
JavaScriptとSEOは長い間敵対関係にあり、全てのSEO担当者にとってGoogleがいつもJavaScriptのコンテンツのインデックスに苦労してきたことは既知の事実です。 一般的にJavaScriptはページやウィジェットの一部分でしかないために無視することができます。GooglebotはそのJSの周りにあるコンテンツを理解し、そのページの意味を把握してインデックスできるのです。

しかし、インデックスしたいと思っているページ全体やその大部分がレンダリングされたJSにより構成されていたらどうでしょうか?改善されてきているとはいえJSベースのサイトがどんなに素晴らしくてスムーズに機能しようとも、Googleはこのサイトのコンテンツをクロールすることができません。 2014年までは、JSバージョンが提供するような機能をユーザーに提供しながらも検索エンジンにはHTMLバージョンとして提供するフォールバックメソッド(英語)のような手法が提唱されていました。
現在議論されていることをまとめると以下のようになります。
- 歴史的にGoogleはJavaScriptやAJAXを処理できていない。
- Googleはそれが現時点で可能になったと主張している。
- SEO担当者はまだ問題が残っていると認識している。
- >GoogleがJSのレンダリングを劇的に改善したことを示す証拠がある。
Angular JSは、動的なウェブアプリを構築するフレームワークであり、HTMLをベース言語として開発されています。簡単に言うとAngularはロード済のページにHTMLを追加的に実装するためのものであり、これはリンクをクリックしてもページがリロードされず、新しいHTMLを実装する、つまりページを再度読み込む必要がなくなり、サイトがはるかに早く作動し、かつ必要なコーディングがかなり少なくなるために開発者の時間を節約してくれるということを意味しています。
一方で、繰り返しにはなりますがAngularはJavaScriptのフレームワークであるために、SEO担当者にとって扱いが難しいものでもあります。ウェブにある様々な事例を見ても、Angular JSサイト全体のうちホームページだけがインデックスされていたり、全くインデックスされていないような事例が多く存在しています。これはAngular JSがGoogleにより実際に開発されたものであったとしても、です。以下はTransferWise 社のサイトがインデックスされている事例です。
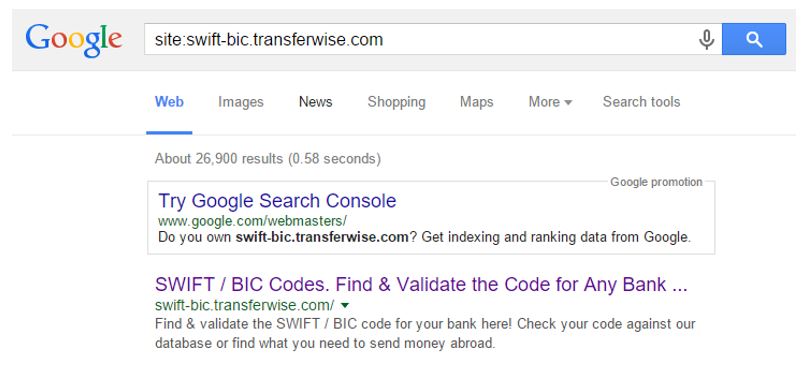
過去を遡ってみると(Angularは2009年にローンチ)、JavaScriptとSEOの関係と同じような経過を辿ってきたことがわかります。
- GoogleがAngularをリリースし、ディベロッパーが喜ぶ
- SEO担当者が絶望する
- プレレンダリングに関してニッチな産業 (companies like io社やBrombone社のような会社)場し、Angular JSのインデックス問題を解決していく
- GoogleのスパイダーがAngular JSをサポートすると発表があり、SEO担当者は安堵する
サーチコンソールはGooglebotがどのようにページを見ているか教えてくれたり、それとユーザーがブラウザで実際に目にするものを比較してくれたりもします。
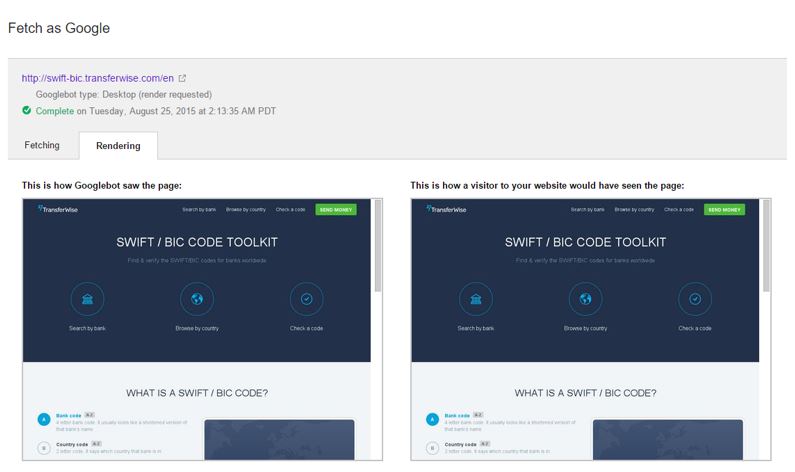
明らかに問題はありません。
Angularで構築されていてインデックスされているサイトを探すのは非常に困難であり、この問題への対処法を求めている人はたくさんいます。DeepCrawlでは以下のように対応しました。
まず最初にすべきこと
まず、Angularがデフォルトで設定している強制ハッシュタグを削除することから始めましょう。
