
アップデート:
2019年9月1日、Googleはnoindexディレクティブの使用を含むrobots.txt内でサポート外かつ未公開のルールを処理するすべてのコードへのサポートを終了します。
Robots.txtとNoindexの役割
Googleが公式に文書化したことはなかったものの、robots.txtファイルへのnoindexディレクティブの追加は最初にMatt Cutts氏が言及してから10年以上に渡ってサポート対象の機能でした。DeepCrawlでも2011年からサポートを行なっています。
許可されていないページとは異なり、noindexされたページはインデックスされず、検索結果に表示されません。robots.txtファイルにnoindexとdisallowの両方を追加すると、noindexディレクティブがページの検索結果への表示を防ぎ、disallowがページのクロールを妨げるため、クロール効率の最適化に役立ちました。
- Disallow: /example-page-1/
- Disallow: /example-page-2/
- Noindex: /example-page-1/
- Noindex: /example-page-2/
Googleは、2019年7月1日にロボット排除プロトコル(Robots Exclusion Protocol: REP)が25年に及びインターネットにおいて標準であり続け、現在はオープンソースになりつつあることを公式に発表しました。Googleはこれに続いて、7月2日にrocots.txtファイル内のサポートされていないルールに関する公式の文書を作成しています。
この発表の趣旨は、2019年7月1日からrobots.txt内のnoindexの使用がGoogleのサポート外になるというものです。
GoogleのGary Illyes氏はrobots.txtファイル内のnoindexの使用に関する調査を行ない、「非常に多くのサイトが自身を検索結果に表示させないようにしていた」と報告しました。さらにGary氏は今回のアップデートについて、「より良いビジネス環境・慣行に繋がるもので、正しく使用した人には効率性が担保されるでしょう。」と強調しました。
As promised a few weeks ago, i ran the analysis about noindex in robotstxt. The number of sites that were hurting themselves very high. I honestly believe that this is for the better for the Ecosystem & those who used it correctly will find better ways to achieve the same thing.
https://t.co/LvdhsN2pIE
— Gary “鯨理” Illyes (@methode) July 2, 2019
noindexディレクティブの代替案
