JavaScriptフレームワークを活用したシングルページアプリケーション(SPA)は、その拡張性とネイティブのようなUXから、広く使われるようになってきています。一方で、ユーザビリティの高いその他のCMSと比べても、検索エンジンによるサイトの認識や、さらにはオーガニック検索経由のトラフィックに多大な影響を与えるクロールの問題が発生するリスクが最も高いと言えます。
この記事では、SPAでよくあるクロール上の問題とその解決方法をご説明します。
1. 個別のURLを持たないページがある
検索エンジンによってページが検出および評価されるには、ページに個別のURLが必要です。SPAでは固有のURLはデフォルトで付与されず、以下の例のようにクロール可能なURLではなくフラグメント識別子を使用してページが生成されることがあります。
例:
・クロール不可のフラグメント識別子: example.com/#interesting-information
・クロール可能なURL: example.com/interesting-information
こうしたページをインデックスさせるために、サイトの設定を正しく行い、各ページにクロール可能なURLを設定しておくようにしましょう。
なぜこれが問題なのか?
検索エンジンはフラグメント識別子を無視し、個別のURLとしてクロールしません。そのため、検索エンジンが検出しておらずインデックスできない情報が大量に発生することになります。
検索エンジンがインデックスしてくれないと、希望するキーワードでランキング掲載されず、オーガニック検索でのビジビリティを十分に得ることができません。
解決方法
History APIや個別URLを使用しながら、そしてさまざまな情報の読み込みをフラグメント識別子に依存しないよう注意しつつ、確実にSPAがページ毎に個別のURLを生成するよう設定しておくようにしましょう。
2. サイト全体でクライアントサイドレンダリングが行われている
SPAの良いところは、クロールに関して言えば欠点にもなります。
SPAでは、デフォルトでクライアントサイドレンダリング(CSR)が行われることが非常に多いです。これは、サーバー上ではなくブラウザ上でサイトが完全に読み込まれることを意味しています。CSRのサイトではページに関する情報の読み込みをすべてJavaScriptに依存しているため、最初に表示されるソースコードにはサイトに関する情報がほとんどありません。