例えば、SEOやUXの観点から言えば、トップレベルドメイン(TLD)を使用してカテゴリページへの動線を作った上で商品やコンテンツのページへ遷移するようにすることをおすすめします。ユーザーがあるページに訪問するときに従う、以下のような最も一般的なパスにURL構造が合致していることが重要となります。
- com/
- com/category/
- com/category/page/
しかしながらデフォルトではAngularはページを以下のように設定しています。
- com
- com/#/category
- com/#/page
私の理解では、ハッシュバンを使うことでAngularにどのHTML要素をJSに追加すべきか伝えることができます。以下のリンクは、この問題を解決する上で非常に役立つガイド(英語)です。https://scotch.io/quick-tips/pretty-urls-in-angularjs-removing-the-hashtag.
また、DeepCrawlは相対URLについての以下のような問題にも直面しました。
“<a href=”en/countries/united-kingdom”>…</a>”となっているべきところに対して、<a href=”/en/countries/united-kingdom”>…</a>のように記述する。ユーザーにとっては特に問題がないように見えるかもしれませんが、これをボットがクロールする際には、既存のURLがどんなものであっても、そのリンクの文字列が元々のURLに追加されてしまいます。そのため、例えば、メインナビゲーションにあるホームページリンクのURLに”/en”が余分に追加されてしまいます。これはサイトのクロールにより、ますます多くのサブフォルダにURLリストが無限に生成されてしまうことを意味しています。
最後だが比較的大きな問題
最後に、まだ対処すべき大きな問題が残っています。それはGoogleがAngularの処理に手を焼いていることです。最初にサイトを構築し、きれいなURLを作成した上でGoogleの処理を待っているときは、どんなSEO担当者であっても、Googleがどれほどはやくサイトをクロールできるか知っています。もしサイトをサーチコンソールに提出してから数日経過するようであれば、問題が発生していると思ったほうが良いことになります。
我々は、包括的なサイトマップを登録し、かつ何かの一助になればという思いで個別のサイトマップ形式をサーチコンソールに送信しようと試みました。Googleは25,000ページのうち200程度をなんとか検出できたものの、それ以上はできませんでした。再送信してみても、状況は変わりませんでした。
実際に行った対策
DeepCrawlはプリレンダリングを行ないました。幸運にも当社には内部に専門知識が蓄積されており、Phantom JSを使うことでこの問題を解決できました。この方法により、サーバーサイドでAngularをプリレンダリングし、ユーザーに対してはAngularバージョンに直接表示しつつGoogleにはこのバージョンを処理させることが可能になりました。
サーバーがクローラーのリクエストを処理できない場合、これは検索エンジンが検出するサーバーエラーを増加させてしまいます。解決法の1つは、サーバーサイドでプリレンダリングを行うことにより、クローラーがサーバーに到達した際にページがすでにレンダリングされている状況を作り出すことです。しかし、我々の読み込み用サーバーを使えば読み込みが可能になるため、これをそこまで懸念しておりません。しかし、我々の読み込み用サーバーが負荷を管理するため、これをそこまで懸念する必要はありません。
代替案としては、フラグメントとしてメタタグをページに実装する方法があります。 この場合、Googleは次のようなURLパラメーターを使用します:?_escaped_fragment_.
