The Finer Details of DeepCrawl (now Lumar): 20 Features You May Have Missed
This post first appeared as an article by Fili Wiese on State of Digital. Fili Wiese is a leading SEO expert and an esteemed member of the DeepCrawl Customer Advisory Board.
Getting technical SEO and performance right for websites can be a difficult task, especially if you don’t have the right tools in place to diagnose issues and monitor progress.
DeepCrawl is one of my favourite tools and DeepCrawl’s capabilities are well-known so I’d like to take you through some of the lesser known functions and features so you can get more insights out of your crawls.
Crawl Settings:
Let’s start by taking a look at some of the settings you can configure as part of the crawl process.
1. JavaScript Rendered Crawling
With DeepCrawl’s Rendered Crawling release, you can now crawl the rendered version of pages. This is massively useful for understanding JavaScript sites which inject links and content into the DOM.
You can easily enable rendering in a crawl in the first stage of the setup and what I also like is that you can inject custom JavaScripts for additional analysis including page speed metrics (which we’ll come onto later).
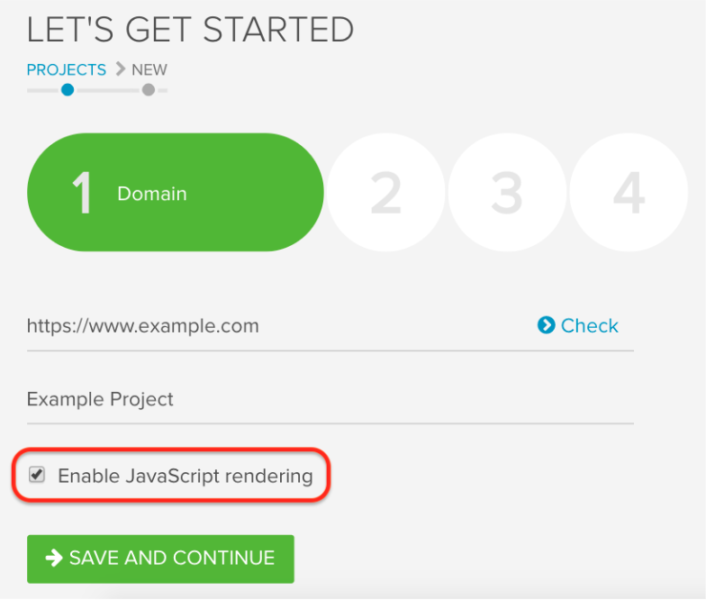
When crawling JavaScript sites, I’d recommend setting up two crawls with rendering enabled and disabled, so you can see what Google sees before they render the page.
2. Majestic backlink metrics
Another addition to the DeepCrawl platform is their integration with Majestic which automatically brings in backlink metrics for your URLs. Adding Majestic to a crawl is easily done in the second step of the crawl setup and you can even choose if you want to import backlink data from their Fresh or Historic index.
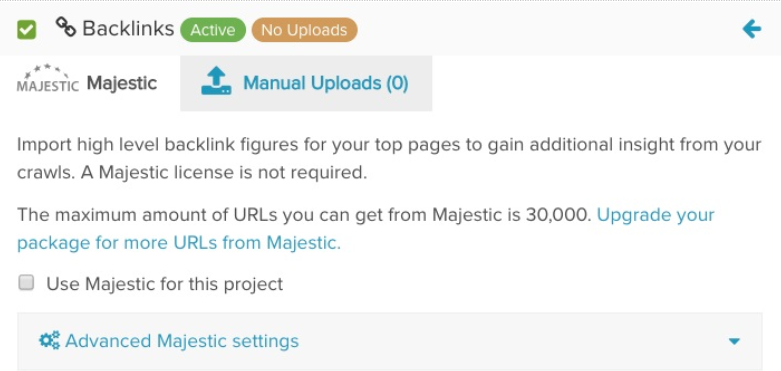
Adding Majestic backlink metrics to a crawl will allow you uncover and fix issues like orphaned pages with backlinks as well as backlinked pages which have become broken, disallowed or have started to redirect.