情報がブラウザに届いた段階でアクセスできるのでユーザーにとっては特に問題とはなりません。
しかし、検索エンジンはサイトのインデックスをいくつかの段階に分けて行うため、検索エンジンのクロールやレンダリング、インデックスという点では問題が発生する可能性があります。
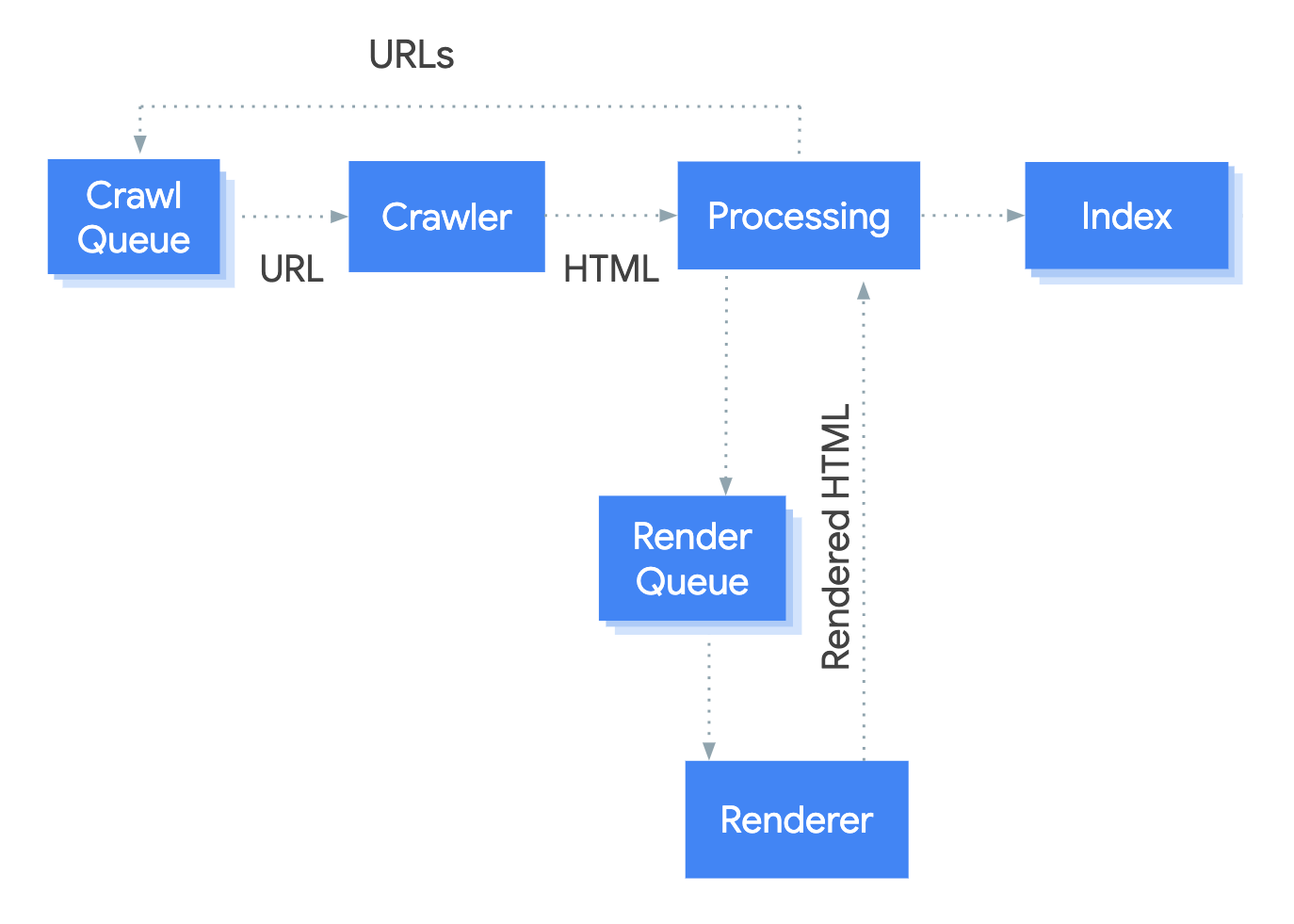 CSRではサイト上のほぼすべての情報のレンダリングが必要となるため、検索エンジンがインデックスの初期段階でサイトをクロールした時にはサイトに関する情報はほぼ取得できません。最初のクロールでは新しいURLがほんの少しだけ、あるいは全く検出されないということもあります。
CSRではサイト上のほぼすべての情報のレンダリングが必要となるため、検索エンジンがインデックスの初期段階でサイトをクロールした時にはサイトに関する情報はほぼ取得できません。最初のクロールでは新しいURLがほんの少しだけ、あるいは全く検出されないということもあります。
サイトがレンダリングされるインデックスの2段階目になってはじめて、検索エンジンがサイトをよく認識できるようになり、また多くのURLを検出するようになります。これは、内部リンクを含む各ページのHTML全体を返し、サーバーに追加のリクエストを行なって各URLに関連する情報を即座に返すサーバーサイドレンダリング(SSR)とは全く異なるシステムであることが分かります。
CSRの問題点
まず、JavaScriptをレンダリングできる速度は検索エンジンによって異なるため、(ユーザーの検索エンジンに応じて)自社サイトへのリーチ数や頻度が制限されてしまいます。最初のHTMLで送信される情報が極めて少ないため、検索エンジンによってはサイトを適切に読み込むことができない可能性があります。
レンダリングが可能な検索エンジンは、単にページのHTMLのみをクロールする検索エンジンに比べて、JavaScriptのレンダリングに多くのリソースが必要です。そのため、インデックスのレンダリング段階に依存するCSRはサイトパフォーマンスにとって大きな制約になる可能性があります。これはサイト全体の情報のレンダリングという大量のタスクを検索エンジンに求めることになるからです。
