Then check for any changes that you hadn’t previously noticed.
Similarly, you should examine the pages with the most impressions before and after a spike in traffic using Google Search Console. Data collected from Google Search Console can help supplement data findings from Google Analytics, and it’s important not to rely on the insights gained from Google Analytics alone.
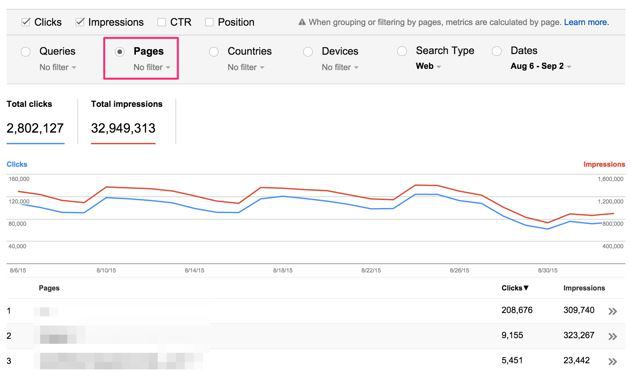
Lastly, we should export the pages with the most backlinks using backlink sources like Majestic or Ahrefs to check for any significant technical changes. I’ve worked with a client who saw 404 errors appearing on the pages that had the most backlinks and, after a while, they lost their position on high-volume keywords and their organic traffic started to decline.
3. Publishing a mobile website / interface
In a statement in April, Google said that websites without a mobile presence or mobile-friendly interface might lose their mobile ranking position.
The change essentially requires agencies to be more thorough before publishing a client’s mobile interface. That’s where DeepCrawl comes in. If you choose Google’s mobile agent in Advanced Settings, you can scan for possible errors prior to publishing.
For example: how can you be sure that your most important pages aren’t returning 404 errors to a mobile user-agent without testing? Or how can you be sure that you’re giving the canonical value that is your web version to the bots that come to your website with a mobile user-agent? By using DeepCrawl you can answer these questions before publishing the mobile interface. Nice, isn’t it?
Another benefit with DeepCrawl is that you can scan any mobile interface by choosing mobile as your device under Search Analytics in Search Console.
4. Analyzing your pages’ rankings based on your competitors’ words and positions
This is one of my favorite DeepCrawl features. By exporting the high-ranking pages of your competitors, you can determine the specific keywords they are benefiting from. There are many tools for this, but I use a link research tool called the SERP Research Tool. You can locate your competitors’ pages by using tools like SEMrush.
Using specific keywords, you can analyze your competitors’ pages to better understand what they are doing differently. To take it a step further, you can add link metrics and social share data to the analysis. By comparing your keywords to your competitors’, you add another level of insight to your SEO.
5. Detecting URLs that do not exist in your Sitemap file
Sitemap files ensure that search engines are able to crawl a website faster and easier, thus allowing the site to be indexed. But how do you detect and add the pages that do not exist in our Sitemap file? To add pages to an existing sitemap using DeepCrawl, choose the Universal Crawl option and enter the URL of your Sitemap when starting the scan. Then you’ll be able to find and export the URLs that are missing from your Sitemap file.
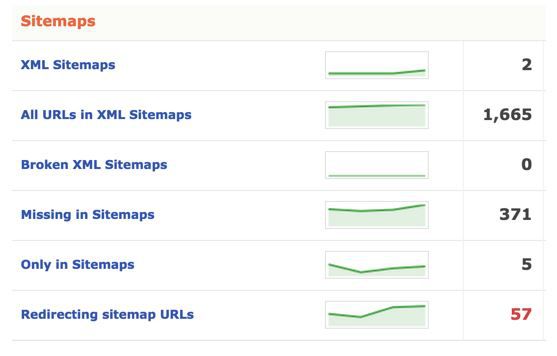
6. Detecting old redirected URLs in your Sitemap file
A search engine’s ability to scan your website is limited. So if you use this knowledge to your advantage, you can gain an edge over your competitors. One way to do this is with redirected URLs. If old redirected URLs remain in your Sitemap file for a long period of time, they will have a negative effect on your SEO performance.