3. 16 months of Search Console Data
Since Google updated their API a few months back, DeepCrawl is now able to integrate 16 month’s worth of Search Analytics data from Search Console. All you need to do to set bring this SERP data into a crawl is configure the GSC integration in the second step of the crawl setup, making sure to enter 486 days into the date range field.
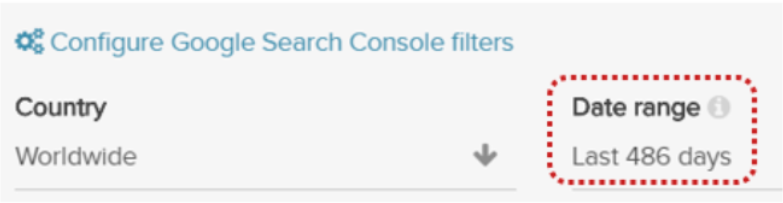
With Search Console data integrated, you can use DeepCrawl’s reporting to find lots of insights by looking at the interaction between indexability and traffic including: indexable pages without search impressions, non-indexable pages with search impressions and broken pages with traffic.
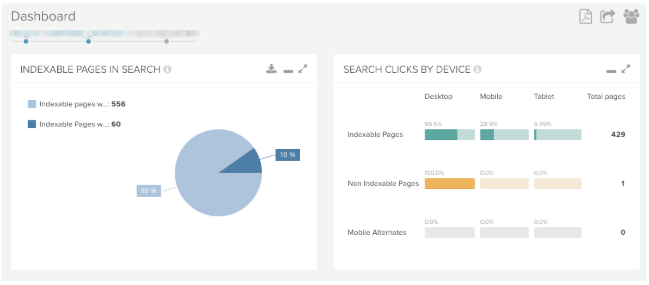
4. Separate Mobile User-Agent
With the gradual roll-out of mobile-first indexing it is ever-more important for SEOs to understand how Google sees your site when crawling with Googlebot smartphone. If you are auditing a separate mobile site, this can be impractical as you might need to run two different crawls with a mobile and desktop user-agent.
DeepCrawl has a neat feature which allows you to add a separate mobile user-agent so you can crawl a desktop and separate mobile site within the same crawl.
5. Crawl Like Googlebot
Staying on the subject of understanding how Googlebot crawls a site, it is important to understand the route that it takes when crawling through a site. Googlebot will likely only crawl from a site’s homepage the first time it is discovered, after that you will need to look at the site’s server logs to understand what is being crawled.
In DeepCrawl you can crawl a list of URLs, which is handy because it means you can extract the pages Googlebot is crawling from your log files and then crawl that as a list, so you can see what Google sees.
6. Changing thresholds
Right at the bottom of the advanced settings you can find the report settings section which allows you to override the default thresholds set for various reports.You may want to edit things like maximum and minimum title and meta descriptions widths, thin and duplicate page thresholds and maximum number of links depending on the requirements of the site that you are auditing.
7. Restrict Crawling at Peak Periods
One final crawl setting hidden away in DeepCrawl’s set up is the ability to set crawl rate limits. Of course you can set a maximum crawl rate but you may want to limit this at specific times and/or days during peak times.
By setting crawl rate restrictions you can avoid putting unnecessary strain on your site’s servers when your site is getting its highest levels of traffic.
Custom Extractions:
Part of DeepCrawl’s power lies in its ability to set custom rules using regex to extract key information from the pages on your site. Here are examples of just a few of the useful custom extractions you can use to uncover insights.
8. Validating tracking set up
The custom extraction section can be found in DeepCrawl’s advanced settings and includes several preset options ready to go straight out of the box. One such preset is the ability to extract tracking codes from Google Analytics and Tag Manager.