レンダリングには非常に多くのリソースが必要なため、各ページはレンダリング待ちのステータスとなります。この結果、検出されるページが減り、検出速度も遅くなります。要するに、これは検索エンジンによるサイトのインデックスとサイトの認識の両方に影響を与えて、結果としてランキングにも影響を与えます。
解決方法
検索エンジンがサイトをクロールおよび認識しやすくなるようSPAを正確に設定するにはいくつかの方法があります。
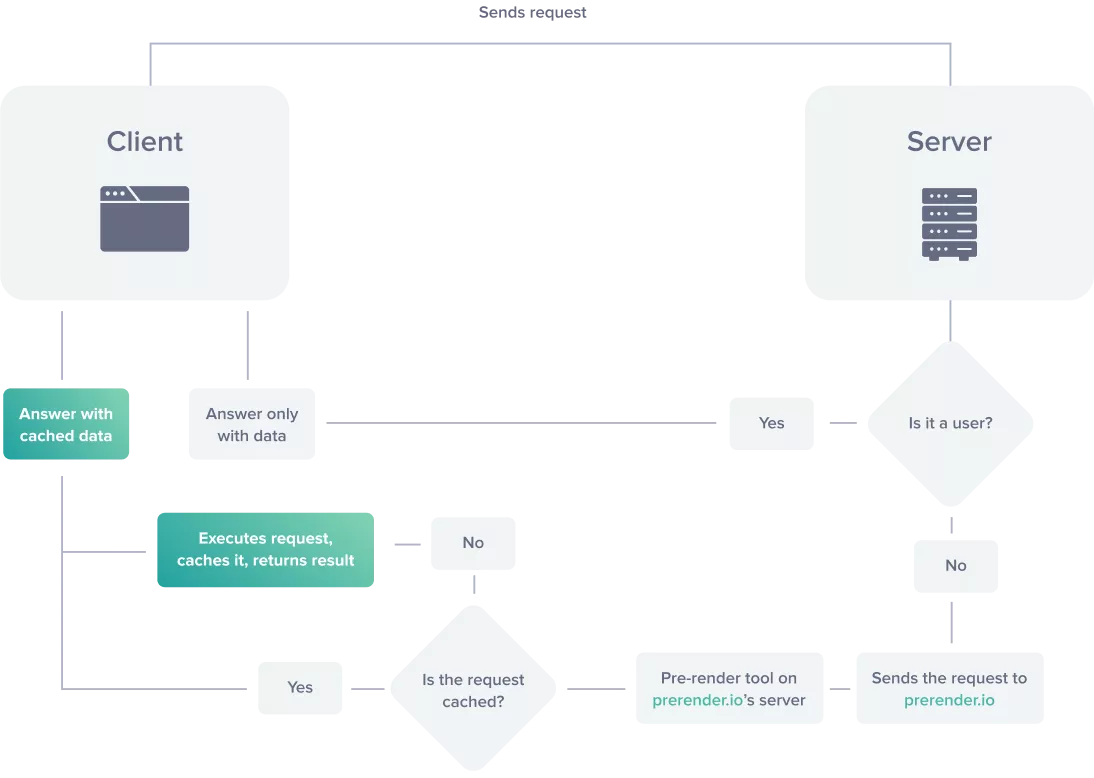
- サーバーサイドレンダリング(SSR): 新しいURLがクロールされるたびにサーバーへリクエストが送信される。サーバーは関連するHTMLを返し、検索エンジンがクロールやレンダリングを行う。Angular Universalのような一部のJSフレームワークにはデフォルトでSSRのオプションがある。
- ダイナミックレンダリング:ユーザーエージェントに基づいてユーザーや検索エンジンクローラーからリクエストかをサーバーで切り分ける。ユーザーに対してはブラウザでレンダリングされたCSR版のサイトを返す。検索エンジンクローラーと判別された場合は事前レンダリングされたHTMLとJSを返して、サイト内容の把握においてインデックスのレンダリング段階に大きく依存しないようにする。
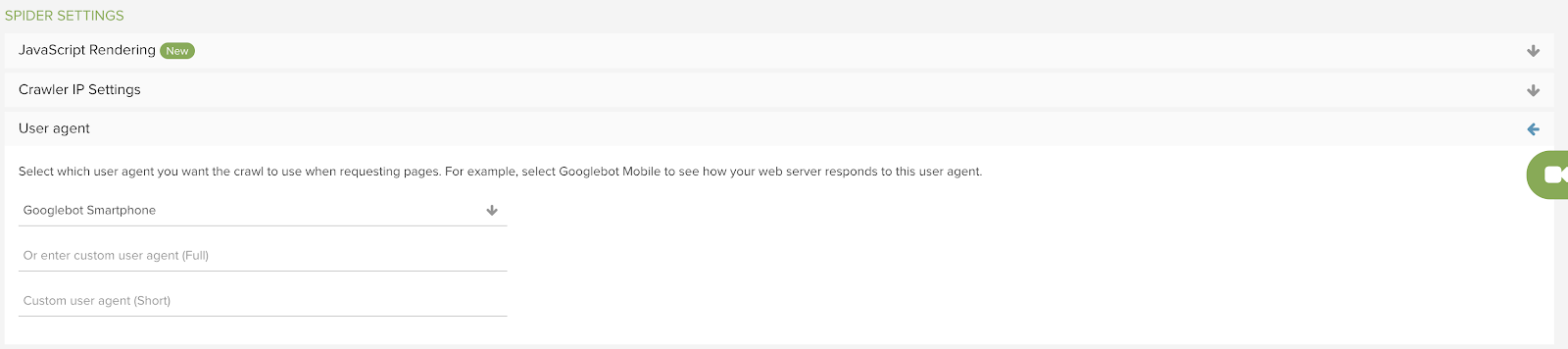
3. ダイナミックレンダリングの設定による特定のユーザーエージェントの妨害
SPAでダイナミックレンダリングを採用し、検索エンジンのクローラーに対してはは事前レンダリングされたHTMLとJSを、ユーザーに対してはクライアントサイドレンダリングを行なったサイトを表示するようにしているのであれば、オーガニック検索のための設定が十分に行われているとは言えません。
ダイナミックレンダリングの設定でサイトにアクセスさせたいすべてのクローラーが許可されていることを確認しておくことは重要です。この設定ができていなければ、検索エンジンがサイトを正しく認識できなくなってしまう可能性があります。
問題点
