
Canonicalタグがあらゆるサイト構造に欠かせない理由
Canonicalタグを使うことでGoogleやその他の検索エンジンにどのURLをインデックスさせたいか伝えることができます。
同じページに異なるバージョンが存在する場合、重複コンテンツが発生することを防ぐことができます。例:同じページのオリジナル版と印刷用、セッションID、同じ商品の色違いの商品ページなど
正規化URLとは?
正規化URLは、そのコンテンツの主要なバージョンです。 このURLがまさにGoogleの検索結果に表示されるべきURLということになります。
サイトの正規化URLのセットは、それらに一貫性があることを確実にするルールを設定することで作成できます。例えば、正規化URLが常にスラッシュ(トレイリングスラッシュ)で終わる、または正規化URLにURLパラメータが含まれないといったものです。
正規化されたURLとは?
正規化された(正規化済の)URLは、canonicalタグを含むページのことを指し、そのタグ内に異なるURLが入っている状態のページのことです。
ページ上のcanonicalタグに異なるURLを含めることで、GoogleにページのURLの代わりに正規化URLをインデックスするように指示することができます。
正規化されたURLで収集されるオーソリティシグナルが、正規化URLを優先するように機能します。
canonicalタグを追加する位置と方法
以下のタグを正規化したいページに追加してください。
<link rel=”canonical” href=”http://www.example.com/a-different-page” />
または、HTTPヘッダーに追加することもできます。
Link: <http://www.example.com/a-different-page>; rel=”canonical”
canonicalタグを追加するルール
canonicalタグが機能するには、以下のように、適切にかつ一貫性を持って利用される必要があります。
-
フルドメインを含む絶対URLを使う
-
URLの最後にスラッシュを使うか使わないか、一貫したルールを用いる
-
大文字と小文字を混同しない:例) 大文字を常に使うか、全く使わない
- Googleウェブマスターツールを使ってGoogleがパラメーターを扱う方法を指定し、固有のコンテンツを返さないパラメーターを除外する。正規化URLから同じパラメーターを除外する。
-
文字コード (&など)に一貫性を持たせるか、全く使わない
これらと301リダイレクトの違いは?
canonicalタグは検索エンジンにのみ検出され、ユーザーはそのURLに留まることになります。一方、301はユーザーと検索エンジンをリダイレクトします。
リダイレクトされたURLはアナリティクスには蓄積されませんが、正規化されたURLはトラックされます。
もしユーザーがURLにアクセスできるようにしたい場合、canonicalタグを使ってください。
注意すべき問題
検索エンジンは以下のような場合にはcanonicalタグを無視してしまいます。
正規化URLと正規化されたURLの間でコンテンツが異なる場合:
Googleは正規化URLと正規化済みURLでコンテンツが異なる場合には、canonicalタグを無視してしまうかもしれません。
canonicalタグのないページ:
重複を避けるため、正規化ページを含むすべてのページにcanonicalタグが設置されている必要があります。
間違ったURLへの正規化:
正規化URLが正規化されたURLとあまり類似していない場合、Googleはおそらくそれを無視します。
複数のcanonicalタグ:
同じページ上のcanonicalタグが異なる場合、Googleはそのどちらも無視します。
正規化ループ:
正規化が解除されたページへの正規化
リンクされていない正規化ページ:
ほとんどの正規化URLは、サイトの重要な部分であるため、少なくとも一度はサイト内部でリンクされています。
正規化URLが直接リンクされていない場合、正規化URLが間違っている可能性があります。
正規化URLのリダイレクト:
正規化URLが他のURLにリダイレクトする場合、それは本当の正規化URLではありません。
壊れた正規化URL:
正規化URLが有効なURLではない場合、Googleはそれを無視すると思われますが、これはクロールの効率性を阻害する時間の浪費に他なりません。
空のcanonicalタグ:
URLを含まないcanonicalタグ
canonicalタグをモバイル向けに使う
別のURLでモバイルサイトがある場合、Googleはそのモバイルサイトをデスクトップサイトに正規化してalternate属性を補完することを推奨しています。
ページネーションのためのcanonicalタグ
すべてのページでページネーションを実装(一般的には多くのページに分割される記事に用いられる)している場合、Googleはすべてのページ分割された部分を、 全体のバージョンに正規化することを推奨しています。
DeepCrawlを使ってcanonicalタグをトラッキングする
DeepCrawlの提供する3つのcanonicalタグに関するレポートを使って、全ての正規化されたページ、canonicalタグのないページ、リンクされていない正規化ページを見つける事ができます。
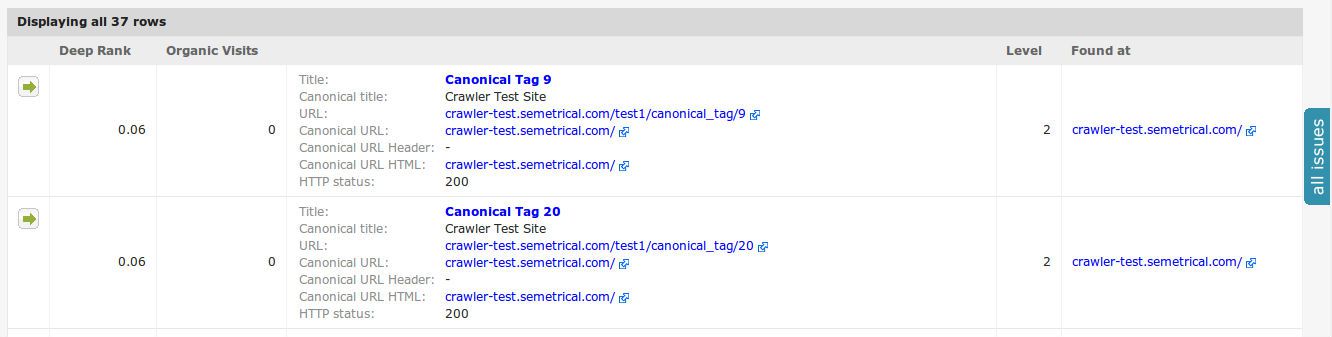
1. 正規化されたページを見つける
Tこのレポートはcanonicalタグで指定された正規化URLとは異なるURLを、HTMLかHTTPヘッダーのいずれかに持つ全てのページを検出します。
インデックス > 正規化されているページへと進んでください。
ここで全ての正規化されたページのリストに加え、それらの場所、正規化URLなどの詳細を確認できます。
2.canonicalタグのないページを検出する
検証 > canonicalタグのないページへと進んでください。
ここでは、canonicalタグのないページを一覧で確認することができます。

3.リンクされていない正規化ページを見つける
検証 > リンクされていない正規化ページへと進んでください。
ここではリンクされていないcanonicalタグで見つかった全てのページをリストで確認することができます。

DeepCrawlは常にあらゆる正規化URLに従ってクロールするので、どこかが壊れている場合には、これらのページはエラーレポートで検出されることになります。