![]()
By running a full site crawl with this enabled, you can make sure your unique GA and Tag Manager code snippets are present on every single page so you can rest assured that your website traffic and customer onsite browsing behaviour is being tracked.
9. Extracting image tags
Another preset custom extraction available in DeepCrawl is one to detect missing image alt tags. Search engines are currently limited in the information they can extract from images, so it is imperative that site’s ensure that site’s give whatever information they can.
Running a missing alt tag extraction will allow you to determine which pages have images where alt tags need to be added so you can help Google and other search engines better understand them and improve your chances of receiving traffic from image search.
10. Auditing product pages
Custom extractions are particularly useful for ecommerce sites in auditing their product pages.
Here are a few things you can extract:
- Pages with out of stock products to track the number of these pages that exist and if they are receiving clicks and impressions from GSC.
- No. products in a category page to understand the volume of pages with few or no products contained within them.
- Product Price
- Product Serial Numbers / SKUs
- Category Codes
- Product Dimensions & Sizes
- Delivery Estimates
11. Validating markup
Finally on the subject of custom extractions, DeepCrawl can pull out markup in a variety of forms so you can understand and optimise its implementation on a site and improve the chances of appearing in rich snippets.
Here are some examples of markup you could potentially pull out with custom extractions:
- Review schema (individual or aggregated) to get a better understanding of product popularity.
- Breadcrumbs to aid with analysis of a site’s taxonomy. You’ll need to include the “itemListElement” property as a part of your regex query.
- Organisation schema, product schema and more!
Automation:
What has particularly impressed me about DeepCrawl over the past year or so is there eagerness to integrate with different tools and provide their data within different platforms. At the heart of this initiative is an integration with Zapier which allows you to trigger crawls from outside of their UI and send crawl data to other platforms when it has completed.
Here are some of the best use cases:
12. Triggering crawls
With DeepCrawl’s Zapier integration, it is easy to trigger a crawl from any of platforms Zapier partners with. For example, you could use a recurring meeting in Google Calendar or a message in Slack to trigger a crawl in a way that is more convenient than having to login into DeepCrawl directly.
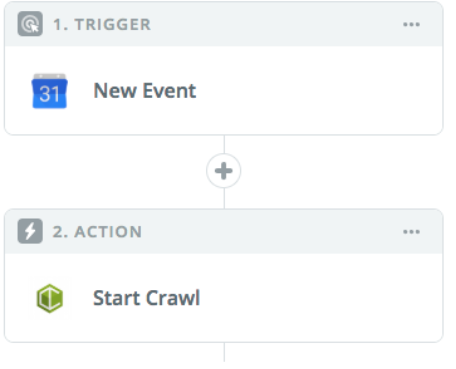
13. Crawl completion notifications
Once a crawl has completed you can use that to a trigger a notification in a way that is convenient for you. For example, you can trigger a notification to be sent to a Slack channel with any of the crawl metric counts you’re interested in, like number of indexable pages.
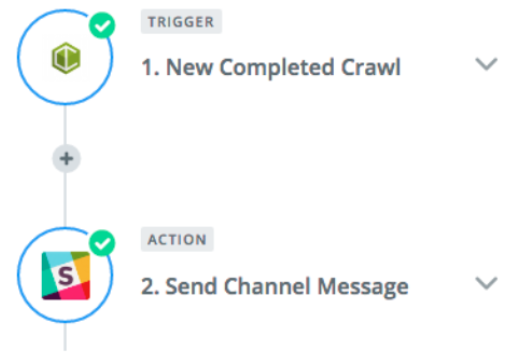
Combined with the previous use case you could trigger a crawl within Slack and have a notification and top level crawl metrics returned within that same channel.