With DeepCrawl, you can detect the redirected URLs in your Sitemap files and manage them more effectively. To do this, choose the Universal Crawl option when starting a project. Then click on the Redirecting Sitemap URLs section when the scan is over to learn more about where the URLs are redirecting to.

7. Detecting duplicate pages and content
If the website you are optimizing has thousands of pages, duplicate content becomes boring and tedious for the consumer. It is almost impossible to manually detect duplicate pages among thousands of pages. But using DeepCrawl’s advanced duplicate content algorithm, digital marketers can get rid of the duplicate content that search engines avoid.
To prevent duplicate content, adjust your resemblance ratio in Duplicate Precision under Report Settings before starting your project. There are two ways to see the results:
- In the Duplicate Pages section under the Indexable Pages tab.
- In the Duplicate Body Content section under the Content tab.
8. Checking pixel length of long page titles
Remember to control the pixel length of title and description metas. If these exceed the allotted word/pixel count, Google will place ellipses where the rest of your text should be in the search results.

You can use DeepCrawl to check that titles and descriptions adhere to the sentence length allotted by search engines by implementing both word and pixel controls so that search engines won’t look for the rest of the sentence. Select mobile user-agent to detect the pages that cross the pixel limit in mobile results.
9. Detecting pages with little content
The content we create has to be a specific length to gain a position in search results. We cannot expect a website to be ranked on the first page if we only write one paragraph and then publish it using competitive keywords. SERPIQ shows that it is easier for longer content to rise in page rankings:
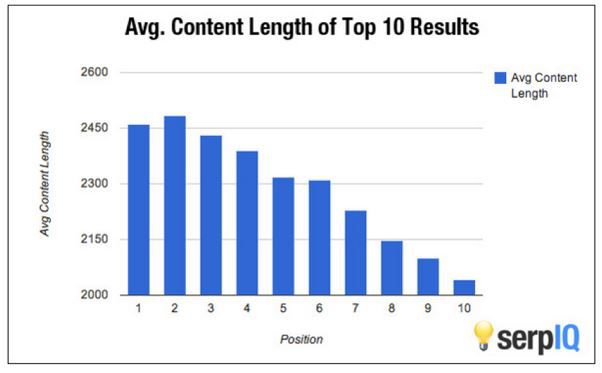
DeepCrawl analyzes the scanned pages, calculates content ratio and shows you the pages with low word counts. If you want these pages to gain position on the first page of search results, you will need to write longer content. To determine which pages would benefit from an increase in content length, check the Min Content/HTML Ratio section under the Validation tab.
10. Following exit links
If you have hundreds of thousands of pages and editors are creating most of the content, you may be giving links to several other websites without realizing it. While giving links to other websites can be useful, using thousands of links that are not nofollow exit links can have a negative impact on your SEO performance.
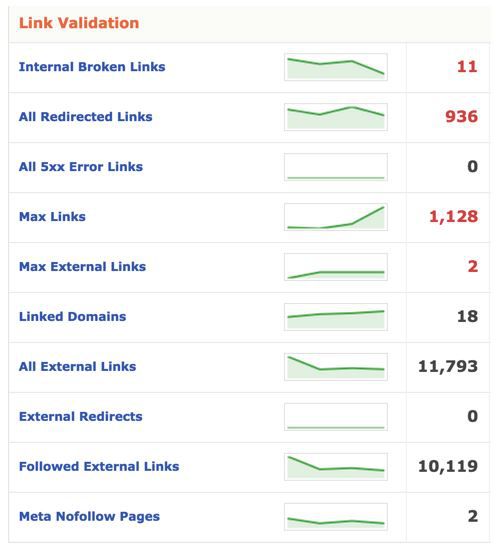
I came across this issue with one of the companies I was consulting for. The company let every member add their own website to their profile pages. Everybody was looking for ways to attach personal links to their company’s website since its Google value was high. When addressing the problem, we realized that private SEO software created automatic profile pages for the website and gave it exit links. Most importantly, these links were nofollowed. With DeepCrawl, we were able to detect these pages, remove all the links and prevent the drop in SEO performance.