事前レンダリングされたHTMLが特定の検索エンジンのクローラーに提供されないと、必然的に内容の限られたCSR版サイトが提供されることになります。この場合もまたレンダリングに大幅に依存することになり、その検索エンジンでCSRサイトと同様の問題が発生することになります。
これは、事前レンダリングされたHTMLをどのユーザーエージェントに提供するか識別するための設定がサーバーで正しく行われていない場合、複数の検索エンジンへのトラフィックを制限してしまう可能性があるということです。
解決方法
ダイナミックレンダリングにおいて事前レンダリングされたHTMLを受け取る設定が適切に行われていないユーザーエージェントを把握するには、ログファイルを確認することがとても重要です。
サイトの事前レンダリングに使用しているプラットフォームによっては、この機能がパッケージに含まれていることがよくあります。あまり多くのリクエストを生成していないサイトをクロールするユーザーエージェントが特定されているのであれば、それらのユーザーエージェントに対して事前レンダリングされたHTMLを提供するような設定となっていない可能性があります。
こうして問題点に気づいたら、都度設定の見直しを行って解決していくことが重要です。
4. クロールにJavaScriptが必要なケース
たとえSPAのほとんどの部分でサーバーサイドレンダリングが実行され、ダイナミックレンダリングが設定されていても、検索エンジンのJavaScriptレンダリングが必要となる箇所が依然として残っている可能性があります。これは、新規URLを生成するサードパーティ製JavaScriptや、サーバーでレンダリングする設定がされていない箇所などが原因となっているかもしれません。
これは、サイト全体でクライアントサイドレンダリングを行う場合と比べればそこまで問題ではありませんが、より多くのリソースを必要とする処理であることに変わりはないため、依然として問題が起こることがあります。
問題点
サイトのクロールと認識を検索エンジンが可能な限り簡単にできるようにすることが私たちの目指すところです。(JavaScriptレンダリングに対応していない検索エンジンなどが)アクセスできない箇所があったり、リソースのかかるレンダリング処理のためにアクセスしづらい箇所があると、検索エンジンによるサイトの検出やインデックスが難しくなり検索上位表示のランキングに掲載される可能性を潜在的に下げることになります。