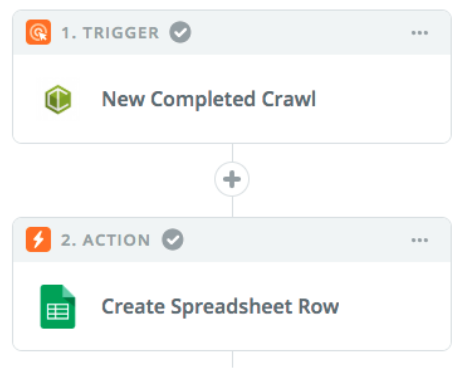
14. Automated Crawl Data in Google Sheets
Another option, is to set up a zap which populates a row in Google Sheets with crawl metrics. After a number of crawls this would give you a historic view of crawl data and the ability track trends across time. Pulling crawl data into Google Sheets can also form part of a data warehouse which can use to populate graphs and charts in data visualisation platforms.
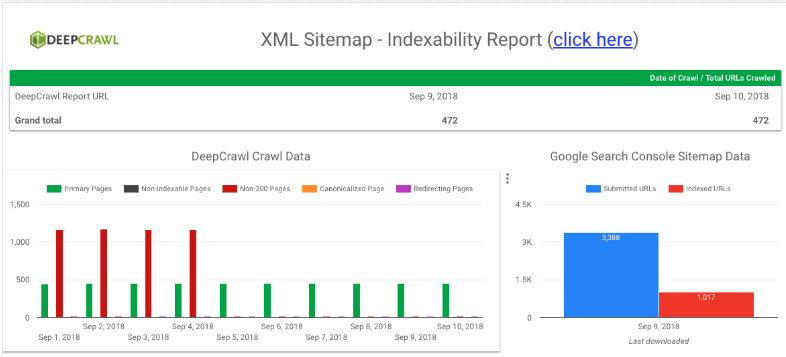
15. DeepCrawl Metrics in Google Data Studio
Following on from the previous use case, once you’ve got an automated flow of DeepCrawl data into Sheets you can then pull that data into dashboards in Google Data Studio.
All you need to do at this point is configure the Google Sheets connector in Data Studio to pull in your crawl data, then you can manipulate it into any manner of visualisations to fit your needs. You can even combine DeepCrawl metrics with data from Google Search Console, as shown in the example XML Sitemap dashboard below.
Other Useful Features:
I’m going to round off this list with a handful of other useful features to be found in the DeepCrawl platform.
16. Custom Scripts
DeepCrawl allows you to specify custom scripts in the crawl setup so you can remove iframes, extract onclick elements and performance timings. The latter of these three use cases allows you to extract a range of page speed metrics for every page in the crawl.
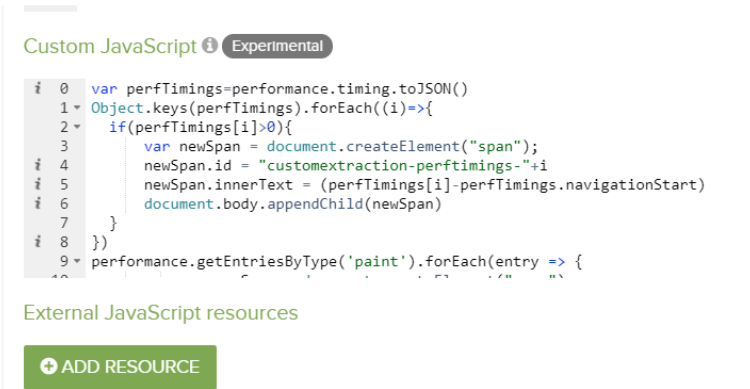
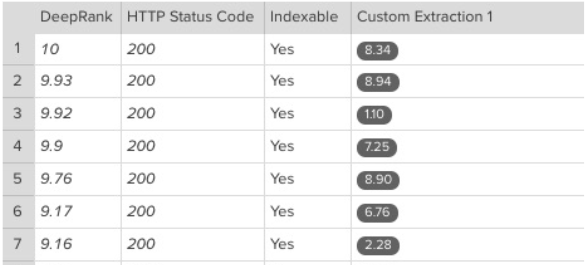
To set this up, simply add the following script found here in advanced settings and set up the custom extractions to extract the performance timings you’re interested in, including: fetchStart, requestStart, responseStart, responseEnd, first-paint, first-contentful-paint, domInteractive, domContentLoadedEventEnd, domComplete and loadEventEnd. All of these extraction rules are detailed in this blog post on performance timings.