このパラメーターはプリレンダリングされたバージョンをフェッチするためにGooglebotをサーバーへと誘導します。これは上記の問題を解決するための方法であるとDeepCrawlが判断したものではありませんが、実際の運用においてこうした手法を使うことは多く、実際の運用を止めることなく実行できるという点で優れた手法と言えるでしょう。
Chrome経由でJavaScriptを無効化してページを読み込もうとする場合、以下のような表示となります。
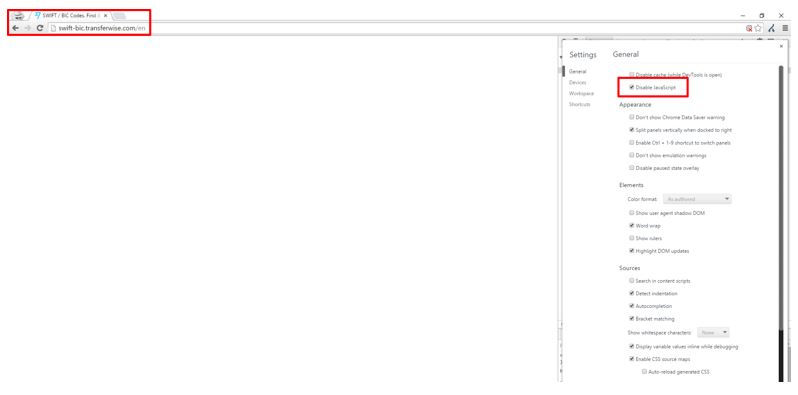
前述の通り、エスケープ処理されたフラグメントのパラメーターと全く同じ処理を行った場合、ページは以下のように読み込まれます。
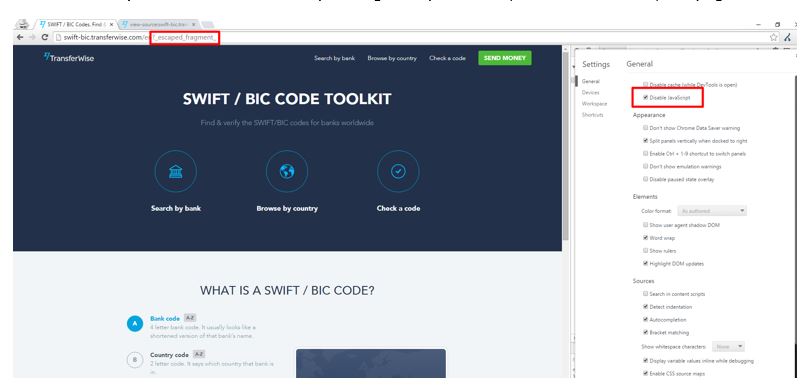
これはすぐに任意のURLを使ってお試しいただける方法です。
まとめると、もしSEOの知識を持っている場合はAngular JSを利用することはでき、必要なことはサイトをクロール可能にするための知識を身につけることだけです。しかし、Googleが将来的にこの方法をサポートしなくなると宣言していること、そしてこれに対してGoogleは静的HTMLとしてしか処理しないことを考慮すると問題ではないということに留意してください。
テストおいては、必ずGooglebotとしてクロールするようにしてください。そうしなければ、多くの場合ホームページでの処理で動きが止まっててしまうからです(この代わりにサーバーがDeepCrawlのボットをGooglebotのように扱うようにしておくことも可能です)。このようにすれば、プリレンダリングしたHTMLがボットにより処理され、全てのリンクがクロール可能となります。