現在robots.txtファイル内のnoindexディレクティブに依存している場合であっても、Googleの公式ブログ記事に挙げられている通り、いくつか代替案があります。
- meta robots noindexタグ: これを使うと最も効率良くURLをインデックスさせずにクロールさせることができます。これらのタグはHTTPレスポンスヘッダーとHTMLの両方でサポートされており、ページ自体にmeta robots noindexタグを追加するだけで実装できます。
- HTTPステータスコード404と410: これらのステータスコードを使うと検索エンジンに対してページがもはや存在しないことを通知するため、ページがクロールされるとインデックスから削除されます。
- パスワード保護: ページにログインのプロセスを設けてGoogleによるアクセスを防ぐことで、たいていのページはインデックスから削除されます。
- Robots.txt内のDisallow: 検索エンジンはクロールできるページのみインデックスするため、ページのクロールをブロックすると一般的にはインデックスされません。他のページからそのページへのリンクによってインデックスされる可能性がありますが、Google検索結果でのビジビリティは下がります。
- サーチコンソールのURL削除ツール: GoogleサーチコンソールのURL削除ツールを使うと、すばやく簡単にGoogle検索結果からURLを一時的に削除できます。
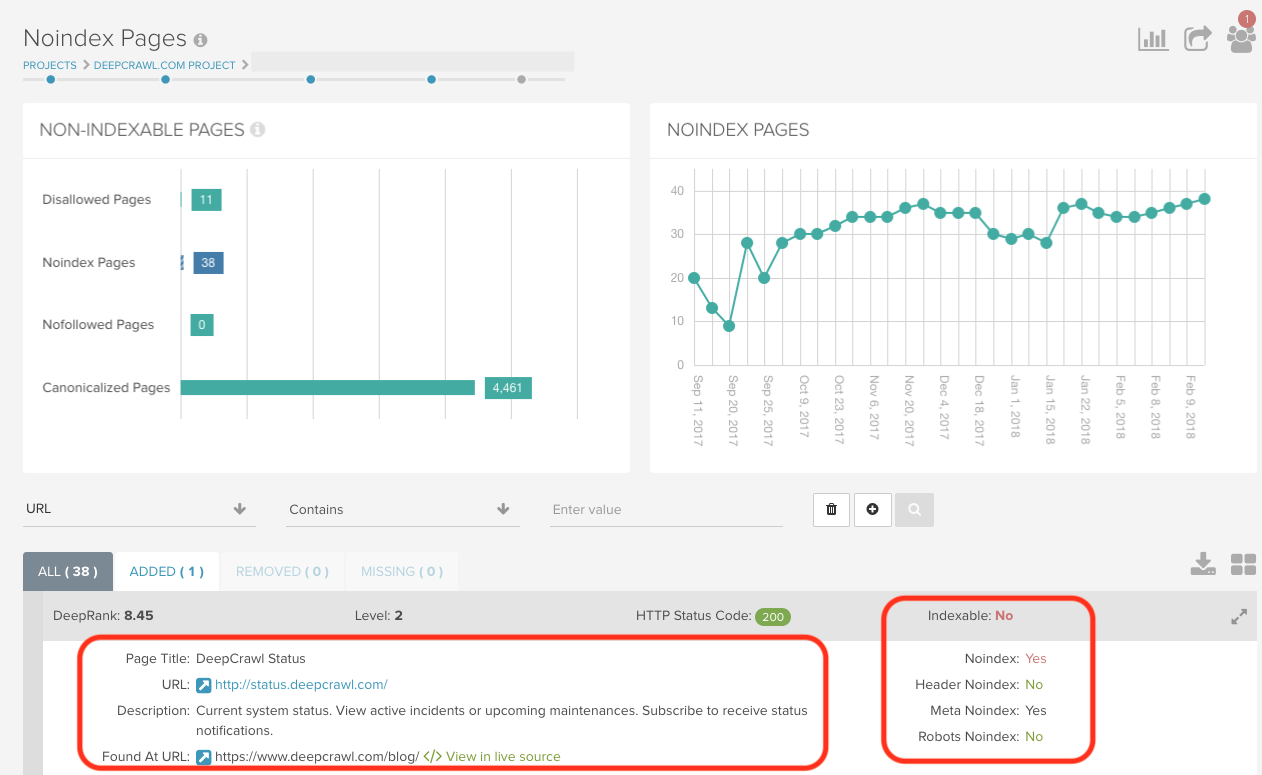
robots.txt内noindexページの特定とモニタリング
2019年9月1日にrobots.txt内noindexディレクティブのサポートが終了してしまう前に、DeepCrawlのNoindexページレポート(インデックス>インデックス不可ページ>Noindexページ)を使うと、現在noindexされたページとその原因を確認できます。noindexページのリストでは、どこでページがnoindexとされたか(ヘッダー、metaタグもしくはrobots.txt)を参照できます。
Googleサーチコンソールのテストツールを使い、他のrobots.txtディレクティブと同様にnoindexディレクティブの動作をテストすることもできます。
robots.txtへのその他変更点
このアップデートは、robots.txtプロトコルに対する数多くの変更点のうちの1つであり、今後のインターネット標準になっていくことでしょう。Googleはこれら変更点の詳細をGoogleディベロッパーブログのrobots.txtの仕様変更に関する文書で説明しています。
詳細な情報
この記事でサイトのクロールを管理するrobots.txtのnoindexプロトコルのアップデートを知っていただけましたら幸いです。
このトピックに関して、DeepCrawlではURLレベルのrobotsディレクティブとRobots.txt.に関するガイドをテクニカルSEOライブラリで公開していますので、ぜひご覧ください。