例えば、JavaScriptを使用しないとリンクが検出されない場合、レンダリング待ちやソースコードのレンダリング、検出、クロールおよび認識に必要なリソース規模により、検索エンジンがサイトの各ページを深く理解するのに長い時間がかかってしまいます。
同様に、この(JS使用でのみ検出可能なリンクの)コンテンツが変更されると、同じ理由から検索エンジンによる変更の検出に時間がかかります。つまり、ビジビリティ改善を目的として行うすばらしいサイトの変更も、長い時間検出されず、ランキングで考慮されない可能性があるいうことです。
解決方法
ページのHTMLとレンダリングされたDOMを比較して、最初のHTMLには存在しないリンクをJavaScriptが生成しているかどうか確認することで、サイト上で問題となり得る箇所を特定することができます。定期的なクロールとJavaScriptレンダリングを有効化したクロールの比較も、サイト上でこの問題が起きているかの確認に役立ちます。
クロールの問題を検出する方法
JavaScriptレンダリングを使用せずにサイトをクロールして返されるURLが1つなどごくわずかな量だった場合、サイトがCSRに依存している可能性が高いです。この際、セキュリティ設定や内部リンクのnofollow、robots.txtファイルでのブロック、認証やパスワードで保護されたサイトなど、クロールを制限するその他様々可能性を排除した上で検証ようにしましょう。(CSRが要因であることを確実に判断するため)
JavaScriptを有効化してサイトを再クロールした時にサイトが返すURLが増えた場合は、サイトがクライアントサイドレンダリングに依存していると断言できます。
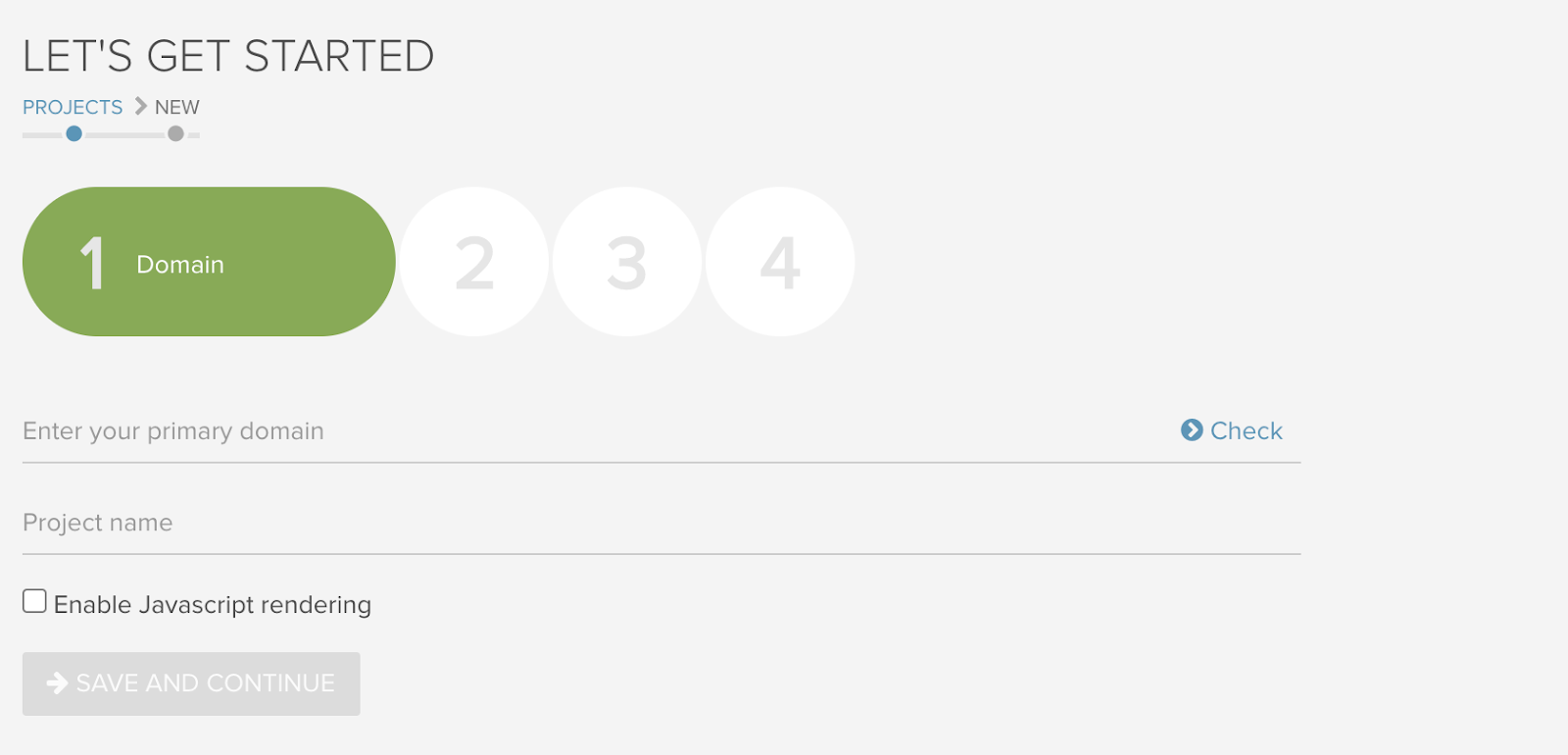
ダイナミックレンダリングを使用してサイトをクロールする場合は、サイトのCSR版ではなくサイトのHTMLをすべて返すよう定義済みのユーザーエージェントを使用することが重要です。これは一般的なユーザーエージェントの場合もあれば、カスタムのユーザーエージェントの場合もあります。どちらの場合も、以下DeepCrawlのキャプチャで示しているようなクロール設定で選択する必要があります。