これで、トラフィックの観点から全てが万全になりました。オーガニック検索からのサイト訪問者はゆっくり増加し、サイトが完全にインデックスされるようになると、Angularへの信頼が増して、他の現行プロジェクトにもAngularを利用するようになります。
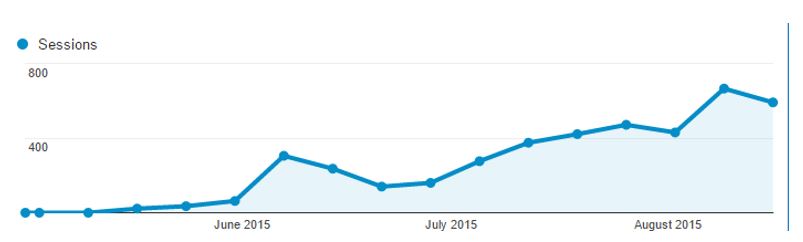
DeepCrawlをGooglebotとして機能するように設定することで、上記のような設定がされているサイトをDeepCrawlでクロールすることも可能です。以下の画像は、プリレンダリングが実行される前の状態を示します。
内部リンクを修正する前:
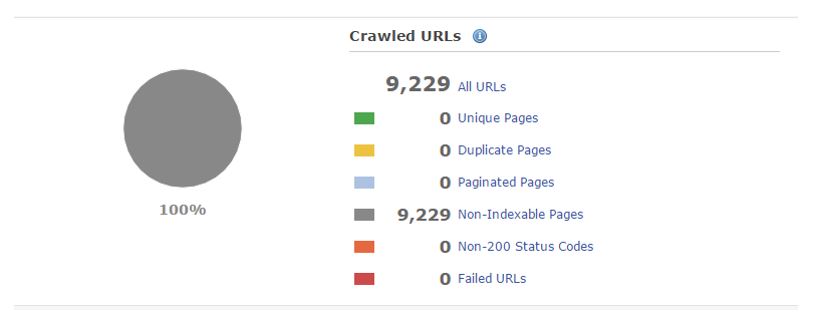
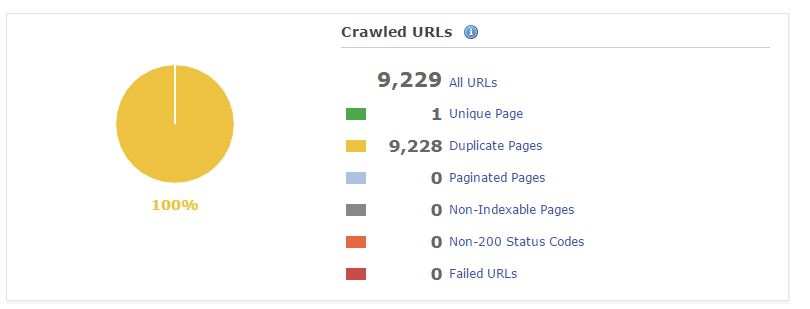
プリレンダリングが実行される前:
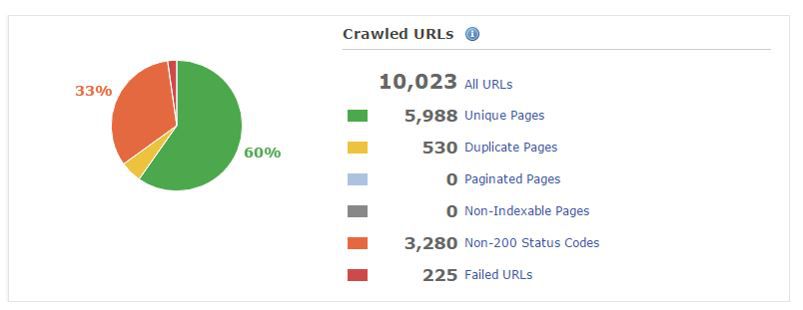
ほぼ全ての修正やプリレンダリングが完了した後:
すぐに実行したい場合は、新しいクロールを設定する際にユーザーエージェントをGooglebotに設定してください。
さらに深く知りたい場合
この記事を読むことで、Angular JSについてより深くご理解いただけたら幸いです。
このトピックについて、HAJAXで構築されたアプリケーションをクロール可能にする方法に関するガイドをお読みいただければさらに深く学んでいただけます。