To review your exit links, check the All External Links section in the Validation tab.
11. Detecting non-canonical pages
We SEOs like to be in control of a lot things, don’t we? That becomes more difficult when we’re dealing with duplicates. If the page you are trying to optimize has non-canonical pages, then you have a high risk of creating duplicate content. Without realizing it, the parameter links that are given to your non-canonical pages from any site will be indexed by search engines and will be duplicated with your page. For example, let’s say we have a URL like this: www.example.com/product-a/ and there is no canonical meta on this page:
www.example.com/product-a/?utm_source=google&utm_medium=text&utm_campaign=product
In this case, if there is a backlink pointing at the second page, then search engines will follow this URL and crawl the page so they may perceive it as a different page and index it accordingly. And this means duplicate content, which is a negative factor for our SEO performance.
For example, if there are 96,000 pages that are indexed like this, then you have almost 96,000 duplicates because there is no canonical meta on these pages:
https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=inurl:%3Futm_source%3Dgoogle
With DeepCrawl we can detect the pages that do not have canonical and fix them.
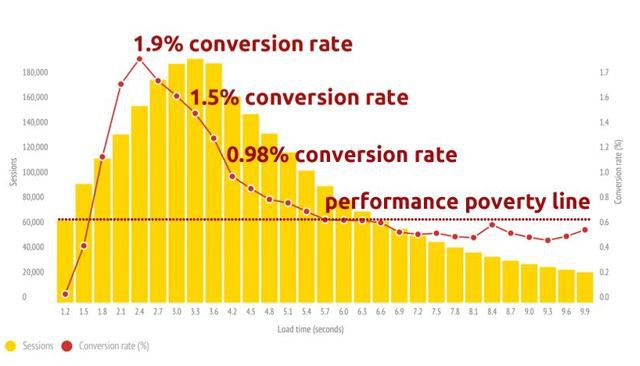
12. Detecting slow pages
In 2010, Google stated that website and page load speed had a direct effect on rankings. Since then Google has fought to banish painfully slow websites. Recently, Google has even considered implementing a slow icon in search results to warn users that they may have a poor experience on the page.
While there are many tools (including Google Page Speed, GTmetrix, Pingdom page speed) that may be helpful in speeding up slow sites, you must first determine the source of the problem before you can fix it. DeepCrawl is one of the best ways to find out what is causing a website to be so slow. DeepCrawl filters the slow loading pages in the Max Load Time section under the Validation tab. This way you can spend your time getting to the root of the problem, instead of trying to find it.
13. Boosting traffic from social media
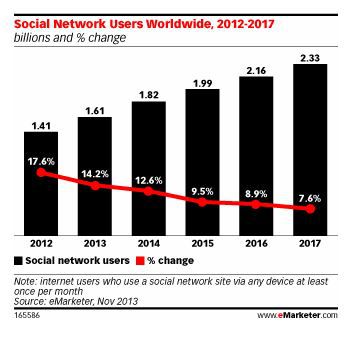
Facebook and Twitter are the biggest platforms for directing new traffic to a website, but it’s important to optimize these pages with Open Graph tags and Twitter Cards. By using Facebook and Twitter tags, you can fix possible errors and optimize content by ensuring that users are seeing your images, headlines and descriptions in the most appealing way, which should increase CTR.
To check for missing social tags using DeepCrawl, check the Content tab in the Social Tagging section.
BONUS
If you haven’t tried Fetch as Google yet, you should read more here.
Fetch as Google will allow you to easily see how search engines view your pages with different user-agents such as Applebot, and from different country IP addresses. You can also use Fetch to see which HTTP code your page is returning and to determine whether or not it will be indexed.
You can share in the comments the parts that you don’t understand. In which situations do you use DeepCrawl other than these scenarios?
If you have questions, or like talking about SEO, you can reach Ilyas on Twitter at @ilyasteker.