17. Health check
Another powerful but little known part of the platform is the health check option available on the page-level reports which can provide you with a number of insights about the technical health of the page in question.
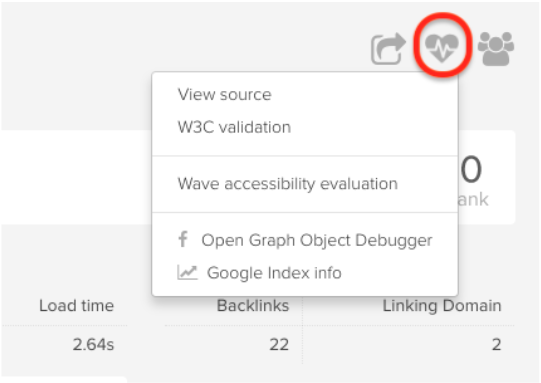
Clicking on health check opens up a number of options including:
- Viewing the page’s source code
- Running the page through W3C validation to check for errors in the page’s markup
- Using Wave to identify issues with a page’s accessibility
- Inspecting open graph information in the Open Graph Object Debugger
- Checking the page exists in Google’s index
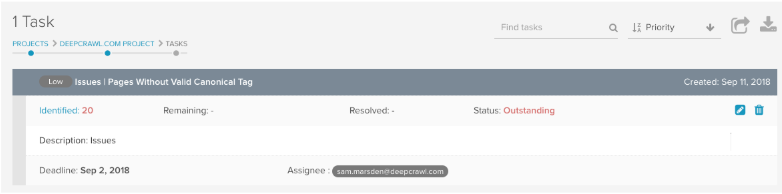
18. Task management
The Task Management feature is available across all DeepCrawl reporting and allows you to communicate issues with others. I’ve found this feature to be particularly useful in communicating specific issues with developers as it allows me to send an email with a link to the report along with a full description, the issue severity and deadline. All of the issues can be seen together in the tasks overview page so you can keep on top of them.
19. User roles
One addition which is particularly useful for agencies and anyone who needs to give DeepCrawl access to a lot of different people is User Roles. User roles allows you to set different levels of access for users to limit the chance that the crawls you have carefully crafted are modified or deleted.
Access is split between:
- Admins who have full control over the account.
- Editors who have control over day-to-day crawling management, but not any of the account settings.
- Viewers who are only able to access to crawls, reports and tasks.
20. API access
DeepCrawl’s API provides programmatic access to their crawler meaning that you can deploy crawl data in your own environment to build custom dashboards, automatically trigger crawls and integrate data into client-facing platforms. You can find more information about the DeepCrawl API with their extensive documentation.
DeepCrawl remains one of the primary SEO tools. With it’s recently released features it also maintains its position at the cutting edge of online marketing innovation. As with all tools and in order to truly benefit from its many tested and new functions an experienced SEO hand is required.
Using DeepCrawl can be and often is a major step towards SERP dominance, even in very competitive niches. That ultimate objective is best achieved with the aid and unparalleled experience of an outside consultant.
Someone unburdened with past development challenge, willing to challenge established solutions and someone who at the same time can bring comparative experience to the table from their past engagements working on similar sites.
Explore DeepCrawl for Yourself
The above points are just some of the reasons why DeepCrawl is such a powerful companion for search marketers, but don’t take our word for it. Try out DeepCrawl for yourself. We have a flexible range of packages tailored to suit your needs.